


[ad_1]
Illustration by Writer. Supply: Flaticon
Python is the most well-liked language you’ll encounter within the discipline of knowledge science for its simplicity, the big group and the massive availability of open-source libraries.
If you’re engaged on a knowledge science challenge, Python packages will ease your life because you simply want a couple of strains of code to do difficult operations, like manipulating the information and making use of a machine studying/deep studying mannequin.
When beginning your information science journey, it’s really helpful to start out by studying two of probably the most helpful Python packages: NumPy and Pandas. On this article, we’re introducing these two libraries. Let’s get began!
NumPy stands for Numerical Python and is used to function environment friendly computations of arrays and matrices behind the scenes of machine studying fashions. The constructing block of Numpy is the array, which is a knowledge construction similar to the record, with the distinction that it offers an enormous quantity of mathematical capabilities. In different phrases, the Numpy array is a multidimensional array object.
Create Numpy Arrays
We will outline NumPy arrays utilizing an inventory or record of lists:
import numpy as np
l = [[1,2,3],[4,5,6],[7,8,9]]
numpy_array = np.array(l)
numpy_array
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
In a different way from an inventory of lists, we are able to visualise the matrix 3X3 with an indentation between every row. Furthermore, NumPy offers greater than 40 built-in capabilities for array creation.
To create an array crammed with zeros, there’s the perform np.zeros , during which you simply have to specify the form you want:
zeros_array = np.zeros((3,4))
zeros_array
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
In the identical method, we are able to create an array crammed with ones:
ones_array = np.ones((3,4))
ones_array
array([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
There may be additionally the likelihood to create the id matrix, which is a sq. array with 1s on the principle diagonal and off-diagonal parts are 0s:
identity_array = np.id(3)
identity_array
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
Moreover, NumPy offers totally different capabilities to create random arrays. To create an array crammed with random samples from a uniform distribution over [0,1], we simply want the perform np.random.rand :
random_array = np.random.rand(3,4)
random_array
array([[0.84449279, 0.71146992, 0.48159787, 0.04927379],
[0.03428534, 0.26851667, 0.65718662, 0.52284251],
[0.1380207 , 0.91146148, 0.74171469, 0.57325424]])
Equally to the earlier perform, we are able to outline an array with random values, however this time time are taken from a normal regular distribution:
randn_array = np.random.randn(10)
randn_array
array([-0.68398432, -0.25466784, 0.27020797, 0.29632334, -0.20064897,
0.7988508 , 1.34759319, -0.41418478, -0.35223377, -0.10282884])
In case, we have an interest on constructing an array with random integers that belong to the interval [low,high), we just need the function np.random.randint :
randint_array = np.random.randint(1,20,20)
randint_array
array([14, 3, 1, 2, 17, 15, 5, 17, 18, 9, 4, 19, 14, 14, 1, 10, 17,
19, 4, 6])
Indexing and Slicing
Past the built-in capabilities for array creation, one other good level of NumPy is that it’s potential to pick parts from the array utilizing a set of sq. brackets. For instance, we are able to attempt to take the primary row of the matrix:
a1 = np.array([[1,2,3],[4,5,6]])
a1[0]
Let’s suppose that we wish to choose the third aspect of the primary row. On this case, we have to specify two indices, the index of the row and the index of the column:
Another is to make use of a1[0][2], nevertheless it’s thought-about inefficient as a result of it first creates the array containing the primary row and, then, it selects the aspect from that row.
Furthermore, we are able to take slices from the matrix with the syntax begin:cease:step contained in the brackets, the place the cease index just isn’t included. For instance, we would like once more to pick the primary row, however we simply take the primary two parts:
If we choose to pick all of the rows, however we wish to extract the primary aspect of every row:
Along with the integer array indexing, there’s additionally the boolean array indexing to pick the weather from an array. Let’s suppose that we would like solely the weather that respect the next situation:
array([[False, False, False],
[False, False, True]])
If we filter the array primarily based on this situation, the output will present solely the True parts:
Array Manipulation
When working in information science initiatives, it typically occurs to reshape an array to a brand new form with out altering the information.
For instance, we begin with an array of dimension 2X3. If we aren’t certain of our array’s form, there’s the attribute form that may helps us:
a1 = np.array([[1,2,3],[4,5,6]])
print(a1)
print('Form of Array: ',a1.form)
[[1 2 3]
[4 5 6]]
Form of Array: (2, 3)
To reshape the array to the dimension 3X2, we are able to merely use the perform reshape:
a1 = a1.reshape(3,2)
print(a1)
print('Form of Array: ',a1.form)
[[1 2]
[3 4]
[5 6]]
Form of Array: (3, 2)
One other frequent state of affairs is to show a multidimensional array right into a single dimensional array. That is potential by specifying -1 as form:
a1 = a1.reshape(-1)
print(a1)
print('Form of Array: ',a1.form)
[1 2 3 4 5 6]
Form of Array: (6,)
It may well additionally happen that it’s essential get hold of a transposed array:
a1 = np.array([[1,2,3,4,5,6]])
print('Earlier than form of Array: ',a1.form)
a1 = a1.T
print(a1)
print('After form of Array: ',a1.form)
Earlier than form of Array: (1, 6)
[[1]
[2]
[3]
[4]
[5]
[6]]
After form of Array: (6, 1)
In the identical method, you’ll be able to apply the identical transformation utilizing np.transpose(a1).
Array Multiplication
In case you attempt to construct machine studying algorithms from scratch, you’ll absolutely have to calculate the matrix product of two arrays. That is potential utilizing the perform np.matmul when the array have greater than 1 dimension:
a1 = np.array([[1,2,3],[4,5,6]])
a2 = np.array([[1,2],[4,5],[7,8]])
print('Form of Array a1: ',a1.form)
print('Form of Array a2: ',a2.form)
a3 = np.matmul(a1,a2)
# a3 = a1 @ a2
print(a3)
print('Form of Array a3: ',a3.form)
Form of Array a1: (2, 3)
Form of Array a2: (3, 2)
[[30 36]
[66 81]]
Form of Array a3: (2, 2)
@ is usually a shorter different to np.matmul.
In case you multiply a matrix with a scalar, np.dot is the only option:
a1 = np.array([[1,2,3],[4,5,6]])
a3 = np.dot(a1,2)
# a3 = a1 * 2
print(a3)
print('Form of Array a3: ',a3.form)
[[ 2 4 6]
[ 8 10 12]]
Form of Array a3: (2, 3)
On this case, * is a shorter different to np.dot.
Mathematical Capabilities
NumPy offers an enormous number of mathematical capabilities, such because the trigonometric capabilities, rounding capabilities, exponentials, logarithms and so forth. You will discover the complete record here. We’re going to present crucial capabilities you can apply to your issues.
The exponential and the pure logarithm are absolutely the most well-liked and recognized transformations:
a1 = np.array([[1,2,3],[4,5,6]])
print(np.exp(a1))
[[ 2.71828183 7.3890561 20.08553692]
[ 54.59815003 148.4131591 403.42879349]]
a1 = np.array([[1,2,3],[4,5,6]])
print(np.log(a1))
[[0. 0.69314718 1.09861229]
[1.38629436 1.60943791 1.79175947]]
If we wish to extract the minimal and the utmost in a single line of code, we simply have to name the next capabilities:
a1 = np.array([[1,2,3],[4,5,6]])
print(np.min(a1),np.max(a1)) # 1 6
We will additionally calculate the square-root from every aspect of the array:
a1 = np.array([[1,2,3],[4,5,6]])
print(np.sqrt(a1))
[[1. 1.41421356 1.73205081]
[2. 2.23606798 2.44948974]]
Pandas is constructed on Numpy and is beneficial for manipulating the dataset. There are two major information buildings: Sequence and Dataframe. Whereas the Sequence is a sequence of values, the dataframe is a desk with rows and columns. In different phrases, the sequence is a column of the dataframe.
Create Sequence and Dataframe
To construct the Sequence, we are able to simply cross the record of values to the tactic:
import pandas as pd
type_house = pd.Sequence(['Loft','Villa'])
type_house
0 Loft
1 Villa
dtype: object
We will create a Dataframe by passing a dictionary of objects, during which the keys correspond to the column names and the values are the entries of the columns:
df = pd.DataFrame({'Value': [100000, 300000], 'date_construction': [1960, 2010]})
df.head()

As soon as the Dataframe is created, we are able to examine the kind of every column:
sort(df.Value),sort(df.date_construction)
(pandas.core.sequence.Sequence, pandas.core.sequence.Sequence)
It needs to be clear that columns are information buildings of sort Sequence.
Abstract capabilities
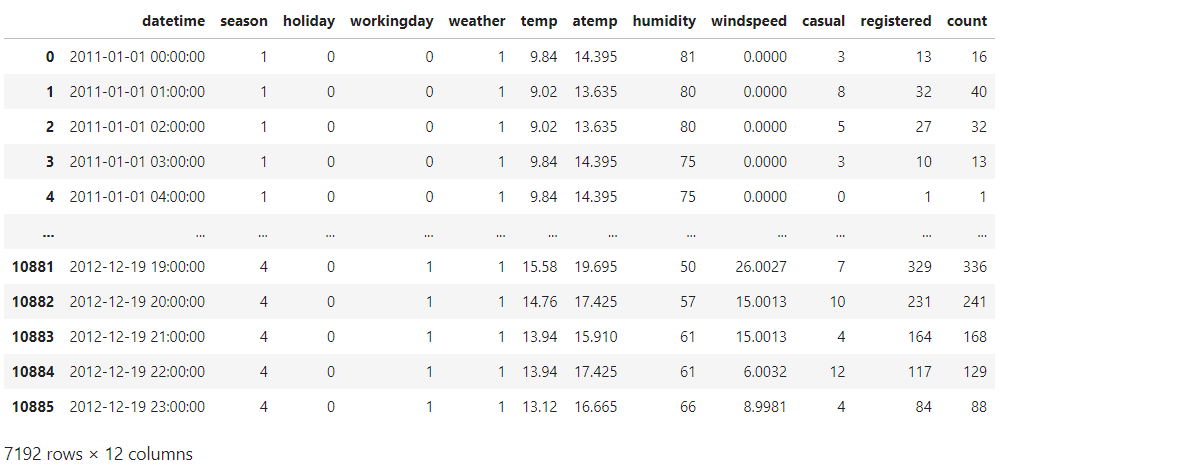
Any longer, we present the potentialities of Pandas by utilizing the bike sharing dataset, obtainable on Kaggle. We will import the CSV file within the following method:
df = pd.read_csv('/kaggle/enter/bike-sharing-demand/prepare.csv')
df.head()

Pandas doesn’t solely enable studying CSV information, but additionally Excel file, JSON, Parquet and different kinds of information. You will discover the complete record here.
From the output, we are able to visualise the primary 5 rows of the dataframe. If we wish to show the final 4 rows of the dataset, we use the tail() technique:

Few rows usually are not sufficient to have a good suggestion of the information now we have. A great way of beginning the evaluation is by trying on the form of the dataset:
We now have 10886 rows and 12 columns. Do you wish to see the column names? It’s very intuitive to do:

There’s a technique that permits to visualise all this data into a novel output:

If we wish to show the statistics of every column, we are able to use the describe technique:
It’s additionally necessary to extract data from the explicit fields. We will discover the distinctive values and the variety of distinctive values of the season column:
df.season.distinctive(),df.season.nunique()
Output:
We will see that the values are 1, 2, 3,4. Then, there are 4 potential values. This verification is essential to grasp the explicit variables and forestall potential noise contained within the column.
To show the frequency of every degree, we are able to use value_counts() technique:

The final step needs to be the inspection of the lacking values on every column:

Fortunately we don’t have any lacking worth in any of those fields.
Indexing and Slicing
Like in Numpy, there’s the index-based choice to pick information from the information construction. There are two major strategies to take entries from the dataframe:
- iloc selects the weather primarily based on the integer place
- loc takes the objects primarily based on labels or a boolean array.
To pick the primary row, iloc is the only option:

If we would like as a substitute to pick all of the rows and solely the second column, we are able to do the next:

It’s additionally potential to pick extra columns on the identical time:

It turns into advanced to pick the columns primarily based on the indices. It could be higher to specify the column names. That is potential utilizing loc:
df.loc[0:3,['datetime','season','holiday','temp']]

Equally to Numpy, it’s potential to filter the dataframe primarily based on circumstances. For instance, we wish to return all of the rows the place climate is the same as 1:
In case we wish to return an output with particular columns, we are able to use loc:
df.loc[df.weather==1,['season','holiday']]

Create new variables
The creation of latest variables has a big impact on extracting extra data from the information and bettering the interpretability. We will create a brand new categorical variable primarily based on the values of workingday:
df['workingday_c'] = df['workingday'].apply(lambda x: 'work' if x==1 else 'calm down')
df[['workingday','workingday_c']].head()

If there are multiple situation, it’s higher to map the values utilizing a dictionary and the tactic map:
diz_season = {1:'winter',2:'spring',3:'summer time',4:'fall'}
df['season_c'] = df['season'].map(lambda x: diz_season[x])
df[['season','season_c']].head()

Grouping and Sorting
It may well occur that you just wish to group the information primarily based on categorical column(s). That is potential utilizing groupby:
df.groupby('season_c').agg({'depend':['median','max']})

For every degree of the season, we are able to observe the median and the utmost depend of rented bikes. This output will be complicated with out ordering primarily based on a column. We will do it utilizing the sort_values() technique:
df.groupby('season_c').agg({'depend':['median','max']}).reset_index().sort_values(by=('depend', 'median'),ascending=False)

Now, the output makes extra sense. We will deduce that the very best variety of bikes rented is in summer time, whereas winter just isn’t an excellent month for renting bikes.
That’s it! I hope you’ve discovered this information helpful to be taught the fundamentals of NumPy and Pandas. They’re typically studied individually, however it may be insightful to grasp first NumPy after which Pandas, which is constructed on prime of NumPy.
There are absolutely strategies that I didn’t cowl throughout the tutorial, however the objective was to cowl crucial and well-liked strategies of those two libraries. The code will be discovered on Kaggle. Thanks for studying! Have a pleasant day!
Eugenia Anello is at the moment a analysis fellow on the Division of Info Engineering of the College of Padova, Italy. Her analysis challenge is targeted on Continuous Studying mixed with Anomaly Detection.
[ad_2]
Source link
