

[ad_1]
Giant language fashions (LLMs) have an ever-greater impression on how day by day lives and careers are altering as a result of they make attainable new functions like programming assistants and common chatbots. Nonetheless, the operation of those functions comes at a considerable price as a result of important {hardware} accelerator necessities, similar to GPUs. Latest research present that dealing with an LLM request may be costly, as much as ten occasions larger than a standard key phrase search. So, there’s a rising want to spice up the throughput of LLM serving programs to reduce the per-request bills.
Performing excessive throughput serving of huge language fashions (LLMs) requires batching sufficiently many requests at a time and the prevailing programs.
Nonetheless, current programs need assistance as a result of the key-value cache (KV cache) reminiscence for every request is big and might develop and shrink dynamically. It must be managed fastidiously, or when managed inefficiently, fragmentation and redundant duplication can vastly save this RAM, lowering the batch dimension.
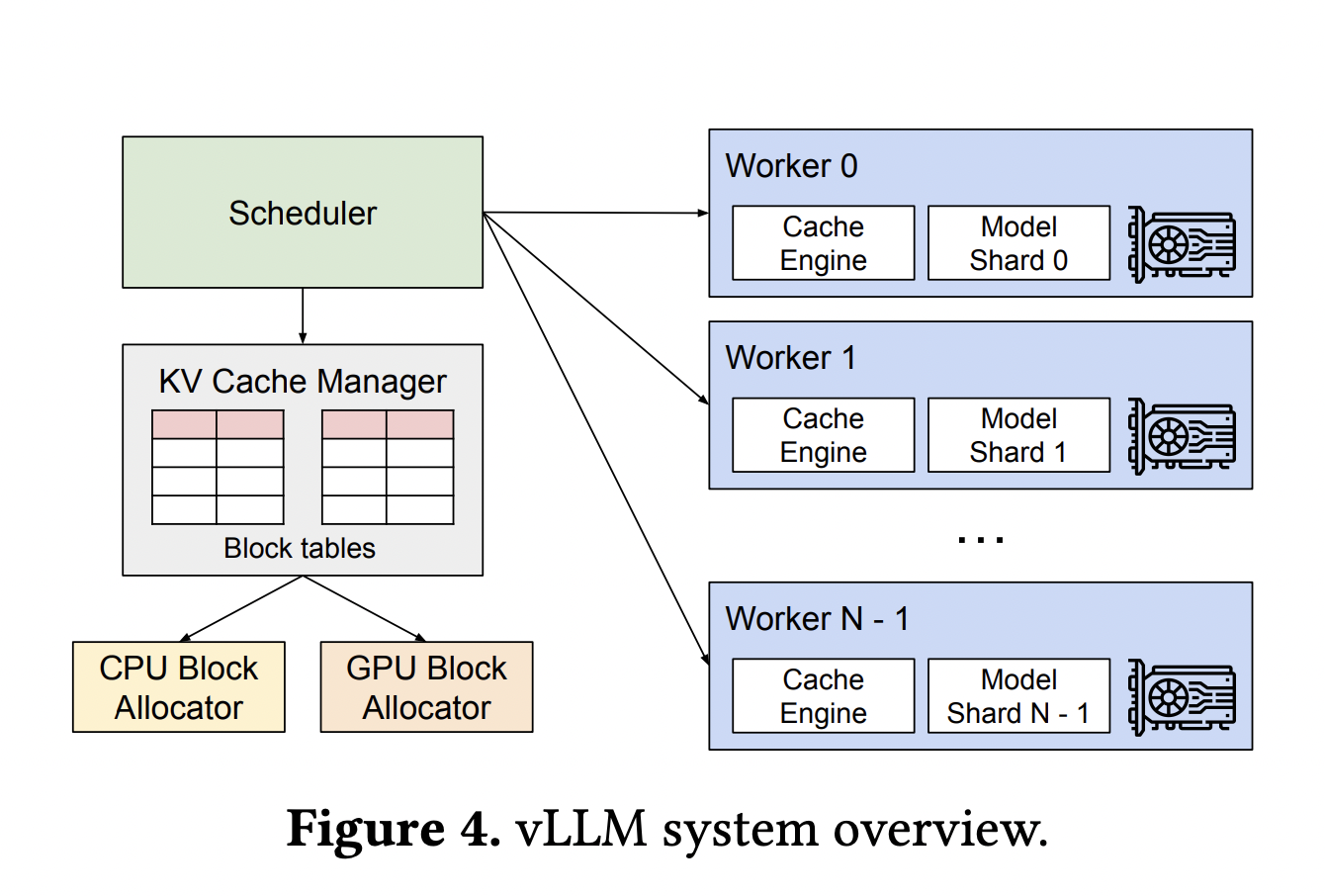
The researchers have steered PagedAttention, an consideration algorithm impressed by the standard digital reminiscence and paging methods in working programs, as an answer to this downside. To additional cut back reminiscence utilization, the researchers have additionally deployed vLLM. This LLM serving system offers nearly zero waste in KV cache reminiscence and versatile sharing of KV cache inside and between requests.
vLLM makes use of PagedAttention to handle consideration keys and values. By delivering as much as 24 occasions extra throughput than HuggingFace Transformers with out requiring any modifications to the mannequin structure, vLLM outfitted with PagedAttention redefines the present cutting-edge in LLM serving.
In contrast to standard consideration algorithms, they allow steady key and worth storage in non-contiguous reminiscence area. PagedAttention divides every sequence’s KV cache into blocks, every with the keys and values for a predetermined quantity of tokens. These blocks are effectively recognized by the PagedAttention kernel throughout the consideration computation. Because the blocks don’t essentially should be contiguous, the keys and values may be managed flexibly.
Reminiscence leakage occurs solely within the final block of a sequence inside PagedAttention. In sensible utilization, this results in efficient reminiscence utilization, with only a minimal 4% inefficiency. This enhancement in reminiscence effectivity allows higher GPU utilization.
Additionally, PagedAttention has one other key benefit of environment friendly reminiscence sharing. PageAttention’s memory-sharing operate significantly decreases the extra reminiscence required for sampling methods like parallel sampling and beam search. It may end up in a pace acquire of as much as 2.2 occasions whereas lowering their reminiscence utilization by as much as 55%. This enhancement makes these pattern methods helpful and efficient for Giant Language Mannequin (LLM) companies.
The researchers studied the accuracy of this technique. They discovered that with the identical quantity of delay as cutting-edge programs like FasterTransformer and Orca, vLLM will increase the throughput of well-known LLMs by 2-4. Bigger fashions, extra intricate decoding algorithms, and longer sequences end in a extra noticeable enchancment.
Try the Paper, Github, and Reference Article. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t neglect to affix our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
Rachit Ranjan is a consulting intern at MarktechPost . He’s at present pursuing his B.Tech from Indian Institute of Know-how(IIT) Patna . He’s actively shaping his profession within the area of Synthetic Intelligence and Information Science and is passionate and devoted for exploring these fields.
[ad_2]
Source link
