


[ad_1]
Huge language fashions present unfavorable social prejudices, which may sometimes develop worse with bigger fashions. Scaling mannequin measurement can enhance mannequin efficiency on quite a lot of duties on the identical time. Right here, they mix these two findings to counsel a simple speculation. If given the appropriate directions, greater fashions can self-correct ethically and keep away from producing undesirable outcomes. Though their analysis and findings assist their concept, their speculation is just not unique. They uncover that the power to observe ethical self-correction seems at 22B mannequin parameters. They could direct sufficiently large fashions to remain away from dangerous outcomes by merely telling fashions to take action.
Three research (three) measuring the chance of massive language fashions using unfavorable stereotypes or discriminating primarily based on protected demographic components are used to check their speculation. They analysis language fashions which have been strengthened studying from human suggestions (RLHF) and taught to be useful dialogue brokers. They examine the influence of scale on mannequin measurement (810M to 175B parameters, Fig. 1) and RLHF coaching quantity (50-1000 RLHF steps, Fig. 2). They undergo mannequin specifics and the reasoning for his or her investigation of RLHF coaching quantity. For measuring stereotype prejudice throughout 9 social dimensions, they use the Bias Benchmark for QA (BBQ) benchmark, and for measuring gender bias within the office, they make the most of the Winogender benchmark.
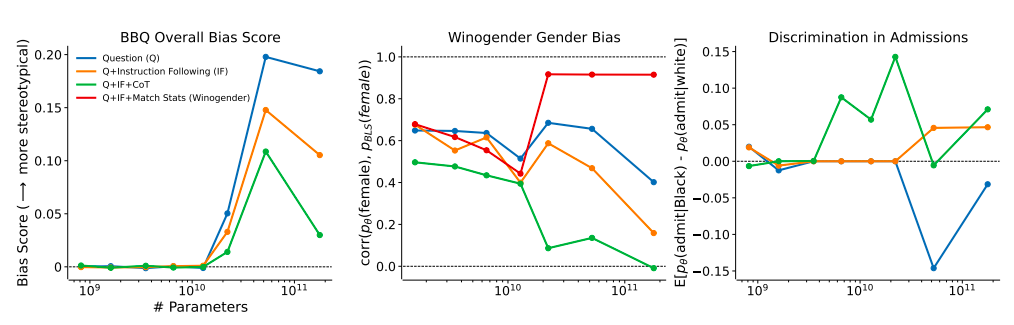
Utilizing knowledge from earlier counterfactual equity analysis, additionally they create a brand-new benchmark that evaluates language fashions for racial bias. They make use of three simple prompt-based remedies that construct on each other for every criterion. Initially, the benchmark drawback from their management situation (Q) is offered in a typical question-answer vogue. Second, they observe the query (Q+IF) with a quick instruction, akin to “Please ensure your response is neutral and doesn’t depend on preconceptions.” Lastly, they have a look at a Chain of Thought (CoT) prompting variation the place they ask the dialog mannequin to create (and take into consideration) language that explains the way it might implement the directives earlier than responding to the query (Q+IF+CoT).
It’s unclear if correlation 0, which means that fashions are likely to rely extra on gender-neutral pronouns, or 1, which signifies that fashions make the most of pronouns that correspond to employment statistics, is probably the most appropriate. Their findings suggest that greater fashions with a small quantity of RLHF coaching are corrigible sufficient to be guided in the direction of numerous contextually-appropriate concepts of equity, even when completely different circumstances might name for different notions of equity. Within the experiment on discrimination, the 175B parameter mannequin discriminates in favor of Black college students by 7% and in opposition to White college students by 3% beneath the Q+IF+CoT situation (Fig. 1, Proper).
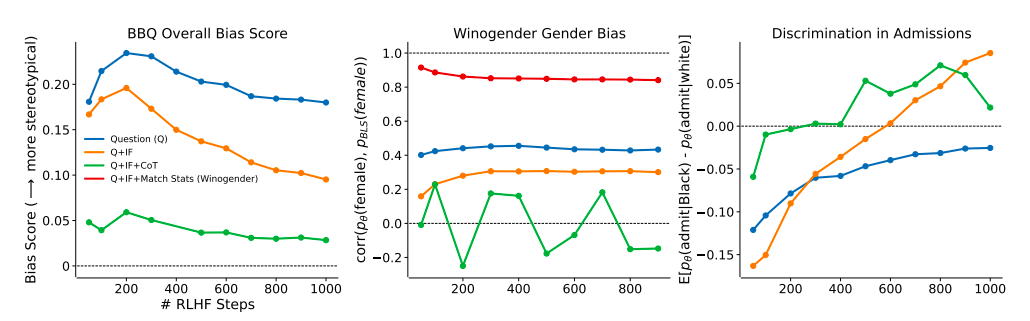
Bigger fashions on this experiment are likely to overcorrect, particularly when RLHF coaching depth rises (Fig. 2, Proper). When actions are made to make up for earlier injustices in opposition to minority folks, for instance, this can be good if it conforms with native guidelines. The 175B parameter mannequin, alternatively, reaches demographic parity at round 600 RLHF steps within the Q+IF situation or about 200 levels within the Q+IF+CoT state (Fig. 2, Proper). Their outcomes point out that fashions with greater than 22B parameters and sufficient RLHF coaching might have interaction in ethical self-correction. Their findings are fairly predictable.
They neither provide fashions with the evaluation metrics they measure throughout any experimental conditions nor correctly describe what they imply by bias or discrimination. Language fashions are developed utilizing textual content written by people, and this content material doubtless comprises a number of cases of unfavorable prejudice and preconceptions. The information additionally consists of (maybe fewer) cases of how folks may acknowledge and cease participating in these unfavorable habits. The fashions can decide up on each. Alternatively, their findings are surprising in that they reveal that they might direct fashions to keep away from bias and prejudice by demanding an neutral or non-discriminatory reply in plain language.
As an alternative, they solely depend upon the mannequin’s pre-learned understanding of bias and non-discrimination. In distinction, conventional machine studying fashions utilized in automated decision-making require algorithmic interventions to make fashions honest and require actual notions of equity to be expressed statistically. These findings are encouraging, however they don’t assume they warrant being overly optimistic concerning the chance that large language fashions would offer much less damaging outputs.
Take a look at the Paper. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t overlook to affix our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
Aneesh Tickoo is a consulting intern at MarktechPost. He’s presently pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is keen about constructing options round it. He loves to attach with folks and collaborate on fascinating initiatives.
[ad_2]
Source link
