

[ad_1]
Prior to now 12 months, pure language processing has seen outstanding developments with the emergence of language fashions geared up with considerably longer contexts. Amongst these fashions are GPT-4 with a context size of 32k, MosaicML’s MPT with 65k context, and Anthropic’s Claude, boasting a powerful 100k context size. As functions corresponding to lengthy doc querying and story writing proceed to develop, the necessity for language fashions with prolonged context turns into evident. Nonetheless, the problem lies in scaling up the context size of Transformers, as their consideration layer has computational and reminiscence necessities that develop quadratically with the enter sequence size.
Addressing this problem, FlashAttention, an progressive algorithm launched only a 12 months in the past, gained fast adoption throughout numerous organizations and analysis labs. This algorithm efficiently accelerated consideration computation whereas decreasing its reminiscence footprint with out sacrificing accuracy or approximating the outcomes. With 2-4 occasions sooner efficiency than optimized baselines at its preliminary launch, FlashAttention proved to be a groundbreaking development. But, it nonetheless had untapped potential, because it fell wanting the blazing-fast optimized matrix-multiply (GEMM) operations that achieved as much as 124 TFLOPs/s on A100 GPUs.
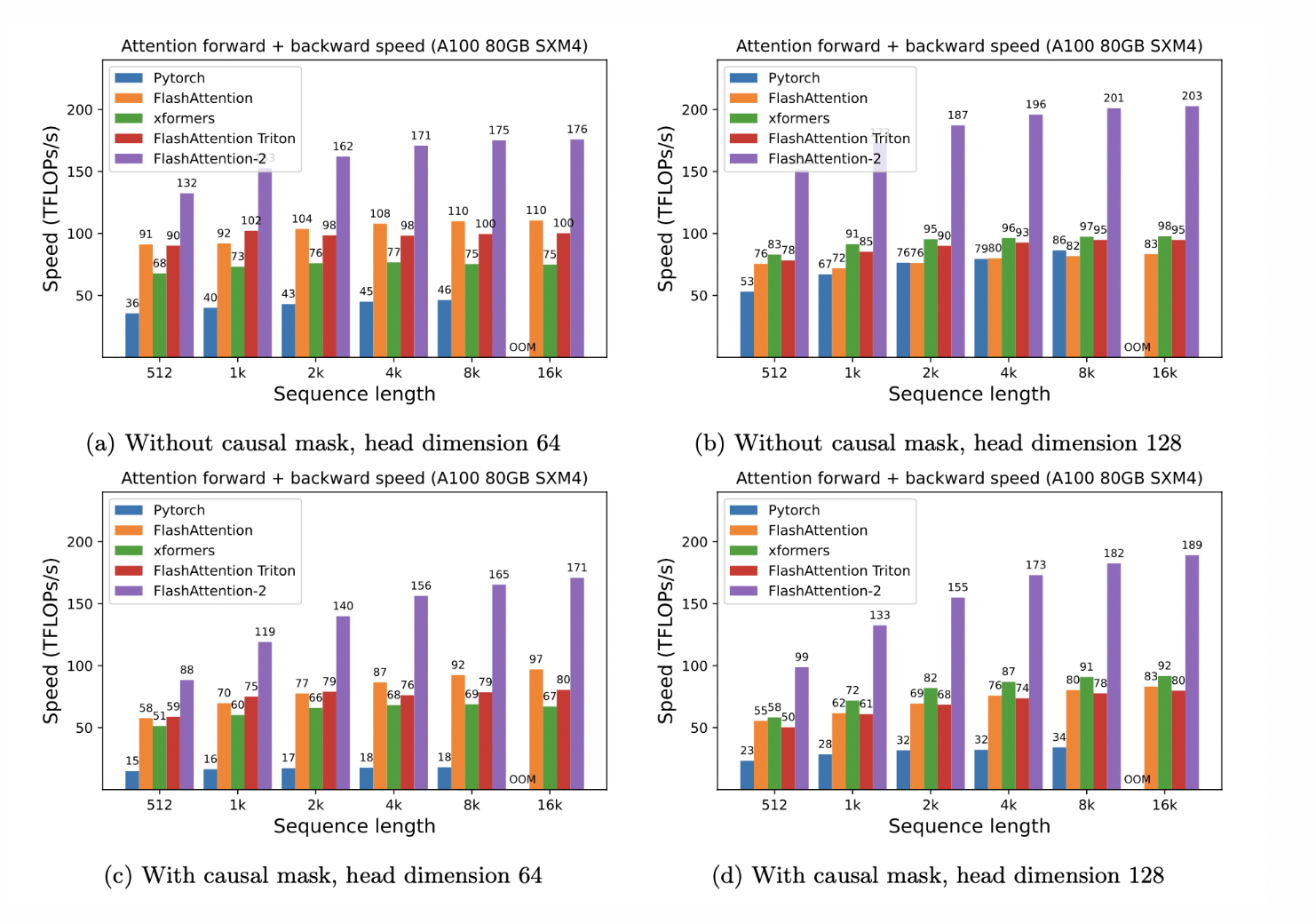
Taking the following leap ahead, the builders of FlashAttention have now launched FlashAttention-2, a reinvented model that considerably surpasses its predecessor. Leveraging Nvidia’s CUTLASS 3.x and CuTe core library, FlashAttention-2 achieves a outstanding 2x speedup, reaching as much as 230 TFLOPs/s on A100 GPUs. Furthermore, in end-to-end coaching of GPT-style language fashions, FlashAttention-2 attains a coaching pace of as much as 225 TFLOPs/s, with a powerful 72% mannequin FLOP utilization.
The important thing enhancements of FlashAttention-2 lie in its higher parallelism and work partitioning methods. Initially, FlashAttention parallelized over batch dimension and variety of heads, successfully using the compute sources on the GPU. Nonetheless, for lengthy sequences with smaller batch sizes or fewer heads, FlashAttention-2 now parallelizes over the sequence size dimension, leading to vital speedup in these eventualities.
One other enchancment entails effectively partitioning work between completely different warps inside every thread block. In FlashAttention, splitting Ok and V throughout 4 warps whereas preserving Q accessible by all warps, known as the “sliced-Ok” scheme, led to pointless shared reminiscence reads and writes, slowing down the computation. FlashAttention-2 takes a distinct method, now splitting Q throughout 4 warps whereas preserving Ok and V accessible to all warps. This eliminates the necessity for communication between warps and considerably reduces shared reminiscence reads/writes, additional boosting efficiency.
FlashAttention-2 introduces a number of new options to broaden its applicability and improve its capabilities. It now helps head dimensions as much as 256, accommodating fashions like GPT-J, CodeGen, CodeGen2, and StableDiffusion 1.x, opening up extra speedup and memory-saving alternatives. Moreover, FlashAttention-2 embraces multi-query consideration (MQA) and grouped-query consideration (GQA) variants, the place a number of heads of the question can attend to the identical head of key and worth, resulting in larger inference throughput and higher efficiency.
The efficiency of FlashAttention-2 is actually spectacular. Benchmarked on an A100 80GB SXM4 GPU, it achieves round 2x speedup in comparison with its predecessor and as much as 9x speedup in comparison with an ordinary consideration implementation in PyTorch. Furthermore, when used for end-to-end coaching of GPT-style fashions, FlashAttention-2 unlocks as much as 225 TFLOPs/s on A100 GPUs, representing a 1.3x end-to-end speedup over already extremely optimized fashions with FlashAttention.
Trying forward, the potential functions of FlashAttention-2 are promising. With the flexibility to coach fashions with 16k longer context for a similar worth as earlier 8k context fashions, this expertise may also help analyze lengthy books, reviews, high-resolution pictures, audio, and video. Plans for broader applicability on gadgets like H100 GPUs and AMD GPUs and optimizing for brand new information varieties like fp8 are underway. Moreover, combining the low-level optimizations of FlashAttention-2 with high-level algorithmic adjustments may pave the way in which for coaching AI fashions with unprecedentedly longer context. Collaboration with compiler researchers to boost programmability can be on the horizon, promising a brilliant future for the following era of language fashions.
Take a look at the Paper and Github. Don’t neglect to hitch our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra. In case you have any questions concerning the above article or if we missed something, be at liberty to electronic mail us at Asif@marktechpost.com
🚀 Check Out 900+ AI Tools in AI Tools Club

Niharika is a Technical consulting intern at Marktechpost. She is a 3rd 12 months undergraduate, at present pursuing her B.Tech from Indian Institute of Expertise(IIT), Kharagpur. She is a extremely enthusiastic particular person with a eager curiosity in Machine studying, Information science and AI and an avid reader of the most recent developments in these fields.
[ad_2]
Source link
