

[ad_1]
Understanding a holistic 3D image is a major problem for autonomous automobiles (AV) to understand. It immediately influences later actions like planning and map creation. The shortage of sensor decision and the partial commentary brought on by the small sight view and occlusions make it difficult to get exact and complete 3D details about the precise setting. Semantic scene completion (SSC), a way for collectively inferring the entire scene geometry and semantics from sparse observations, was supplied to resolve the issues. Scene reconstruction for viewable areas and scene hallucination for obstructed sections are two subtasks an SSC resolution should deal with concurrently. People readily cause about scene geometry and semantics based mostly on imperfect observations, which helps this endeavor.
However, trendy SSC strategies nonetheless lag under human notion in driving eventualities when it comes to efficiency. LiDAR is considered a foremost modality by most present SSC programs to supply exact 3D geometric measurements. But, cameras are extra reasonably priced and provide higher visible indications of the driving setting, however LiDAR sensors are extra expensive and fewer moveable. This impressed the investigation of camera-based SSC options, which had been initially put forth within the ground-breaking work of MonoScene. MonoScene makes use of dense characteristic projection to transform 2D image inputs to 3D. But, such a projection provides empty or occluded voxels 2D traits from the viewable areas. An empty voxel lined by a automobile, as an illustration, will however obtain the visible attribute of the car.
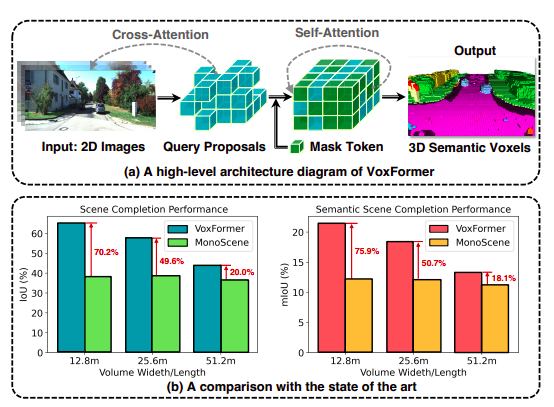
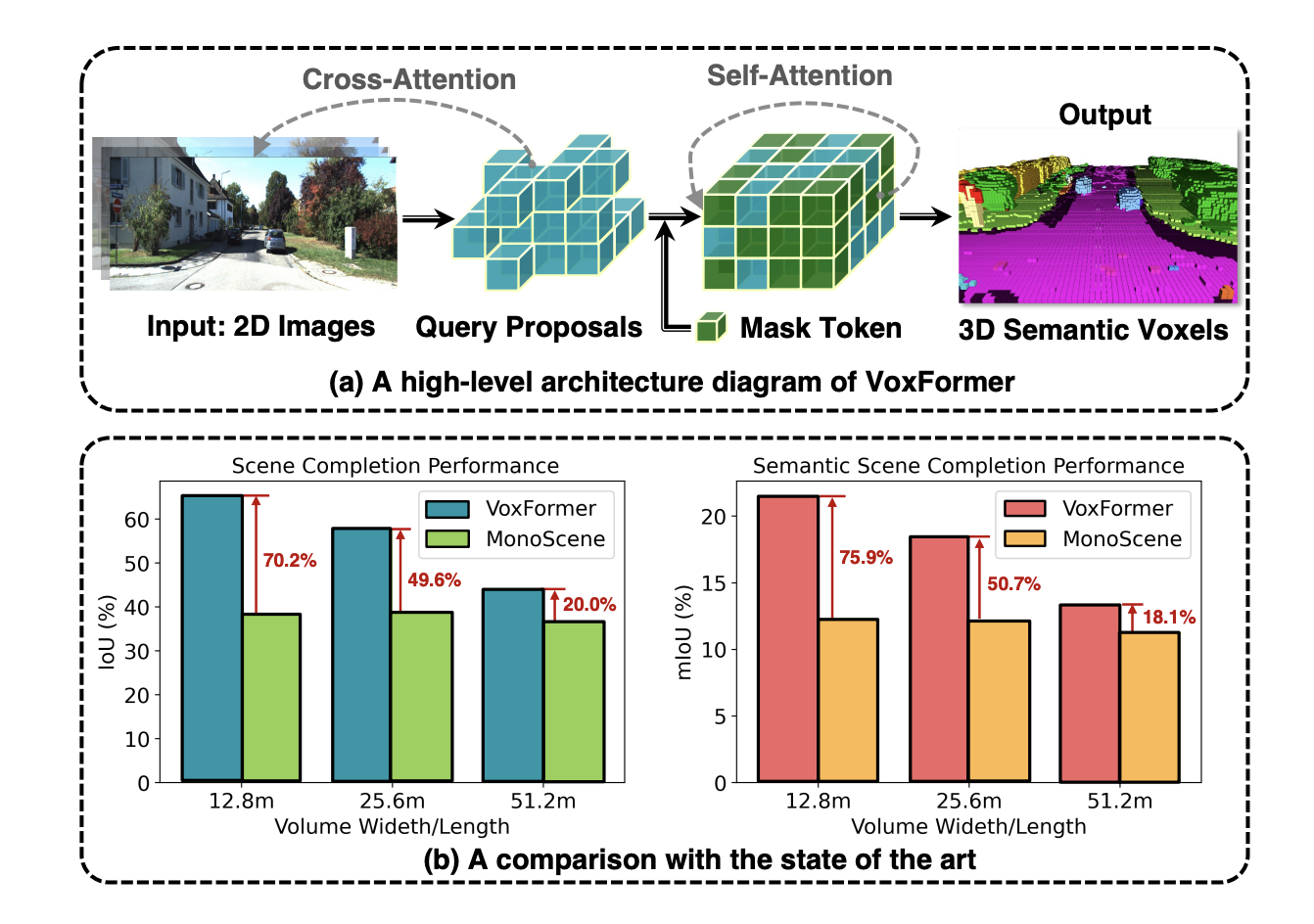
In consequence, the 3D options created have poor efficiency concerning geometric completeness and semantic segmentation—their involvement. VoxFormer, in distinction to MonoScene, views 3D-to-2D cross-attention as a illustration of sparse queries. The prompt design is impressed by two realizations: (1) sparsity in 3-D house: Since a good portion of 3-D house is often empty, a sparse illustration fairly than a dense one is undoubtedly more practical and scalable. (2) reconstruction-before-hallucination: The 3D info of the non-visible area will be higher accomplished utilizing the reconstructed seen areas as beginning factors.
Briefly, they made the next contributions to this effort:
• A cutting-edge two-stage system that transforms photographs into an entire 3D voxelized semantic scene.
• An progressive 2D convolution-based question proposal community that produces reliable inquiries from image depth.
• A novel Transformer that produces a full 3D scene illustration and is akin to the masked autoencoder (MAE).
• As seen in Fig. 1(b), VoxFormer advances the state-of-the-art camera-based SSC .
VoxFormer contains two phases: stage 1 suggests a sparse set of occupied voxels, and stage 2 completes the scene representations starting from stage 1’s suggestions. Stage 1 is class-agnostic, whereas stage 2 is class-specific. As illustrated in Fig. 1(a), Stage-2 is constructed on a singular sparse-to-dense MAE-like design. Specifically, stage-1 incorporates a light-weight 2D CNN-based question proposal community that reconstructs the scene geometry utilizing image depth. Then, all through the entire sight view, it suggests a sparse assortment of voxels utilizing preset learnable voxel queries.
They first strengthen their featurization by enabling the prompt voxels to concentrate to the image observations. The remaining voxels will then be processed by self-attention to complete the scene representations for per-voxel semantic segmentation after the non-proposed voxels are linked to a learnable masks token. VoxFormer supplies state-of-the-art geometric completion and semantic segmentation efficiency, based on intensive experiments on the large-scale SemanticKITTI dataset. Extra critically, as demonstrated in Fig. 1, the advantages are giant in safety-critical short-range areas.
Try the Paper and Github. All Credit score For This Analysis Goes To the Researchers on This Undertaking. Additionally, don’t overlook to hitch our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at the moment pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Expertise(IIT), Bhilai. He spends most of his time engaged on tasks aimed toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is enthusiastic about constructing options round it. He loves to attach with folks and collaborate on fascinating tasks.
[ad_2]
Source link
