

[ad_1]
Have you ever ever encountered illusions the place a child within the picture seems to be taller and greater than an grownup? Ames room phantasm is a well-known one which entails a room that’s formed like a trapezoid, with one nook of the room nearer to the viewer than the opposite nook. Once you take a look at it from a sure level, objects within the room look regular, however as you progress to a distinct place, all the pieces modifications in dimension and form, and it may be tough to know what’s near you and what’s not.
Although, it is a drawback for us people. Usually, after we take a look at a scene, we estimate the depth of objects fairly precisely if there are not any phantasm methods. Computer systems, alternatively, aren’t that profitable at depth estimation as it’s nonetheless a basic drawback in laptop imaginative and prescient.
Depth Estimation is the method of figuring out the gap between the digicam and the objects within the scene. Depth estimation algorithms take a picture or a sequence of photos as enter and output a corresponding depth map or 3D illustration of the scene. This is a crucial job as we have to perceive the depth of the scene in quite a few functions like robotics, autonomous automobiles, digital actuality, augmented actuality, and many others. For instance, if you wish to have a secure autonomous driving automotive, understanding the gap to the automotive in entrance of you is essential to regulate the driving velocity.
There are two branches of depth estimation algorithms, metric depth estimation (MDE), the place the purpose is to estimate absolutely the distance, and relative depth estimation (RDE), the place the purpose is to estimate the relative distance between the objects within the scene.
MDE fashions are helpful for mapping, planning, navigation, object recognition, 3D reconstruction, and picture modifying. Nevertheless, the efficiency of MDE fashions can deteriorate when coaching a single mannequin throughout a number of datasets, particularly if the pictures have giant variations in depth scale (e.g., indoor and outside photos). Because of this, present MDE fashions typically overfit particular datasets and don’t generalize effectively to different datasets.
RDE fashions, alternatively, use disparity as a method of supervision. The depth predictions in RDE are solely constant relative to one another throughout picture frames, and the dimensions issue is unknown. This enables RDE strategies to be skilled on a various set of scenes and datasets, even together with 3D motion pictures, which may help enhance mannequin generalizability throughout domains. Nevertheless, the trade-off is that the expected depth in RDE doesn’t have a metric that means, which limits its functions.
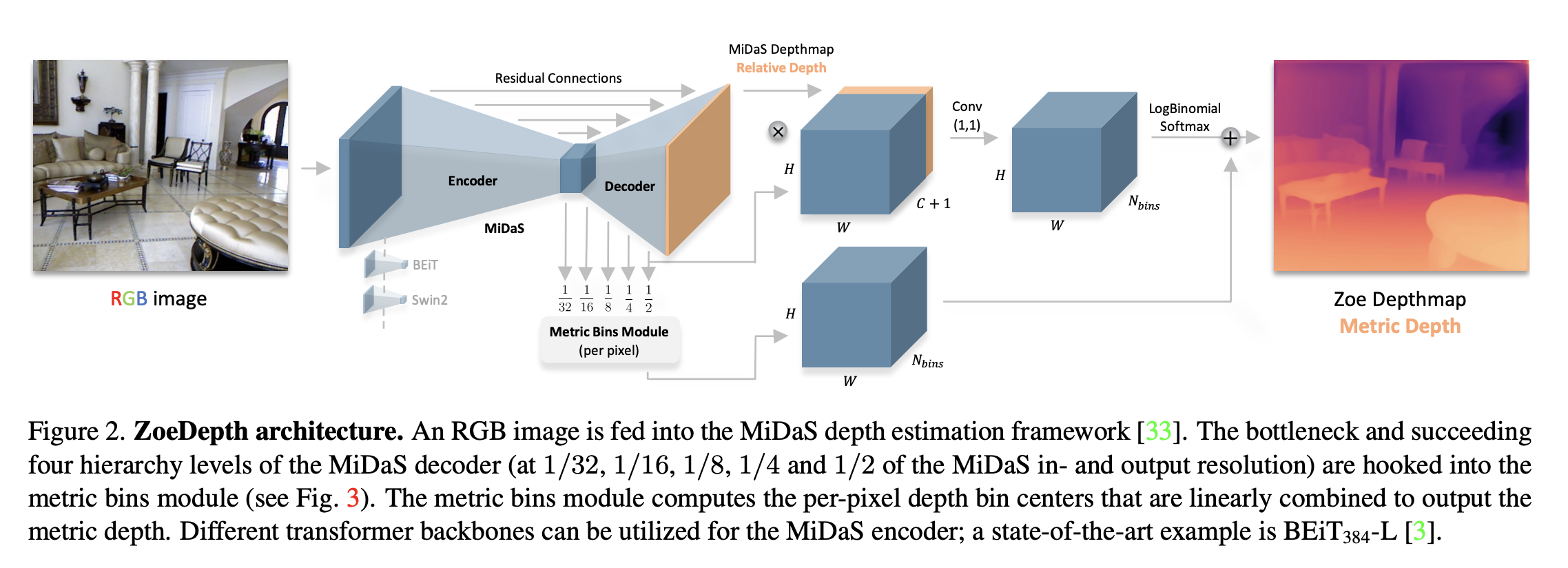
What would occur if we mixed these two approaches? We are able to have a depth estimation mannequin that may generalize effectively to totally different domains whereas nonetheless sustaining an correct metric scale. That is precisely what ZoeDepth has achieved.
ZoeDepth is a two-stage framework that mixes each MDE and RDE approaches. The primary stage consists of an encoder-decoder construction that’s skilled to estimate relative depths. This mannequin is skilled on a big number of datasets which improves the generalization. The second stage provides parts answerable for estimating metric depth are added as an extra head.
The metric head design used on this strategy is predicated on a way known as the metric bins module, which estimates a set of depth values for every pixel quite than a single depth worth. This enables the mannequin to seize a variety of attainable depth values for every pixel, which may help enhance its accuracy and robustness. This allows an correct depth measurement that considers the bodily distance between objects within the scene. These heads are skilled on metric depth datasets and are light-weight in comparison with the primary stage.
Relating to inference, a classifier mannequin selects the suitable head for every picture utilizing encoder options. This enables the mannequin to concentrate on estimating depth for particular domains or sorts of scenes whereas nonetheless benefiting from the relative depth pre-training. In the long run, we get a versatile mannequin that can be utilized in a number of configurations.
Try the Paper and Github. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t overlook to hitch our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
Ekrem Çetinkaya obtained his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin College, Istanbul, Türkiye. He wrote his M.Sc. thesis about picture denoising utilizing deep convolutional networks. He’s presently pursuing a Ph.D. diploma on the College of Klagenfurt, Austria, and dealing as a researcher on the ATHENA challenge. His analysis pursuits embody deep studying, laptop imaginative and prescient, and multimedia networking.
[ad_2]
Source link
