

[ad_1]
Within the realm of video content material group, the segmentation of prolonged movies into chapters emerges as an vital functionality, permitting customers to pinpoint their desired data swiftly. Sadly, this topic has suffered from hardly any analysis consideration as a result of shortage of publicly out there datasets.
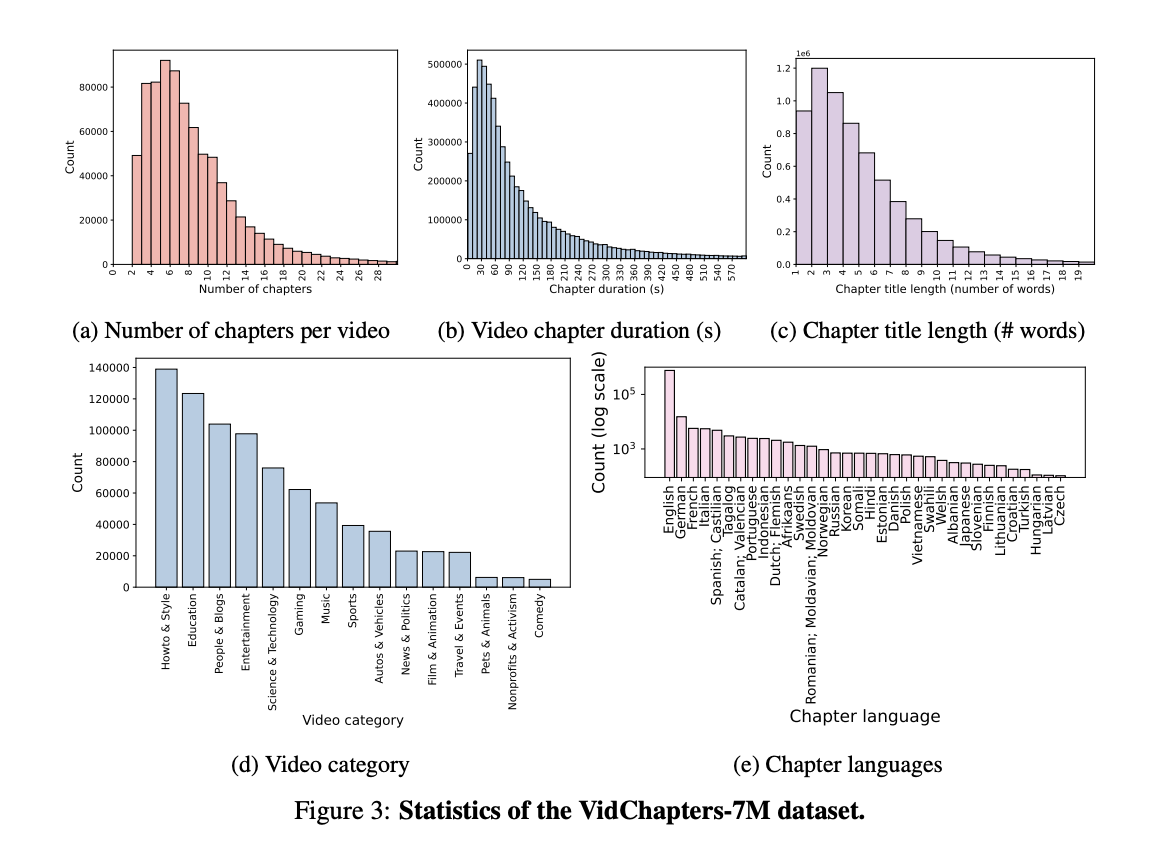
To deal with this problem, VidChapters-7M is introduced, a dataset comprising 817,000 movies which have been meticulously segmented into a powerful 7 million chapters. This dataset is assembled routinely by extracting user-annotated chapters from on-line movies, bypassing the necessity for labor-intensive handbook annotation.
Throughout the scope of VidChapters-7M, researchers have launched three distinct duties. Firstly, there’s the video chapter technology job, which entails the temporal division of a video into segments, accompanied by the technology of a descriptive title for every phase. To additional deconstruct this job, two variations are outlined: video chapter technology with predefined phase boundaries, the place the problem lies in producing titles for segments with annotated boundaries, and video chapter grounding, which necessitates the localization of a chapter’s temporal boundaries primarily based on its annotated title.

A complete analysis of those duties was carried out that employed each elementary baseline approaches and cutting-edge video-language fashions. The above picture demonstrates an illustration of the three duties outlined for VidChapters-7M. Moreover, it has been demonstrated that pre-training on VidChapters-7M ends in outstanding developments in dense video captioning duties, each in zero-shot and fine-tuning situations. This development notably elevates the cutting-edge on benchmark datasets akin to YouCook2 and ViTT. In the end, the experiments have unveiled a optimistic correlation between the scale of the pretraining dataset and improved efficiency in downstream functions.
VidChapters-7M inherits sure limitations as a consequence of its origin from YT-Temporal-180M. These limitations are related to the biases within the distribution of video classes which can be current within the supply dataset. The development of video chapter technology fashions has the potential to facilitate downstream functions, a few of which might have destructive societal impacts, akin to video surveillance.
Moreover, fashions skilled on VidChapters-7M could inadvertently mirror biases that exist inside movies sourced from platforms like YouTube. It’s mandatory to take care of consciousness of those concerns when deploying, analyzing, or constructing upon these fashions.
Try the Paper, Github, and Project. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t overlook to affix our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming information scientist and has been working on the planet of ml/ai analysis for the previous two years. She is most fascinated by this ever altering world and its fixed demand of people to maintain up with it. In her pastime she enjoys touring, studying and writing poems.
[ad_2]
Source link
