

[ad_1]
The exponentially increasing scale of deep studying fashions is a serious drive in advancing the state-of-the-art and a supply of rising fear over the power consumption, velocity, and, subsequently, feasibility of massive-scale deep studying. Lately, researchers from Cornell talked about Transformer topologies, significantly how they’re dramatically higher when scaled as much as billions and even trillions of parameters, resulting in an exponential rise within the utilization of deep studying computing. These large-scale Transformers are a well-liked however costly answer for a lot of duties as a result of digital {hardware}’s power effectivity has not stored up with the rising FLOP necessities of cutting-edge deep studying fashions. Additionally they carry out more and more impressively in different domains, resembling laptop imaginative and prescient, graphs, and multi-modal settings.
Additionally, they exhibit switch studying abilities, which allow them to rapidly generalize to sure actions, generally in a zero-shot atmosphere with no further coaching required. The price of these fashions and their common machine-learning capabilities are main driving forces behind the creation of {hardware} accelerators for efficient and fast inference. Deep studying {hardware} has beforehand been extensively developed in digital electronics, together with GPUs, cell accelerator chips, FPGAs, and large-scale AI-dedicated accelerator programs. Optical neural networks have been instructed as options that present higher effectivity and latency than neural-network implementations on digital computer systems, amongst different methods. On the similar time, there’s additionally important curiosity in analog computing.
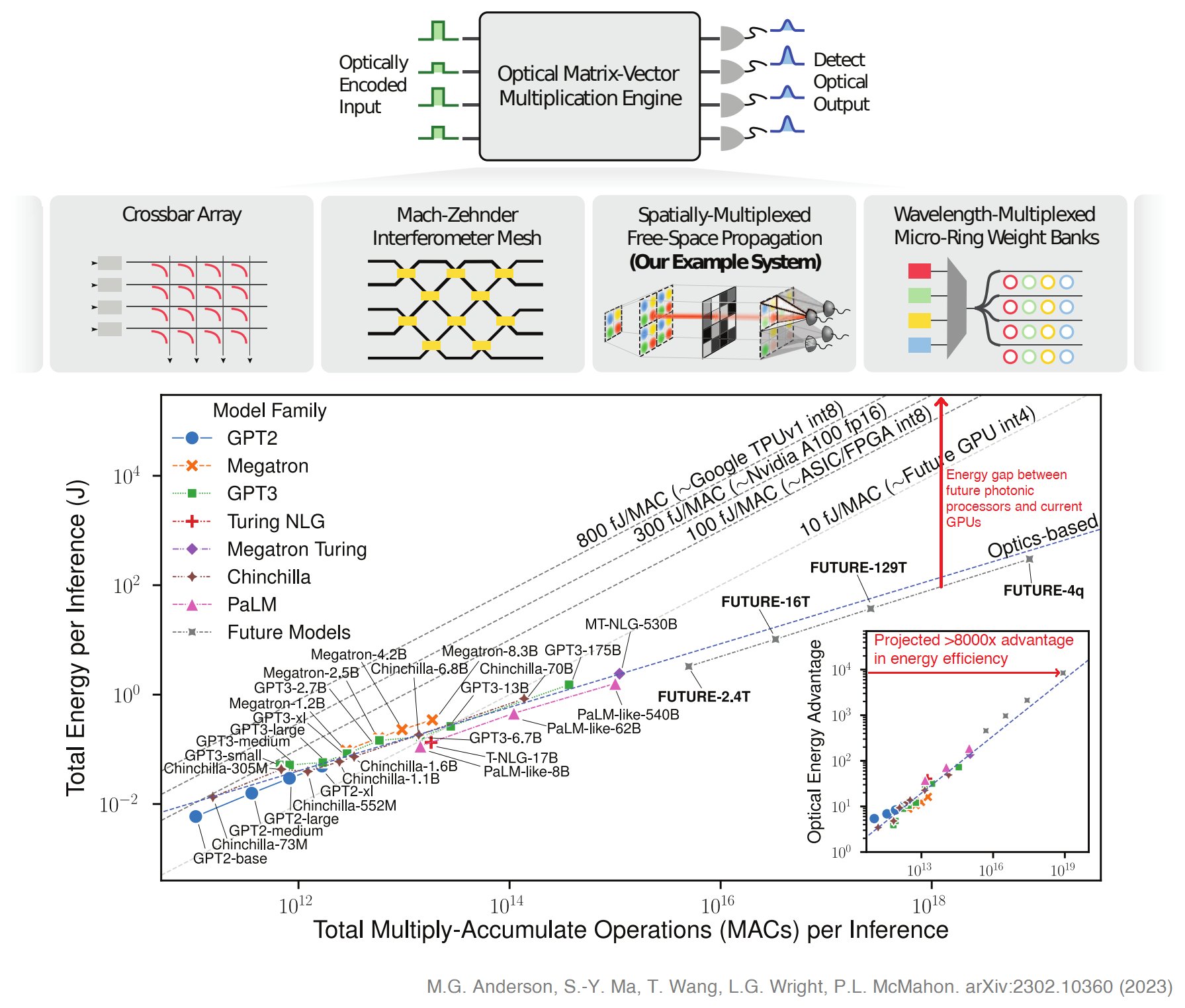
Though these analog programs are vulnerable to noise and error, neural community operations can incessantly be carried out optically for a a lot decrease price, with the primary price usually being {the electrical} overhead related to loading the weights and knowledge amortized in giant linear operations. The acceleration of huge-scale fashions like Transformers is thus significantly promising. Theoretically, the scaling is asymptotically extra environment friendly concerning power per MAC than digital programs. Right here, they show how Transformers use this scaling increasingly more. They sampled operations from an actual Transformer for language modeling to run on an actual spatial gentle modulator-based experimental system. They then used the outcomes to create a calibrated simulation of a full Transformer working optically. This was executed to point out that Transformers might run on these programs regardless of their noise and error traits.
Of their simulations utilizing weights and inputs obtained from these trials with systematic error, noise, and imprecision, they found that Transformers nonetheless carry out virtually in addition to these working digitally. Here’s a abstract of their main contributions:
• They created scaling guidelines for the efficiency and complete power prices of optical Transformers vs. the mannequin dimension and optical power use. They experimentally confirmed that linear operations in Transformers might be precisely carried out on actual optical {hardware}, regardless of errors and noise.
• Utilizing a design based mostly on their simulations and assessments, they predicted the power consumption of a complete ONN accelerator.
• They calculated that optics devour orders-of-magnitude much less power than cutting-edge Processors.
Though their simulations and assessments used a particular piece of {hardware} as an illustration, their focus right here is broader. They need to understand how optical power scaling and noise relate to Transformer building and efficiency. Consequently, virtually all of their conclusions usually apply to linear optical processors, whatever the specifics of their {hardware} implementation.
Take a look at the Paper. All Credit score For This Analysis Goes To the Researchers on This Undertaking. Additionally, don’t overlook to hitch our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at present pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Expertise(IIT), Bhilai. He spends most of his time engaged on initiatives aimed toward harnessing the facility of machine studying. His analysis curiosity is picture processing and is keen about constructing options round it. He loves to attach with individuals and collaborate on attention-grabbing initiatives.
[ad_2]
Source link
