

[ad_1]
Picture by Editor
Knowledge visualization performs an necessary position in machine studying.
Knowledge visualization use circumstances in machine studying embrace:
- Hyperparameter tuning
- Mannequin efficiency analysis
- Validating mannequin assumptions
- Discovering outliers
- Choosing a very powerful options
- Figuring out patterns and correlations between options
Visualizations which might be instantly associated to the above key issues in machine studying are referred to as machine studying visualizations.
Creating machine studying visualizations is usually an advanced course of because it requires a variety of code to jot down even in Python. However, because of Python’s open-source Yellowbrick library, even complicated machine studying visualizations could be created with much less code. That library extends the Scikit-learn API and offers high-level features for visible diagnostics that aren’t offered by Scikit-learn.
As we speak, I’ll focus on the next kinds of machine studying visualizations, their use circumstances and Yellowbrick implementation intimately.
Set up
Set up of Yellowbrick could be performed by working one of many following instructions.
- conda package deal installer:
conda set up -c districtdatalabs yellowbrick
Utilizing Yellowbrick
Yellowbrick visualizers have Scikit-learn-like syntax. A visualizer is an object that learns from knowledge to provide a visualization. It’s usually used with a Scikit-learn estimator. To coach a visualizer, we name its match() methodology.
Saving the plot
To avoid wasting a plot created utilizing a Yellowbrick visualizer, we name the present() methodology as follows. It will save the plot as a PNG file on the disk.
visualizer.present(outpath="name_of_the_plot.png")
Utilization
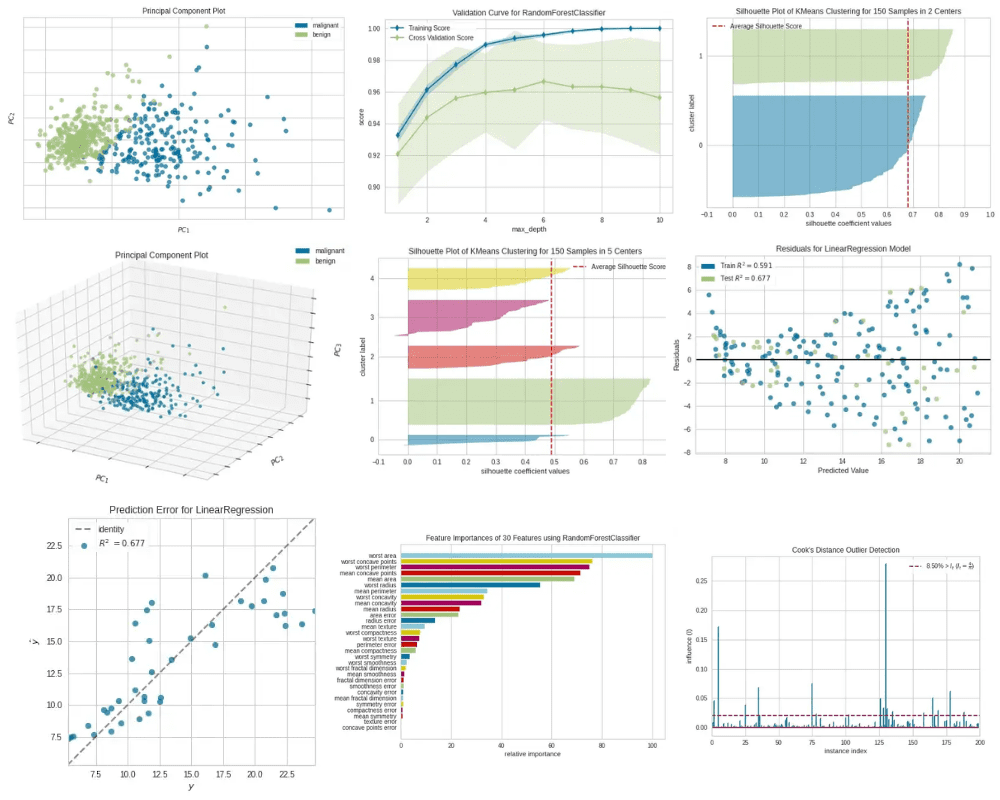
The principal element plot visualizes high-dimensional knowledge in a 2D or 3D scatter plot. Due to this fact, this plot is extraordinarily helpful for figuring out necessary patterns in high-dimensional knowledge.
Yellowbrick implementation
Creating this plot with the standard methodology is complicated and time-consuming. We have to apply PCA to the dataset first after which use the matplotlib library to create the scatter plot.
As a substitute, we are able to use Yellowbrick’s PCA visualizer class to attain the identical performance. It makes use of the principal element evaluation methodology, reduces the dimensionality of the dataset and creates the scatter plot with 2 or 3 strains of code! All we have to do is to specify some key phrase arguments within the PCA() class.
Let’s take an instance to additional perceive this. Right here, we use the breast_cancer dataset (see Citation on the finish) which has 30 options and 569 samples of two lessons (Malignant and Benign). Due to the excessive dimensionality (30 options) within the knowledge, it’s inconceivable to plot the unique knowledge in a 2D or 3D scatter plot until we apply PCA to the dataset.
The next code explains how we are able to make the most of Yellowbrick’s PCA visualizer to create a 2D scatter plot of a 30-dimensional dataset.
Code by Writer

Principal Part Plot — 2D|Picture by Writer
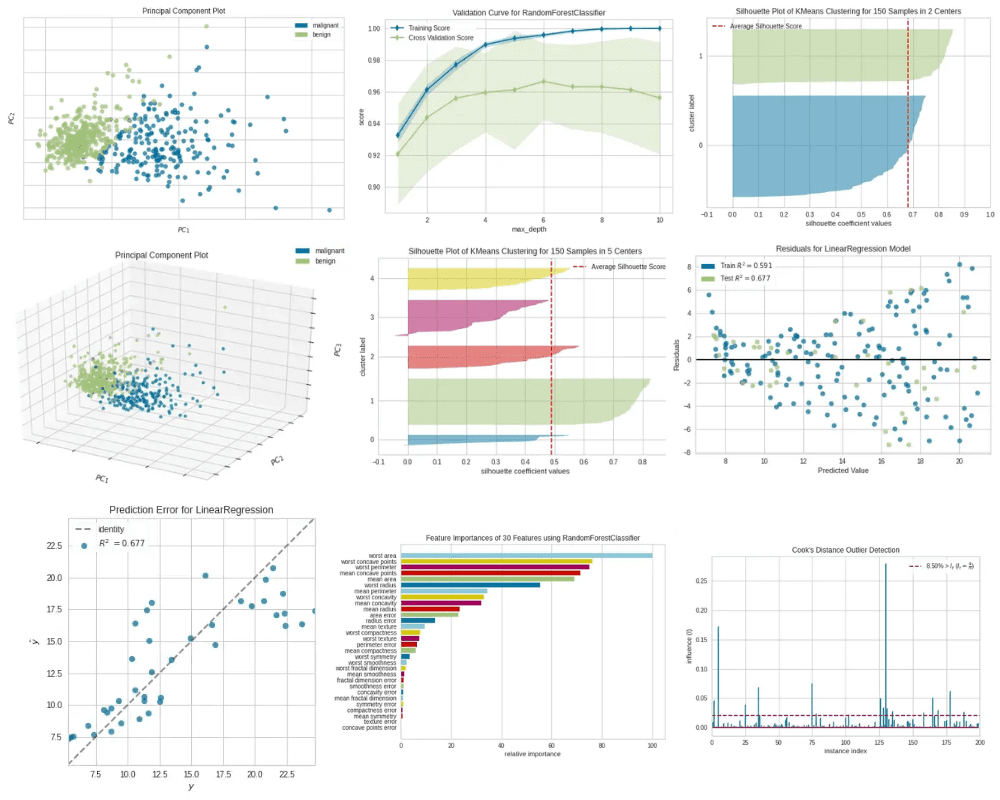
We are able to additionally create a 3D scatter plot by setting projection=3within the PCA() class.
Code by Writer
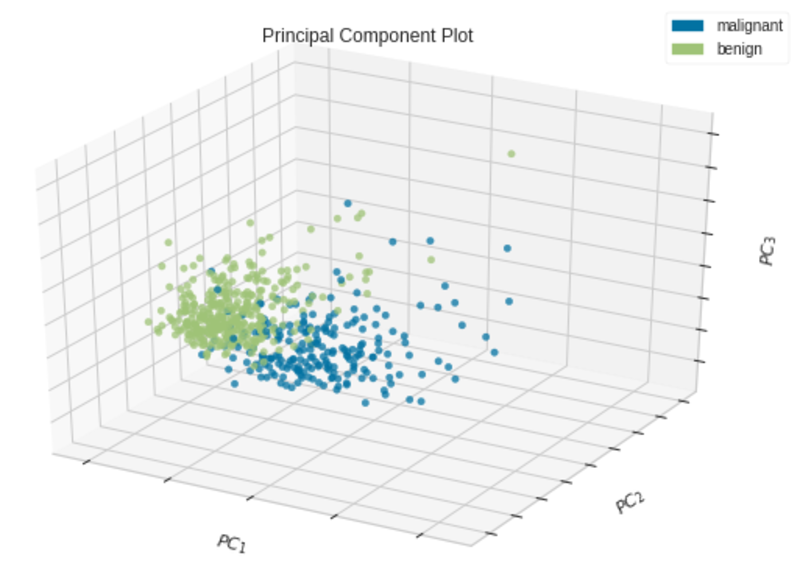
Principal Part Plot — 3D|Picture by Writer
Crucial parameters of the PCA visualizer embrace:
- scale: bool, default
True. This means whether or not the information ought to be scaled or not. We should always scale knowledge earlier than working PCA. Be taught extra about here. - projection: int, default is 2. When
projection=2, a 2D scatter plot is created. Whenprojection=3, a 3D scatter plot is created. - lessons: listing, default
None. This means the category labels for every class in y. The category names would be the labels for the legend.
Utilization
The validation curve plots the affect of a single hyperparameter on the prepare and validation set. By wanting on the curve, we are able to decide the overfitting, underfitting and just-right situations of the mannequin for the desired values of the given hyperparameter. When there are a number of hyperparameters to tune without delay, the validation curve can’t be used. Instated, you need to use grid search or random search.
Yellowbrick implementation
Making a validation curve with the standard methodology is complicated and time-consuming. As a substitute, we are able to use Yellowbrick’s ValidationCurve visualizer.
To plot a validation curve in Yellowbirck, we’ll construct a random forest classifier utilizing the identical breast_cancer dataset (see Citation on the finish). We’ll plot the affect of the max_depth hyperparameter within the random forest mannequin.
The next code explains how we are able to make the most of Yellowbrick’s ValidationCurve visualizer to create a validation curve utilizing the breast_cancer dataset.
Code by Writer
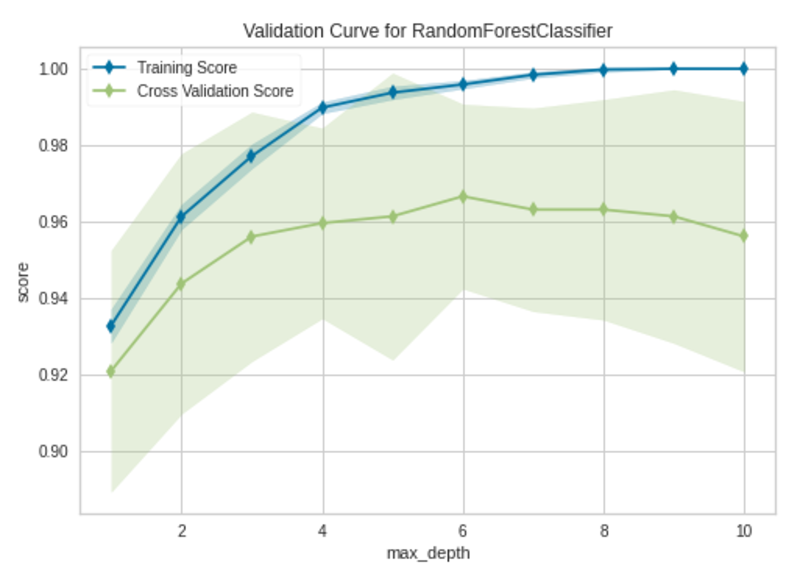
Validation Curve|Picture by Writer
The mannequin begins to overfit after the max_depth worth of 6. When max_depth=6, the mannequin matches the coaching knowledge very nicely and likewise generalizes nicely on new unseen knowledge.
Crucial parameters of the ValidationCurve visualizer embrace:
- estimator: This may be any Scikit-learn ML mannequin comparable to a choice tree, random forest, assist vector machine, and so on.
- param_name: That is the identify of the hyperparameter that we wish to monitor.
- param_range: This contains the doable values for param_name.
- cv: int, defines the variety of folds for the cross-validation.
- scoring: string, accommodates the strategy of scoring of the mannequin. For classification, accuracy is most well-liked.
Utilization
The training curve plots the coaching and validation errors or accuracies in opposition to the variety of epochs or the variety of coaching cases. You could suppose that each studying and validation curves seem the identical, however the variety of iterations is plotted within the studying curve’s x-axis whereas the values of the hyperparameter are plotted within the validation curve’s x-axis.
The makes use of of the training curve embrace:
- The training curve is used to detect underfitting, overfitting and just-right situations of the mannequin.
- The training curve is used to establish gradual convergence, oscillating, oscillating with divergence and correct convergence situations when discovering the optimum studying price of a neural community or ML mannequin.
- The training curve is used to see how a lot our mannequin advantages from including extra coaching knowledge. When used on this approach, the x-axis reveals the variety of coaching cases.
Yellowbrick implementation
Creating the training curve with the standard methodology is complicated and time-consuming. As a substitute, we are able to use Yellowbrick’s LearningCurve visualizer.
To plot a studying curve in Yellowbirck, we’ll construct a assist vector classifier utilizing the identical breast_cancer dataset (see Citation on the finish).
The next code explains how we are able to make the most of Yellowbrick’s LearningCurve visualizer to create a validation curve utilizing the breast_cancer dataset.
Code by Writer
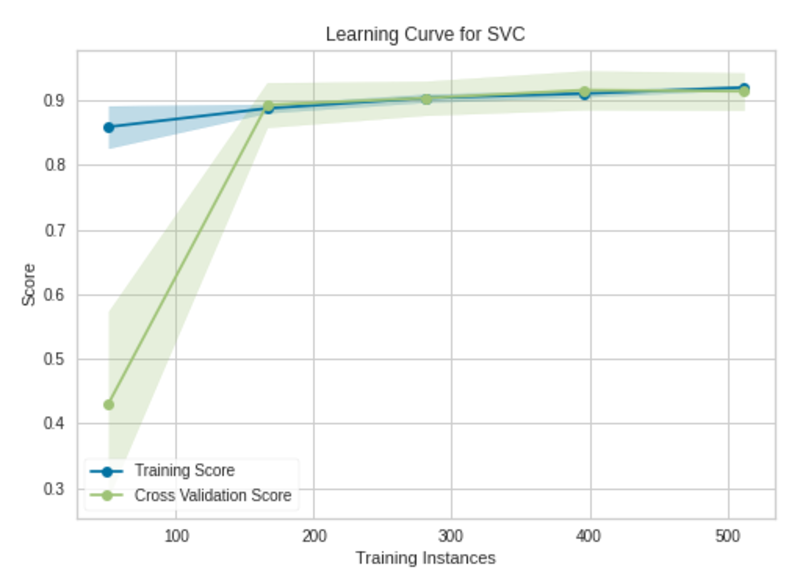
Studying Curve|Picture by Writer
The mannequin won’t profit from including extra coaching cases. The mannequin has already been skilled with 569 coaching cases. The validation accuracy isn’t bettering after 175 coaching cases.
Crucial parameters of the LearningCurve visualizer embrace:
- estimator: This may be any Scikit-learn ML mannequin comparable to a choice tree, random forest, assist vector machine, and so on.
- cv: int, defines the variety of folds for the cross-validation.
- scoring: string, accommodates the strategy of scoring of the mannequin. For classification, accuracy is most well-liked.
Utilization
The Elbow plot is used to pick out the optimum variety of clusters in Ok-Means clustering. The mannequin matches greatest on the level the place the elbow happens within the line chart. The elbow is the purpose of inflection on the chart.
Yellowbrick implementation
Creating the Elbow plot with the standard methodology is complicated and time-consuming. As a substitute, we are able to use Yellowbrick’s KElbowVisualizer.
To plot a studying curve in Yellowbirck, we’ll construct a Ok-Means clustering mannequin utilizing the iris dataset (see Citation on the finish).
The next code explains how we are able to make the most of Yellowbrick’s KElbowVisualizer to create an Elbow plot utilizing the iris dataset.
Code by Writer
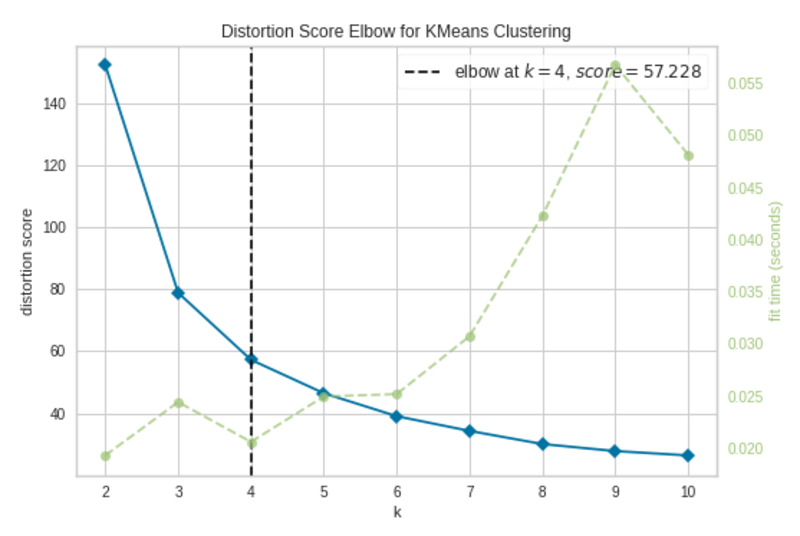
Elbow Plot|Picture by Writer
The elbow happens at okay=4 (annotated with a dashed line). The plot signifies that the optimum variety of clusters for the mannequin is 4. In different phrases, the mannequin is fitted nicely with 4 clusters.
Crucial parameters of the KElbowVisualizer embrace:
- estimator: Ok-Means mannequin occasion
- okay: int or tuple. If an integer, it can compute scores for the clusters within the vary of (2, okay). If a tuple, it can compute scores for the clusters within the given vary, for instance, (3, 11).
Utilization
The silhouette plot is used to pick out the optimum variety of clusters in Ok-Means clustering and likewise to detect cluster imbalance. This plot offers very correct outcomes than the Elbow plot.
Yellowbrick implementation
Creating the silhouette plot with the standard methodology is complicated and time-consuming. As a substitute, we are able to use Yellowbrick’s SilhouetteVisualizer.
To create a silhouette plot in Yellowbirck, we’ll construct a Ok-Means clustering mannequin utilizing the iris dataset (see Citation on the finish).
The next code blocks clarify how we are able to make the most of Yellowbrick’s SilhouetteVisualizer to create silhouette plots utilizing the iris dataset with completely different okay (variety of clusters) values.
okay=2
Code by Writer

Silhouette Plot with 2 Clusters (okay=2)|Picture by Writer
By altering the variety of clusters within the KMeans() class, we are able to execute the above code at completely different occasions to create silhouette plots when okay=3, okay=4 and okay=5.
okay=3
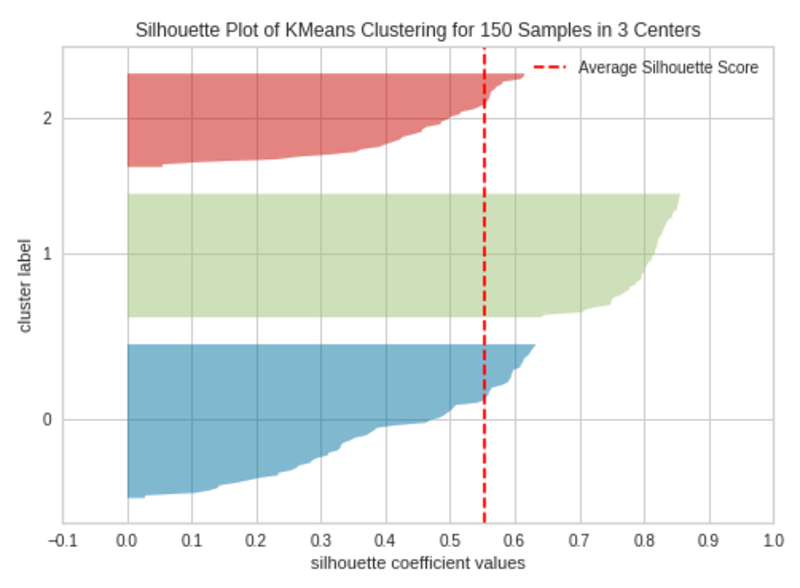
|Silhouette Plot with 3 Clusters (okay=3)|Picture by Writer
okay=4
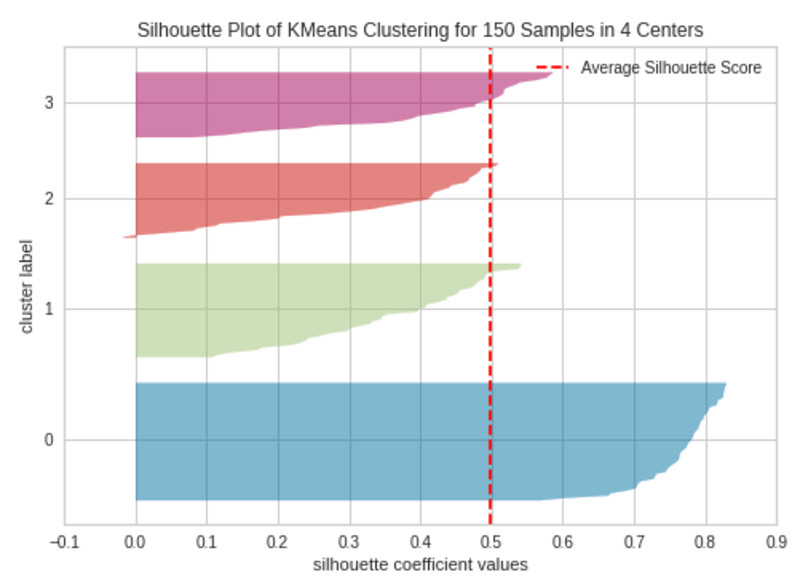
Silhouette Plot with 4 Clusters (okay=4)|Picture by Writer
okay=5
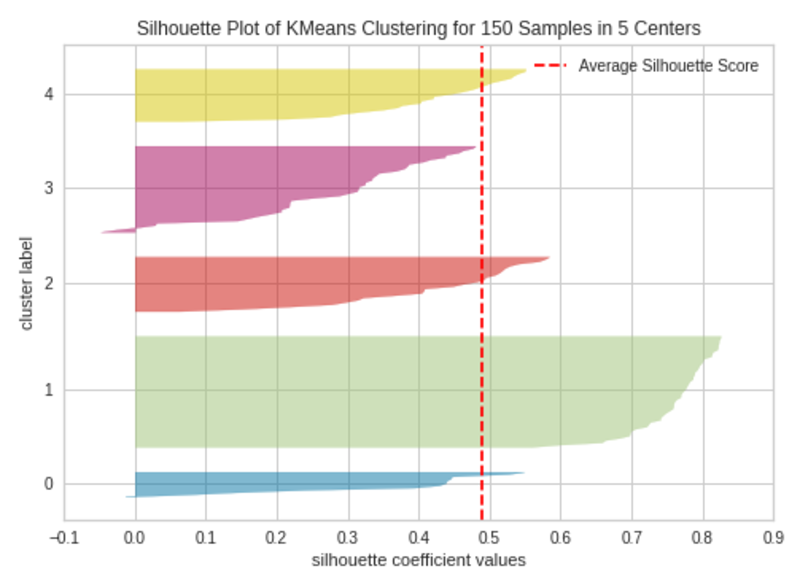
Silhouette Plot with 4 Clusters (okay=5)|Picture by Writer
The silhouette plot accommodates one knife form per cluster. Every knife form is created by bars that signify all the information factors within the cluster. So, the width of a knife form represents the variety of all cases within the cluster. The bar size represents the Silhouette Coefficient for every occasion. The dashed line signifies the silhouette rating — Supply: Hands-On K-Means Clustering (written by me).
A plot with roughly equal widths of knife shapes tells us the clusters are well-balanced and have roughly the identical variety of cases inside every cluster — one of the vital necessary assumptions in Ok-Means clustering.
When the bars in a knife form prolong the dashed line, the clusters are nicely separated — one other necessary assumption in Ok-Means clustering.
When okay=3, the clusters are well-balanced and well-separated. So, the optimum variety of clusters in our instance is 3.
Crucial parameters of the SilhouetteVisualizer embrace:
- estimator: Ok-Means mannequin occasion
- colours: string, a set of colours used for every knife form. ‘yellowbrick’ or considered one of Matplotlib colour map strings comparable to ‘Accent’, ‘Set1’, and so on.
Utilization
The category imbalance plot detects the imbalance of lessons within the goal column in classification datasets.
Class imbalance occurs when one class has considerably extra cases than the opposite class. For instance, a dataset associated to spam electronic mail detection has 9900 cases for the “Not spam” class and simply 100 cases for the “Spam” class. The mannequin will fail to seize the minority class (the Spam class). Because of this, the mannequin won’t be correct in predicting the minority class when a category imbalance happens — Supply: Top 20 Machine Learning and Deep Learning Mistakes That Secretly Happen Behind the Scenes (written by me).
Yellowbrick implementation
Creating the category imbalance plot with the standard methodology is complicated and time-consuming. As a substitute, we are able to use Yellowbrick’s ClassBalance visualizer.
To plot a category imbalance plot in Yellowbirck, we’ll use the breast_cancer dataset (classification dataset, see Citation on the finish).
The next code explains how we are able to make the most of Yellowbrick’s ClassBalance visualizer to create a category imbalance plot utilizing the breast_cancer dataset.
Code by Writer
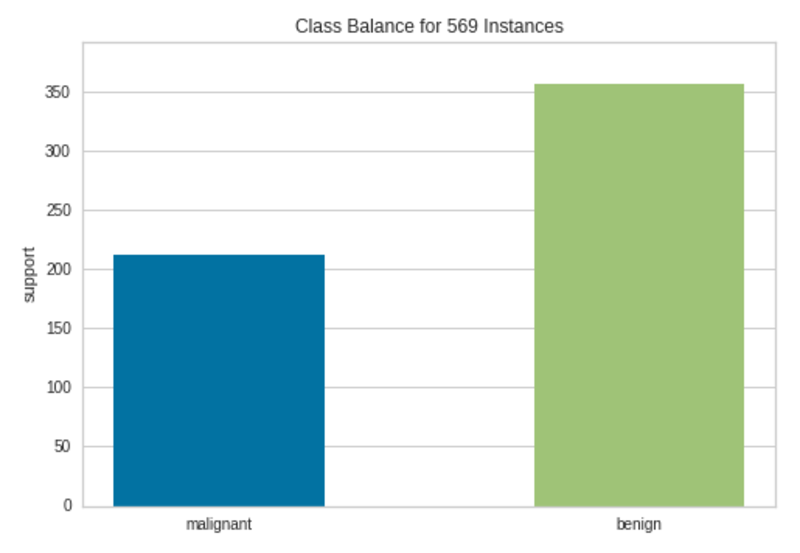
Class Imbalance Plot|Picture by Writer
There are greater than 200 cases within the Malignant class and greater than 350 cases within the Benign class. Due to this fact, we can’t see a lot class imbalance right here though the cases will not be equally distributed among the many two lessons.
Crucial parameters of the ClassBalance visualizer embrace:
- labels: listing, the names of the distinctive lessons within the goal column.
Utilization
The residuals plot in linear regression is used to find out whether or not the residuals (noticed values-predicted values) are uncorrelated (impartial) by analyzing the variance of errors in a regression mannequin.
The residuals plot is created by plotting the residuals in opposition to the predictions. If there’s any form of sample between predictions and residuals, it confirms that the fitted regression mannequin isn’t good. If the factors are randomly dispersed across the x-axis, the regression mannequin is fitted nicely with the information.
Yellowbrick implementation
Creating the residuals plot with the standard methodology is complicated and time-consuming. As a substitute, we are able to use Yellowbrick’s ResidualsPlot visualizer.
To plot a residuals plot in Yellowbirck, we’ll use the Promoting (Advertising.csv, see Citation on the finish) dataset.
The next code explains how we are able to make the most of Yellowbrick’s ResidualsPlot visualizer to create a residuals plot utilizing the Promoting dataset.
Code by Writer
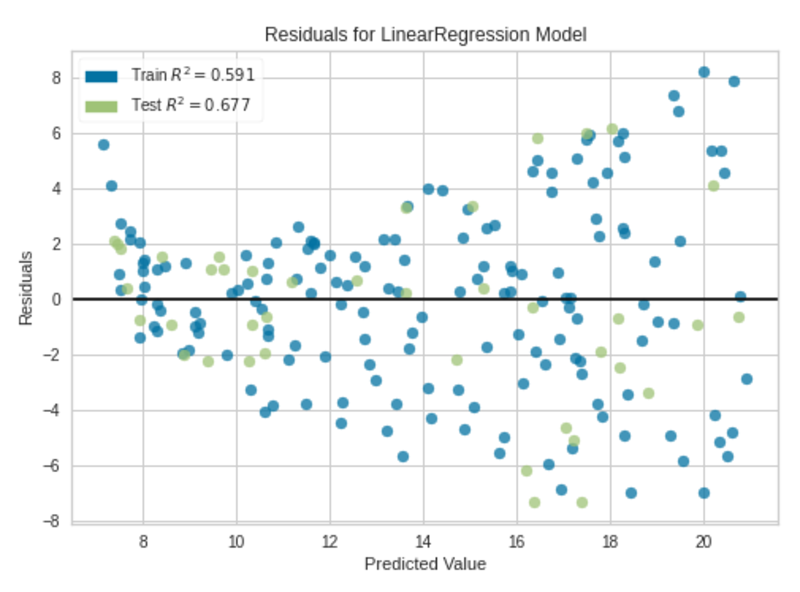
Residuals Plot|Picture by Writer
We are able to clearly see some form of non-linear sample between predictions and residuals within the residuals plot. The fitted regression mannequin isn’t good, however it’s ok.
Crucial parameters of the ResidualsPlot visualizer embrace:
- estimator: This may be any Scikit-learn regressor.
- hist: bool, default
True. Whether or not to plot the histogram of residuals, which is used to verify one other assumption — The residuals are roughly usually distributed with the imply 0 and a hard and fast customary deviation.
Utilization
The prediction error plot in linear regression is a graphical methodology that’s used to judge a regression mannequin.
The prediction error plot is created by plotting the predictions in opposition to the precise goal values.
If the mannequin makes very correct predictions, the factors ought to be on the 45-degree line. In any other case, the factors are dispersed round that line.
Yellowbrick implementation
Creating the prediction error plot with the standard methodology is complicated and time-consuming. As a substitute, we are able to use Yellowbrick’s PredictionError visualizer.
To plot a prediction error plot in Yellowbirck, we’ll use the Promoting (Advertising.csv, see Citation on the finish) dataset.
The next code explains how we are able to make the most of Yellowbrick’s PredictionError visualizer to create a residuals plot utilizing the Promoting dataset.
Code by Writer
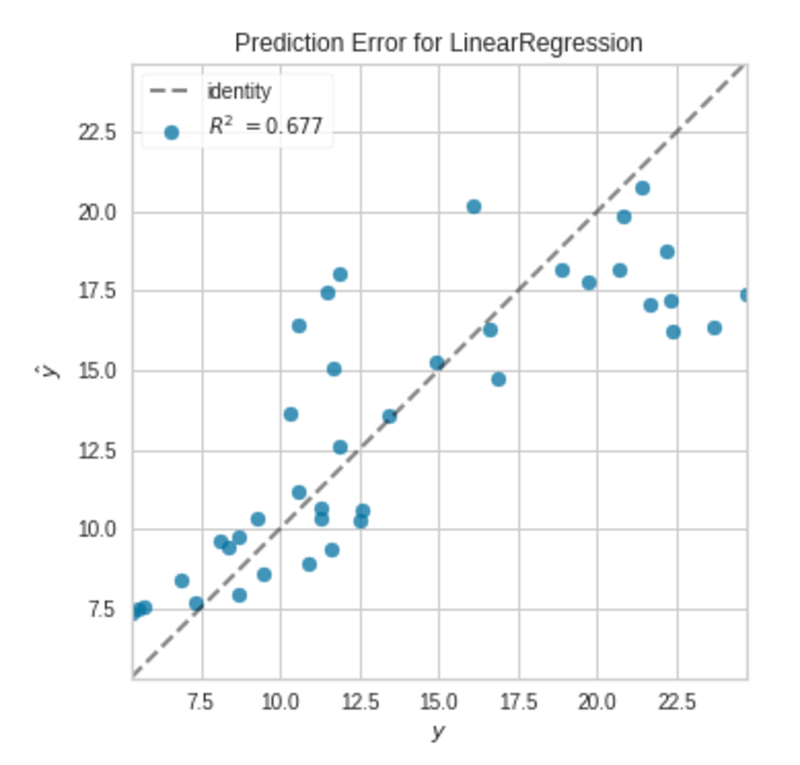
Prediction Error Plot|Picture by Writer
The factors will not be precisely on the 45-degree line, however the mannequin is sweet sufficient.
Crucial parameters of the PredictionError visualizer embrace:
- estimator: This may be any Scikit-learn regressor.
- id: bool, default
True. Whether or not to attract the 45-degree line.
Utilization
The Prepare dinner’s distance measures the impression of cases on linear regression. Situations with giant impacts are thought of as outliers. A dataset with a lot of outliers isn’t appropriate for linear regression with out preprocessing. Merely, the Prepare dinner’s distance plot is used to detect outliers within the dataset.
Yellowbrick implementation
Creating the Prepare dinner’s distance plot with the standard methodology is complicated and time-consuming. As a substitute, we are able to use Yellowbrick’s CooksDistance visualizer.
To plot a Prepare dinner’s distance plot in Yellowbirck, we’ll use the Promoting (Advertising.csv, see Citation on the finish) dataset.
The next code explains how we are able to make the most of Yellowbrick’s CooksDistance visualizer to create a Prepare dinner’s distance plot utilizing the Promoting dataset.
Code by Writer
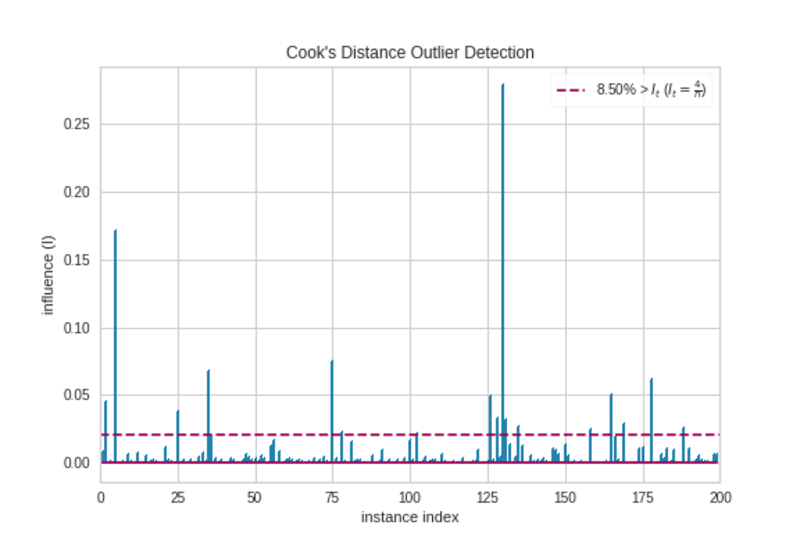
Prepare dinner’s Distance Plot|Picture by Writer
There are some observations that stretch the brink (horizontal purple) line. They’re outliers. So, we must always put together the information earlier than we make any regression mannequin.
Crucial parameters of the CooksDistance visualizer embrace:
- draw_threshold: bool, default
True. Whether or not to attract the brink line.
Utilization
The function importances plot is used to pick out the minimal required necessary options to provide an ML mannequin. Since not all options contribute the identical to the mannequin, we are able to take away much less necessary options from the mannequin. That may scale back the complexity of the mannequin. Easy fashions are straightforward to coach and interpret.
The function importances plot visualizes the relative importances of every function.
Yellowbrick implementation
Creating the function importances plot with the standard methodology is complicated and time-consuming. As a substitute, we are able to use Yellowbrick’s FeatureImportances visualizer.
To plot a function importances plot in Yellowbirck, we’ll use the breast_cancer dataset (see Citation on the finish) which accommodates 30 options.
The next code explains how we are able to make the most of Yellowbrick’s FeatureImportances visualizer to create a function importances plot utilizing the breast_cancer dataset.
Code by Writer
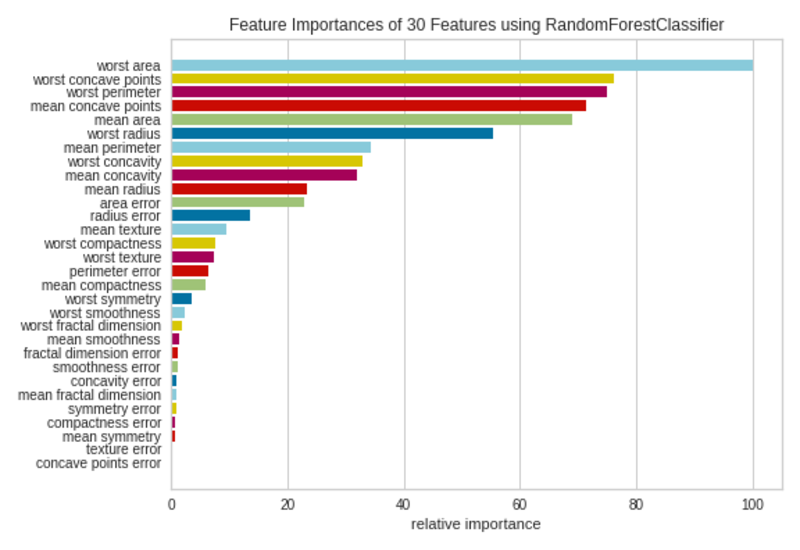
Function Importances Plot|Picture by Writer
Not all 30 options within the dataset are a lot contributed to the mannequin. We are able to take away the options with small bars from the dataset and refit the mannequin with chosen options.
Crucial parameters of the FeatureImportances visualizer embrace:
- estimator: Any Scikit-learn estimator that helps both
feature_importances_attribute orcoef_attribute. - relative: bool, default
True. Whether or not to plot relative significance as a proportion. IfFalse, the uncooked numeric rating of the function significance is proven. - absolute: bool, default
False. Whether or not to contemplate solely the magnitude of coefficients by avoiding unfavourable indicators.
- Principal Part Plot: PCA(), Utilization — Visualizes high-dimensional knowledge in a 2D or 3D scatter plot which can be utilized to establish necessary patterns in high-dimensional knowledge.
- Validation Curve: ValidationCurve(), Utilization — Plots the affect of a single hyperparameter on the prepare and validation set.
- Studying Curve: LearningCurve(), Utilization — Detects underfitting, overfitting and just-right situations of a mannequin, Identifies gradual convergence, oscillating, oscillating with divergence and correct convergencesituations when discovering the optimum studying price of a neural community, Exhibits how a lot our mannequin advantages from including extra coaching knowledge.
- Elbow Plot: KElbowVisualizer(), Utilization — Selects the optimum variety of clusters in Ok-Means clustering.
- Silhouette Plot: SilhouetteVisualizer(), Utilization — Selects the optimum variety of clusters in Ok-Means clustering, Detects cluster imbalance in Ok-Means clustering.
- Class Imbalance Plot: ClassBalance(), Utilization — Detects the imbalance of lessons within the goal column in classification datasets.
- Residuals Plot: ResidualsPlot(), Utilization — Determines whether or not the residuals (noticed values-predicted values) are uncorrelated (impartial) by analyzing the variance of errors in a regression mannequin.
- Prediction Error Plot: PredictionError(), Utilization — A graphical methodology that’s used to judge a regression mannequin.
- Prepare dinner’s Distance Plot: CooksDistance(), Utilization — Detects outliers within the dataset primarily based on the Prepare dinner’s distances of cases.
- Function Importances Plot: FeatureImportances(), Utilization — Selects the minimal required necessary options primarily based on the relative importances of every function to provide an ML mannequin.
That is the tip of immediately’s put up.
Please let me know when you’ve any questions or suggestions.
Breast most cancers dataset data
- Quotation: Dua, D. and Graff, C. (2019). UCI Machine Studying Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: College of California, College of Data and Laptop Science.
- Supply: https://archive.ics.uci.edu/ml/datasets/breast+cancer+wisconsin+(diagnostic)
- License: Dr. William H. Wolberg (Basic Surgical procedure Dept.
College of Wisconsin), W. Nick Road (Laptop Sciences Dept.
College of Wisconsin) and Olvi L. Mangasarian (Laptop Sciences Dept. College of Wisconsin) holds the copyright of this dataset. Nick Road donated this dataset to the general public beneath the Inventive Commons Attribution 4.0 Worldwide License (CC BY 4.0). You may study extra about completely different dataset license sorts here.
Iris dataset data
- Quotation: Dua, D. and Graff, C. (2019). UCI Machine Studying Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: College of California, College of Data and Laptop Science.
- Supply: https://archive.ics.uci.edu/ml/datasets/iris
- License: R.A. Fisher holds the copyright of this dataset. Michael Marshall donated this dataset to the general public beneath the Inventive Commons Public Area Dedication License (CC0). You may study extra about completely different dataset license sorts here.
Promoting dataset data
References
Rukshan Pramoditha (@rukshanpramoditha) has B.Sc. in Industrial Statistics. Supporting the information science schooling since 2020. High 50 Knowledge Science/AI/ML Author on Medium. He have wrtten articles on Knowledge Science, Machine Studying, Deep Studying, Neural Networks, Python, and Knowledge Analytics. He has confirmed observe file of changing complicated subjects into one thing useful and simple to grasp.
Original. Reposted with permission.
[ad_2]
Source link
