

[ad_1]
Even seemingly immobile pictures embody minute oscillations due to issues like wind, water currents, respiratory, or different pure rhythms. It’s because the pure world is continually in movement. People are particularly delicate to movement, which makes it probably the most outstanding visible alerts. Photos taken with out movement (and even with considerably fanciful movement) typically really feel unsettling or surreal. Nonetheless, it’s easy for folks to understand or image motion in a scene. Instructing a mannequin to amass sensible motion is extra complicated. The bodily dynamics of a scene, or the forces performing on issues resulting from their particular bodily traits, resembling their mass, elasticity, and so forth., produce the movement that folks see within the exterior world.
These forces and qualities are difficult to quantify and seize at scale, however fortunately, they incessantly don’t must be quantified since they might be caught and realized from the noticed movement. Though this observable movement is multi-modal and primarily based on intricate bodily processes, it’s incessantly predictable: candles flicker in particular patterns, and timber sway and ruffle their leaves. They will think about believable motions that may have been in progress when the image was taken or, if there might have been many doable such motions, a distribution of pure motions conditioned on that picture by taking a look at a nonetheless picture. This predictability is ingrained of their human notion of actual scenes.
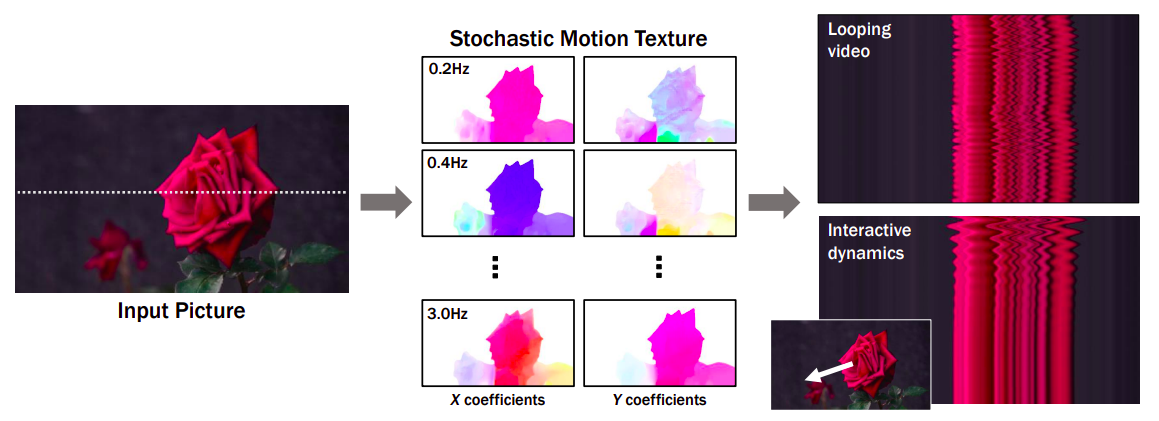
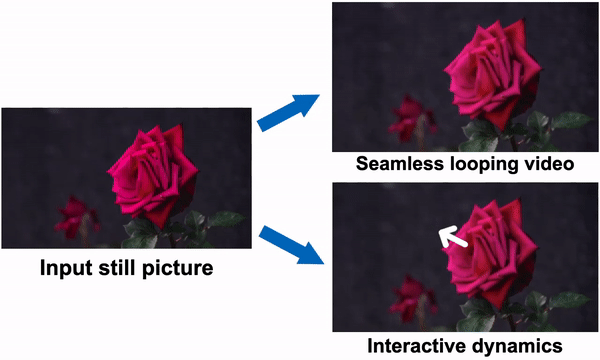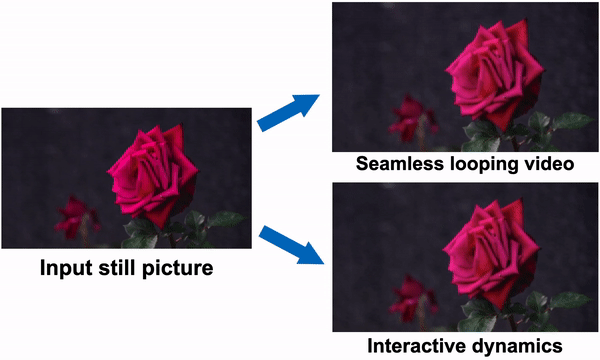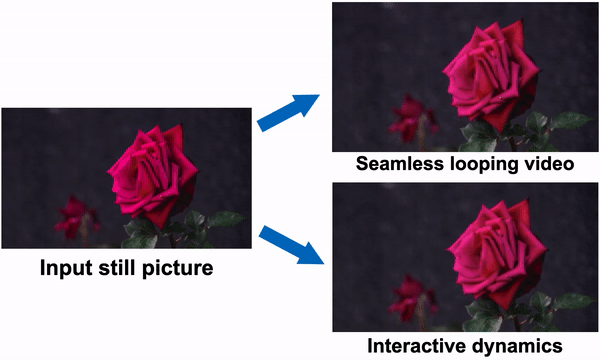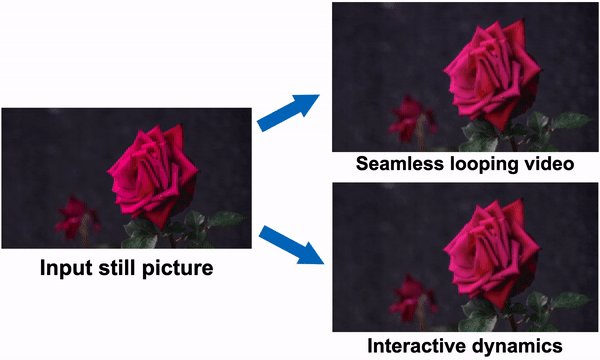
Determine 1: One can see how the tactic simulates a generative image-space previous to scene dynamics. Beginning with a single RGB image, the mannequin creates a neural stochastic movement texture, a movement illustration that simulates dense long-term movement trajectories within the Fourier area. They show how their movement priors could also be used for duties like changing a single picture right into a film that loops fluidly or mimicking object dynamics in response to interactive person stimulation (resembling dragging and releasing an object’s level). They use space-time X-t slices over 10 seconds of video (alongside the scanline displayed within the enter image) to visualise the output movies on the correct.
To simulate this related distribution digitally is a pure analysis topic, given how simply people can visualize these potential actions. We’ve now been capable of simulate extraordinarily wealthy and sophisticated distributions, together with distributions of actual photos conditioned on textual content, because of latest developments in generative fashions, notably conditional diffusion fashions. Quite a few beforehand impractical functions, together with the text-conditioned manufacturing of random, different, and sensible visible materials, have grow to be viable due to this capability. Latest analysis has demonstrated that modeling extra domains, resembling movies and 3D geometry, could also be equally useful for downstream functions in mild of the success of those image fashions.
On this paper, researchers from Google Analysis examine the modeling of a generative prior for the movement of each pixel in a single picture, often known as scene movement in picture house. This mannequin is educated utilizing movement trajectories routinely retrieved from a large variety of real video sequences. The educated mannequin forecasts a neural stochastic movement texture primarily based on an enter image, a set of movement foundation coefficients that describe the long run trajectory of every pixel. They decide the Fourier collection as their foundation capabilities to restrict their evaluation to real-world sceneries with oscillating dynamics, resembling timber and flowers transferring within the wind. They forecast a neural stochastic movement texture utilizing a diffusion mannequin that produces coefficients for a single frequency at a time however coordinates these predictions throughout frequency bands.
As proven in Fig. 1, the generated frequency-space textures could also be transformed into dense, long-range pixel movement trajectories that synthesize upcoming frames with an image-based rendering diffusion mannequin, changing static photos into lifelike animations. Priors over movement seize have a extra primary, lower-dimensional underlying construction than priors over uncooked RGB pixels, which extra successfully explains fluctuations in pixel values. In distinction to earlier methods that accomplish visible animation utilizing uncooked video synthesis, their movement illustration permits extra coherent long-term manufacturing and finer-grained management over animations. Moreover, they present how their generated movement illustration makes it straightforward to make use of for numerous downstream functions, together with making movies that seamlessly loop, enhancing the induced movement, and enabling interactive dynamic pictures that simulate how an object would react to user-applied forces.
Try the Paper and Project. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t neglect to affix our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at the moment pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is captivated with constructing options round it. He loves to attach with folks and collaborate on fascinating initiatives.
[ad_2]
Source link
