

[ad_1]
Knowledge analytics has experienced remarkable growth in recent years, pushed by developments in how knowledge is utilized in key decision-making processes. The gathering, storage, and evaluation of information have additionally progressed considerably attributable to these developments. Furthermore, the demand for expertise in knowledge analytics has skyrocketed, turning the job market right into a extremely aggressive enviornment for people possessing the mandatory abilities and expertise.
The speedy growth of data-driven applied sciences has correspondingly led to an elevated demand for specialised roles, comparable to “knowledge engineer.” This surge in demand extends past knowledge engineering alone and encompasses associated positions like knowledge scientist and knowledge analyst.
Recognizing the importance of those professions, our collection of weblog posts goals to gather real-world knowledge from on-line job postings and analyze it to grasp the character of the demand for these jobs, in addition to the varied ability units required inside every of those classes.
On this weblog, we introduce a browser-based “Data Analytics Job Trends” utility for the visualization and evaluation of job tendencies within the knowledge analytics market. After scraping knowledge from on-line job businesses, it makes use of NLP strategies to determine key ability units required within the job posts. Determine 1 exhibits a snapshot of the info app, exploring tendencies within the knowledge analytics job market.

Determine 1: Snapshot of the KNIME Data App “Data Analytics Job Trends”
For the implementation, we adopted the low-code knowledge science platform: KNIME Analytics Platform. This open-source and free platform for end-to-end knowledge science relies on visible programming and gives an intensive vary of functionalities, from pure ETL operations and a wide selection of information supply connectors for knowledge mixing by to machine studying algorithms, together with deep studying.
The set of workflows underlying the appliance is obtainable totally free obtain from the KNIME Community Hub at “Data Analytics Job Trends”. A browser-based occasion will be evaluated at “Data Analytics Job Trends”.
This utility is generated by 4 workflows proven in Determine 2 to be executed sequentially for the next sequence of steps:
- Internet scraping for knowledge assortment
- NLP parsing and knowledge cleansing
- Subject modeling
- Evaluation of attribution of job position – abilities
The workflows can be found on the KNIME Community Hub Public House – Data Analytics Job Trends.

Determine 2: KNIME Group Hub House – Data Analytics Job Trends comprises a set of 4 workflows used for constructing the appliance “Knowledge Analytics Job Tendencies”
- “01_Web Scraping for knowledge assortment” workflow crawls by the net job postings and extracts the textual info right into a structured format
- “02_NLP Parsing and cleansing” workflow performs the mandatory cleansing steps after which parses the lengthy texts into smaller sentences
- “03_Topic Modeling and Exploration Knowledge App” makes use of clear knowledge to construct a subject mannequin after which to visualise its outcomes inside a knowledge app
- “04_Job Ability Attribution” workflow evaluates the affiliation of abilities throughout job roles, like Knowledge Scientist, Knowledge Engineer, and Knowledge Analyst, based mostly on the LDA outcomes.
Internet scraping for knowledge assortment
In an effort to have an up-to-date understanding of the talents required within the job market, we opted for the evaluation of internet scraping job posts from on-line job businesses. Given the regional variations and the range of languages, we centered on job postings in the USA. This ensures {that a} vital proportion of the job postings are offered within the English language. We additionally centered on job postings from February 2023 to April 2023.
The KNIME workflow ”01_Web Scraping for Data Collection” in Determine 3 crawls by an inventory of URLs of searches on job businesses’ web sites.
To extract the related job postings pertaining to Knowledge Analytics, we used searches with six key phrases that collectively cowl the sector of information analytics, specifically: “huge knowledge”, “knowledge science”, “enterprise intelligence”, “knowledge mining”, “machine studying” and “knowledge analytics”. Search key phrases are saved in an Excel file and skim by way of the Excel Reader node.
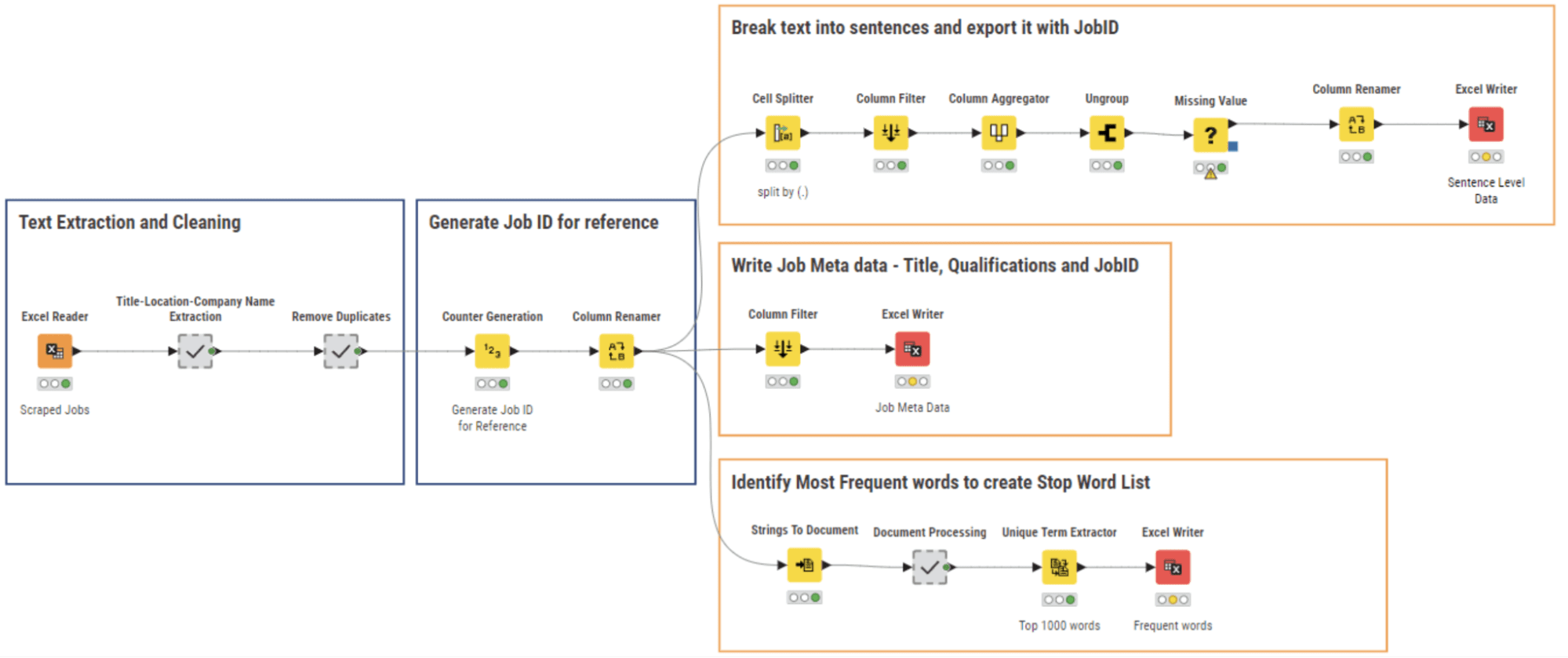
Determine 3: KNIME Workflow “01_Web Scraping for Data Collection” scraps job postings in accordance with various search URLs
The core node of this workflow is the Webpage Retriever node. It’s used twice. The primary time (outer loop), the node crawls the location in accordance with the key phrase supplied as enter and produces the associated record of URLs for job postings revealed within the US inside the final 24 hours. The second time (interior loop), the node retrieves the textual content content material from every job posting URL. The Xpath nodes following the Webpage Retriever nodes parse the extracted texts to achieve the specified info, comparable to job title, required {qualifications}, job description, wage, and firm rankings. Lastly, the outcomes are written to an area file for additional evaluation. Determine 4 exhibits a pattern of the job postings scraped for February 2023.

Determine 4: Pattern of the Internet Scraping Outcomes for February 2023
NLP parsing and knowledge cleansing
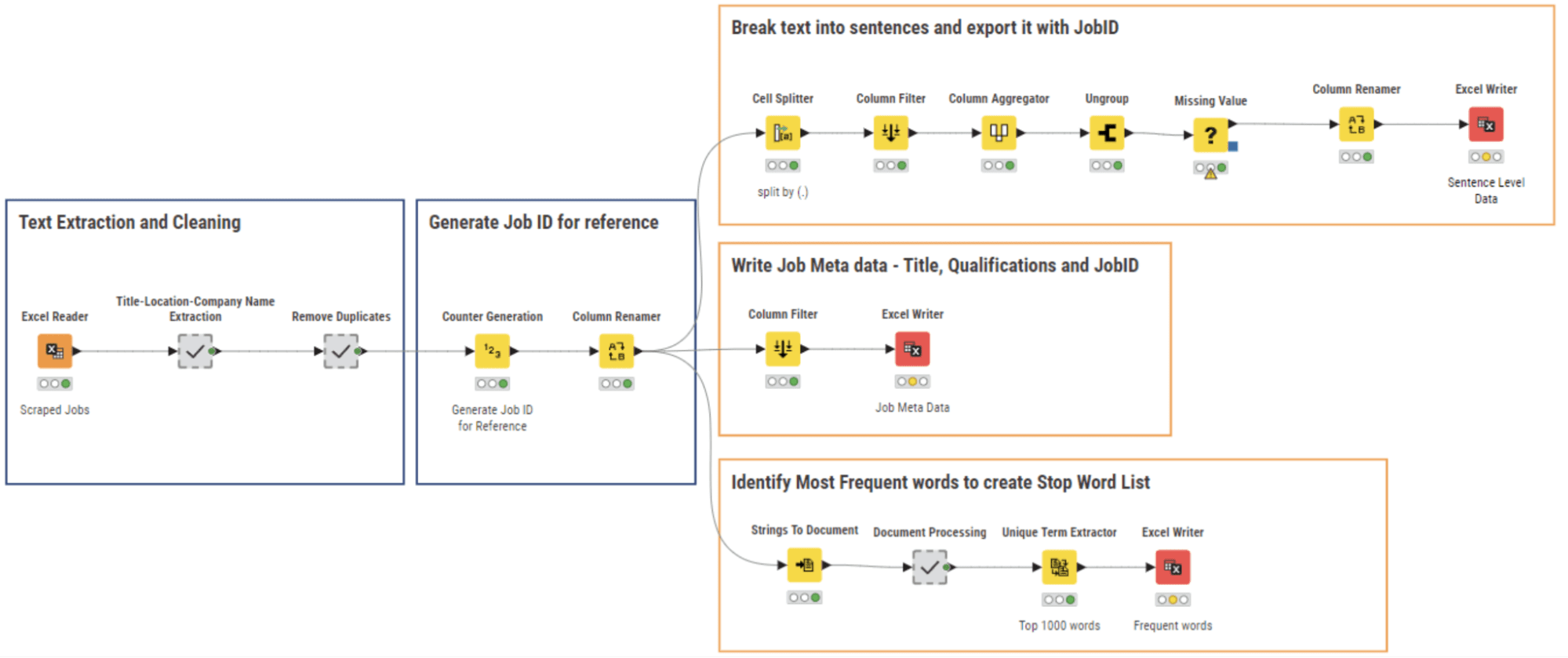
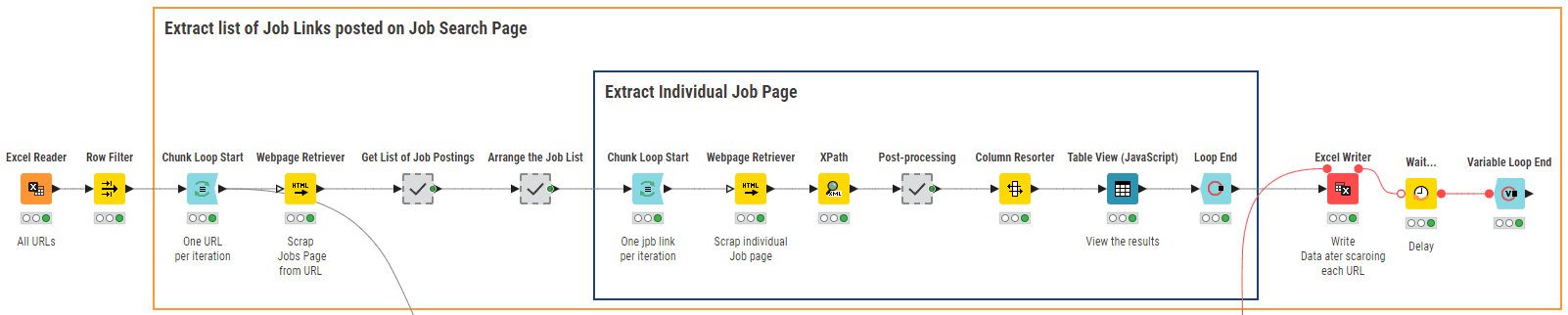
Determine 5: 02_NLP Parsing and cleaning Workflow for Textual content Extraction and Knowledge Cleansing
Like all freshly collected knowledge, our internet scraping outcomes wanted some cleansing. We carry out NLP parsing together with knowledge cleansing and write the respective knowledge recordsdata utilizing the workflow 02_NLP Parsing and cleaning proven in Determine 5.
A number of fields from the scraped knowledge have been saved within the type of a concatenation of string values. Right here, we extracted the person sections utilizing a collection of String Manipulation nodes inside the meta node ”Title-Location-Firm Identify Extraction” after which we eliminated pointless columns and removed duplicate rows.
We then assigned a novel ID to every job posting textual content and fragmented the entire doc into sentences by way of the Cell Splitter node. The meta info for every job – title, location, and firm – was additionally extracted and saved together with the Job ID.
The record of essentially the most frequent 1000 phrases was extracted from all paperwork, in order to generate a stop-word record, together with phrases like “applicant”, “collaboration”, “employment” and so forth … These phrases are current in each job posting and subsequently don’t add any info for the following NLP duties.
The results of this cleansing section is a set of three recordsdata:
– A desk containing the paperwork’ sentences;
– A desk containing the job description metadata;
– A desk containing the stopword record.
Subject modeling and outcomes exploration
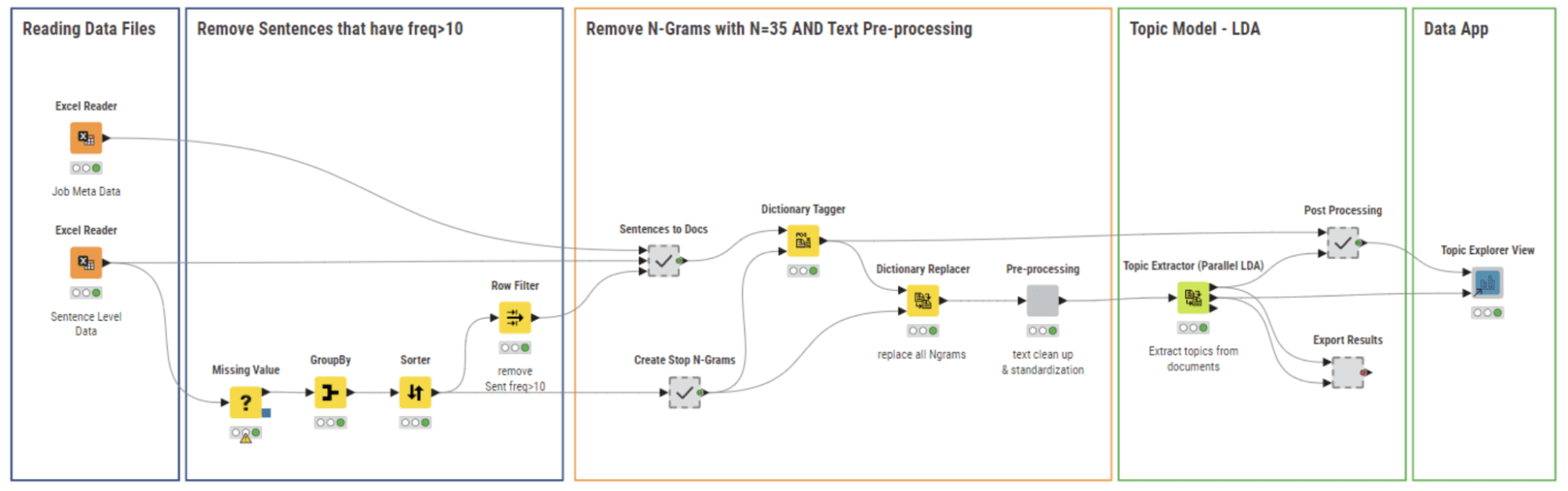
Determine 6: 03_Topic Modeling and Exploration Data App workflow builds a subject mannequin and permits the person to discover the outcomes visually with the Topic Explorer View Element
The workflow 03_Topic Modeling and Exploration Data App (Determine 6) makes use of the cleaned knowledge recordsdata from the earlier workflow. On this stage, we goal to:
- Detect and take away frequent sentences (Cease Phrases) showing in lots of job postings
- Carry out customary textual content processing steps to organize the info for matter modeling
- Construct the Subject Mannequin and Visualize the Outcomes.
We talk about the above duties intimately within the following subsections.
3.1 Take away cease phrases with N-grams
Many job postings embrace sentences which are generally present in firm insurance policies or common agreements, comparable to “Non-Discrimination coverage” or “Non-Disclosure Agreements.” Determine 7 offers an instance the place job postings 1 and a couple of point out the “Non-Discrimination” coverage. These sentences usually are not related to our evaluation and subsequently should be faraway from our textual content corpus. We check with them as “Cease Phrases” and make use of two strategies to determine and filter them.
The primary methodology is simple: we calculate the frequency of every sentence in our corpus and eradicate any sentences with a frequency better than 10.
The second methodology includes an N-gram strategy, the place N will be within the vary of values from 20 to 40. We choose a worth for N and assess the relevance of N-grams derived from the corpus by counting the variety of N-grams that classify as cease phrases. We repeat this course of for every worth of N inside the vary. We selected N=35 as the perfect worth for N to determine the best variety of Cease Phrases.

Determine 7: Instance of Widespread Sentences in Job Postings that may be thought to be “Cease Phrases”
We used each strategies to take away the “Cease Phrases” as proven by the workflow depicted in Determine 7. At first, we eliminated essentially the most frequent sentences, then we created N-grams with N=35 and tagged them in each doc with the Dictionary Tagger node, and, finally, we eliminated these N-grams utilizing the Dictionary Replacer node.
3.2 Put together knowledge for matter modeling with textual content preprocessing strategies
After eradicating the Cease Phrases, we carry out the usual textual content preprocessing as a way to put together the info for matter modeling.
First, we eradicate numeric and alphanumeric values from the corpus. Then, we take away punctuation marks and customary English cease phrases. Moreover, we use the customized cease glossary that we created earlier to filter out job domain-specific cease phrases. Lastly, we convert all characters to lowercase.
We determined to concentrate on the phrases that carry significance, which is why we filtered the paperwork to hold solely nouns and verbs. This may be completed by assigning a Elements of Speech (POS) tag to every phrase within the doc. We make the most of the POS Tagger node to assign these tags and filter them based mostly on their worth, particularly holding phrases with POS = Noun and POS = Verb.
Lastly, we apply Stanford lemmatization to make sure the corpus is prepared for matter modeling. All of those preprocessing steps are carried out by the “Pre-processing” part proven in Determine 6.
3.3 Construct matter mannequin and visualize it
Within the ultimate stage of our implementation, we utilized the Latent Dirichlet Allocation (LDA) algorithm to assemble a subject mannequin utilizing the Topic Extractor (Parallel LDA) node proven in Determine 6. The LDA algorithm produces various matters (okay), every matter described by a (m) variety of key phrases. Parameters (okay,m) have to be outlined.
As a aspect be aware, okay and m can’t be too giant, since we wish to visualize and interpret the matters (ability units) by reviewing the key phrases (abilities) and their respective weights. We explored a spread [1, 10] for okay and glued the worth of m=15. After cautious evaluation, we discovered that okay=7 led to essentially the most various and distinct matters with a minimal overlap in key phrases. Thus, we decided okay=7 to be the optimum worth for our evaluation.
Discover Subject Modeling Outcomes with an Interactive Knowledge App
To allow everybody to entry the subject modeling outcomes and have their very own go at it, we deployed the workflow (in Determine 6) as a Data App on KNIME Business Hub and made it public, for everybody to entry it. You may test it out at: Data Analytics Job Trends.
The visible a part of this knowledge app comes from the Topic Explorer View part by Francesco Tuscolano and Paolo Tamagnini, obtainable totally free obtain from the KNIME Community Hub, and offers various interactive visualizations of matters by matter and doc.
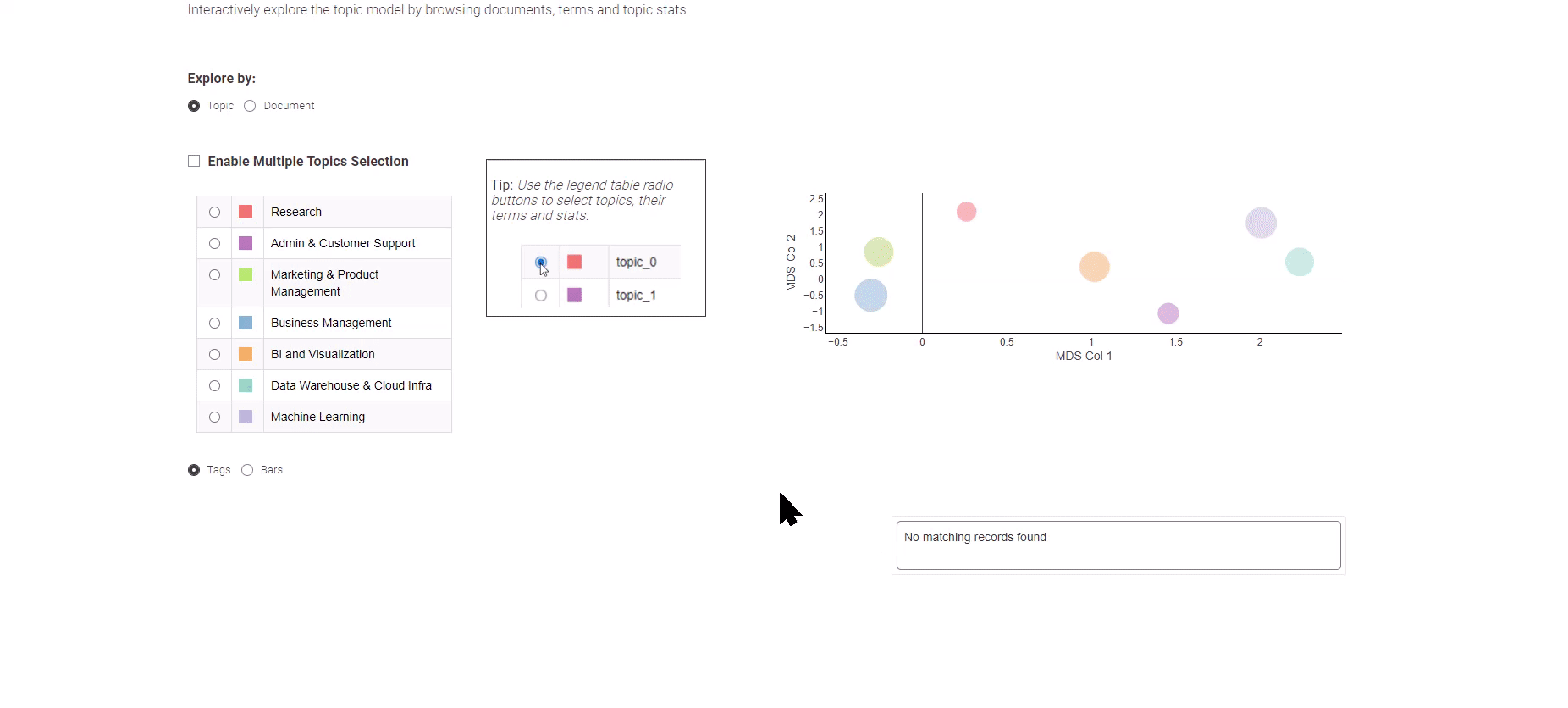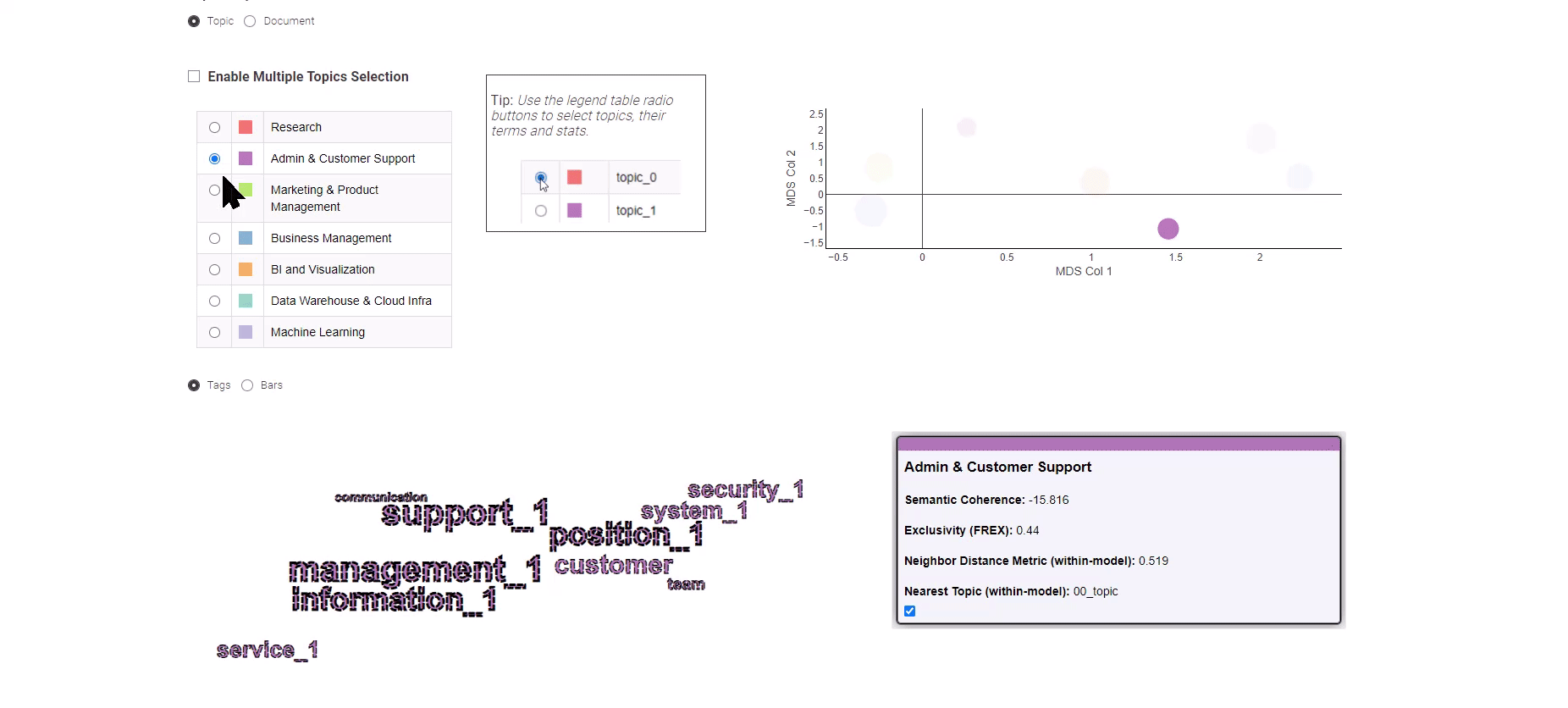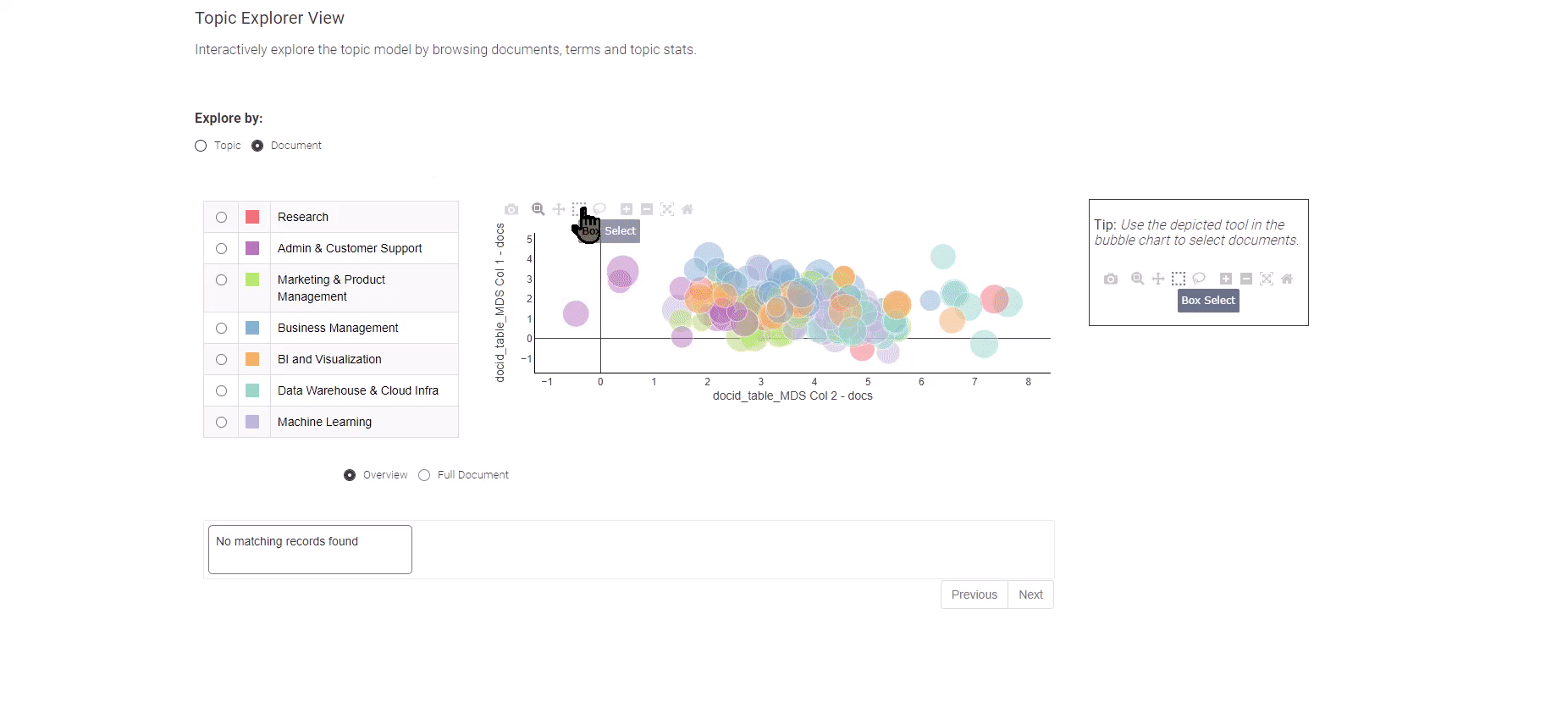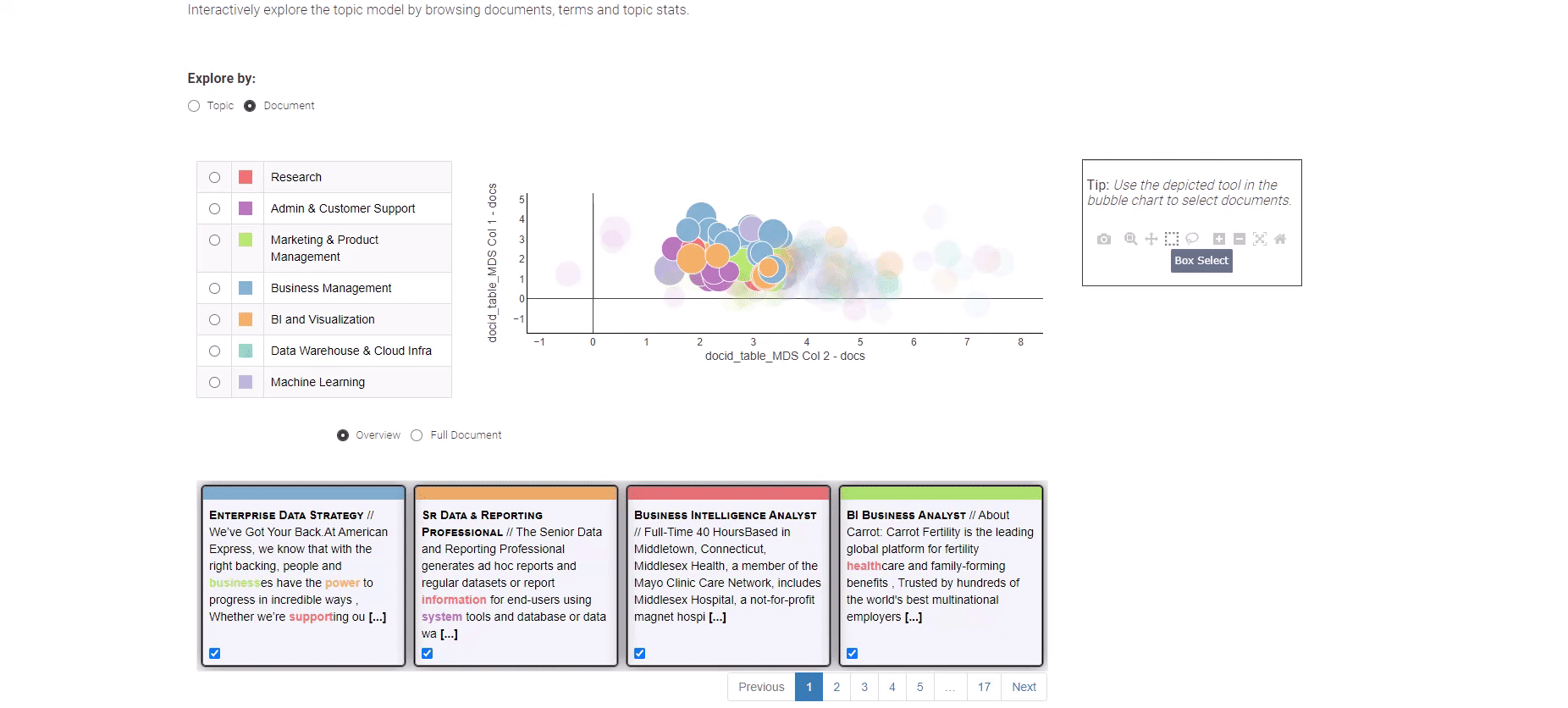
Determine 8: Data Analytics Job Trends for exploration of the subject modeling outcomes
Introduced in Determine 8, this Knowledge App gives you a alternative between two distinct views: the “Subject” and the “Doc” view.
The “Subject” view employs a Multi-Dimensional Scaling algorithm to painting matters on a 2-dimensional plot, successfully illustrating the semantic relationships between them. On the left panel, you possibly can conveniently choose a subject of curiosity, prompting the show of its corresponding prime key phrases.
To enterprise into the exploration of particular person job postings, merely go for the “Doc” view. The “Doc” view presents a condensed portrayal of all paperwork throughout two dimensions. Make the most of the field choice methodology to pinpoint paperwork of significance, and on the backside, an summary of your chosen paperwork awaits
We’ve got supplied right here a abstract of the “Knowledge Analytics Job Tendencies” utility, that was applied and used to discover the newest ability necessities and job roles within the knowledge science job market. For this weblog, we restricted our space of motion to job descriptions for the US, written in English, from February to April 2023.
To grasp the job tendencies and supply a overview, the “Data Analytics Job Trends” crawls job company websites, extracts textual content from on-line job postings, extracts matters and key phrases after performing a collection of NLP duties, and eventually visualizes the outcomes by matter and by doc to discern the patterns within the knowledge.
The applying consists of a set of 4 KNIME workflows to run sequentially for internet scraping, knowledge processing, matter modeling, after which interactive visualizations to permit the person to identify the job tendencies.
We deployed the workflow on KNIME Business Hub and made it public, so everybody can entry it. You may test it out at: Data Analytics Job Trends.
The complete set of workflows is obtainable and free to obtain from KNIME Group Hub at Data Analytics Job Trends. The workflows can simply be modified and tailored to find tendencies in different fields of the job market. It is sufficient to change the record of search key phrases within the Excel file, the web site, and the time vary for the search.
What in regards to the outcomes? That are the talents and the skilled roles most wanted in at present’s knowledge science job market? In our subsequent weblog publish, we’ll information you thru the exploration of the outcomes of this matter modeling. Collectively, we’ll intently study the intriguing interaction between job roles and abilities, gaining useful insights in regards to the knowledge science job market alongside the best way. Keep tuned for an enlightening exploration!
Assets
- A Systematic Review of Data Analytics Job Requirements and Online Courses by A. Mauro et al.
Andrea De Mauro has over 15 years of expertise constructing enterprise analytics and knowledge science groups at multinational firms comparable to P&G and Vodafone. Aside from his company position, he enjoys instructing Advertising Analytics and Utilized Machine Studying at a number of universities in Italy and Switzerland. Via his analysis and writing, he has explored the enterprise and societal affect of Knowledge and AI, satisfied {that a} broader analytics literacy will make the world higher. His newest guide is ‘Knowledge Analytics Made Straightforward’, revealed by Packt. He appeared in CDO journal’s 2022 world ‘Forty Below 40’ record.
Mahantesh Pattadkal brings greater than 6 years of expertise in consulting on knowledge science initiatives and merchandise. With a Grasp’s Diploma in Knowledge Science, his experience shines in Deep Studying, Pure Language Processing, and Explainable Machine Studying. Moreover, he actively engages with the KNIME Group for collaboration on knowledge science-based initiatives.
[ad_2]
Source link
