


[ad_1]
Machine Studying (ML) inference, outlined as the method of deploying a educated mannequin and serving stay queries with it, is a vital part of many deployed ML methods and is usually a good portion of their whole value. Prices can develop much more uncontrollably when contemplating {hardware} accelerators similar to GPUs. Many fashionable user-focused purposes critically rely on ML to considerably enhance the person expertise (by offering suggestions or filling in textual content, for instance). Accelerators similar to GPUs enable for much more complicated fashions to nonetheless run with affordable latencies, however come at a value. This text is for builders and methods engineers with manufacturing tasks who run ML inference companies, and explains learn how to make use of multi-model serving to decrease prices whereas sustaining excessive availability and acceptable latency.
Advantages of Multi-Mannequin Serving
ML inference queries create completely different useful resource necessities within the servers that host them. These useful resource necessities are proportional to the necessities of the mannequin, to the person question combine and price (together with peaks), and to the {hardware} platform of the server. Some fashions are giant whereas others are small. This impacts the RAM or Excessive-Bandwidth Reminiscence (HBM) capability necessities. Different fashions get periodic bursts of visitors, whereas others have constant load. Yet one more dimension to consider is the fee per question of a mannequin: some fashions are costly to run, others are fairly low cost. The mixture of those determines the required compute capability for a mannequin.

Study sooner. Dig deeper. See farther.
Sometimes, ML purposes that serve user-facing queries will provision for one mannequin per host as a result of it allows predictable latency by monitoring the per-host throughput. With this setup, growing capability is straightforward: simply add extra hosts. This horizontal scaling, nonetheless, ignores widespread pitfalls together with inefficient capability planning or unused assets such because the RAM or HBM on the accelerator. Nevertheless, for many ML purposes, it’s uncommon for one mannequin to obtain sufficient queries per second (QPS) to saturate the compute capability of enough servers for dependable, redundant, and geographically distributed serving. This method wastes all of the compute capability provisioned for these servers in extra of what’s mandatory to fulfill peak demand. Whereas this waste might be mitigated by lowering the server VM dimension, doing so has the facet impact of accelerating latency.
Multi-model serving, outlined as internet hosting a number of fashions in the identical host (or in the identical VM), may help mitigate this waste. Sharing the compute capability of every server throughout a number of fashions can dramatically cut back prices, particularly when there may be inadequate load to saturate a minimally replicated set of servers. With correct load balancing, a single server may doubtlessly serve many fashions receiving few queries alongside just a few fashions receiving extra queries, making the most of idle cycles.
Analyzing Single- Versus Multi-Mannequin Serving Latency
Contemplate a real-world instance of how multi-model serving can dramatically cut back prices. For this instance, we shall be utilizing the Google Cloud Platform VM occasion varieties so as to have a concrete instance of provisioning and for gathering check information, however these factors ought to apply to VMs in all main public cloud suppliers. A typical giant VM on fashionable cloud companies with no devoted accelerators has 32 vCPUs and 128GB of RAM. A VM with a single Nvidia A100 GPU has 12 vCPUs, 85GB of host RAM, 40GB of HBM, and prices roughly 3.5x as a lot per VM.1 This configuration assumes on-demand pricing pertinent to low latency serving. For simplification, assume hosts are at all times provisioned for peak and that each one fashions can match on a single host if chosen to serve that manner. Horizontal scaling can moreover assist management prices.
The standard visitors sample over the span of per week for 19 fashions might appear to be the next:
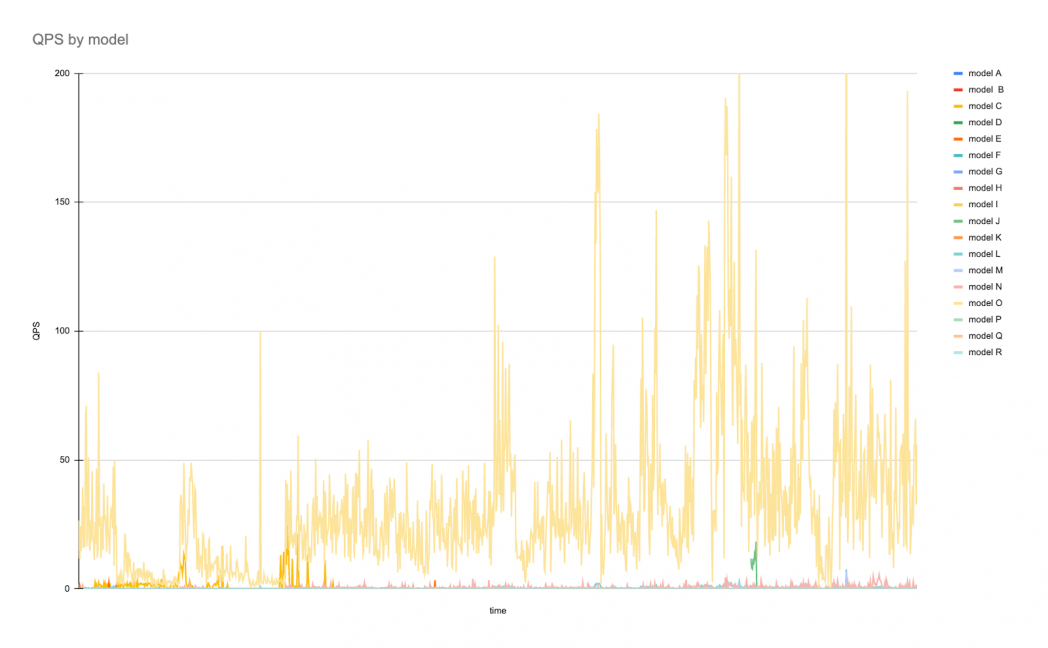
And latency over the identical time frame:
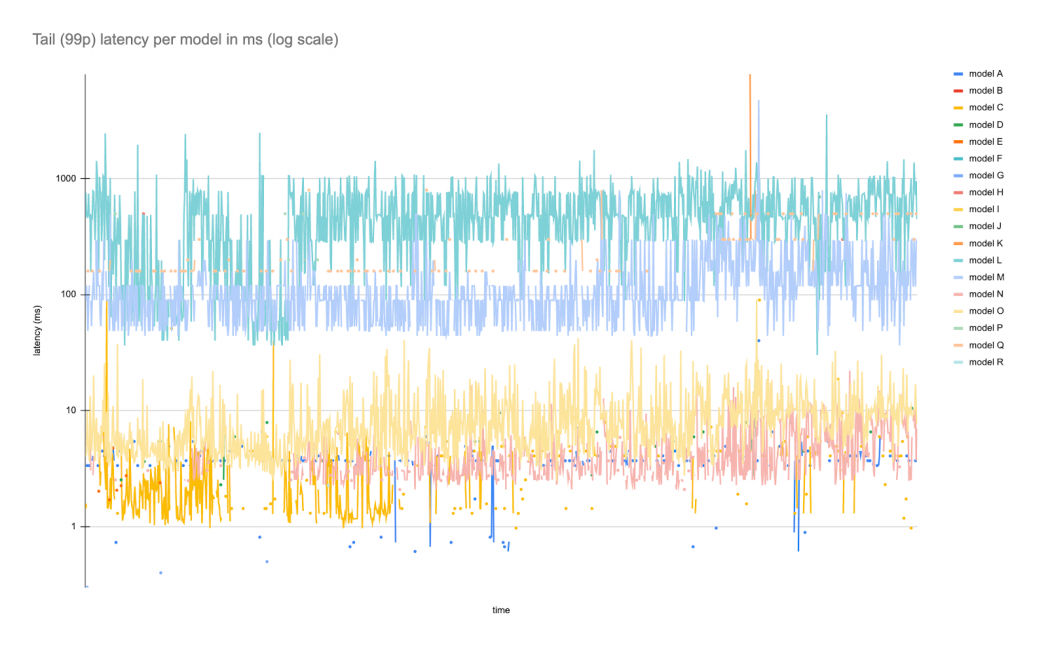
This instance exhibits one mannequin with a continuing circulate of visitors with occasional spikes and plenty of different fashions with rare however bursty ranges of visitors. Latency falls into completely different bands because of the various mannequin architectures and latency profiles, however aside from occasional spikes, have a tendency to remain inside a particular vary.
Served from a normal GCP VM, this host is using 21% of the CPU at peak however averages a lot decrease. With single mannequin serving, all 19 of those fashions would want a individually provisioned host, which means one must provision for not less than 19x the price of a base VM always for on-demand serving. This design doesn’t but account for geographic or different types of redundancy.
Taking simply the upper QPS mannequin (served in a multi-model setup), one observes the next latency graph:
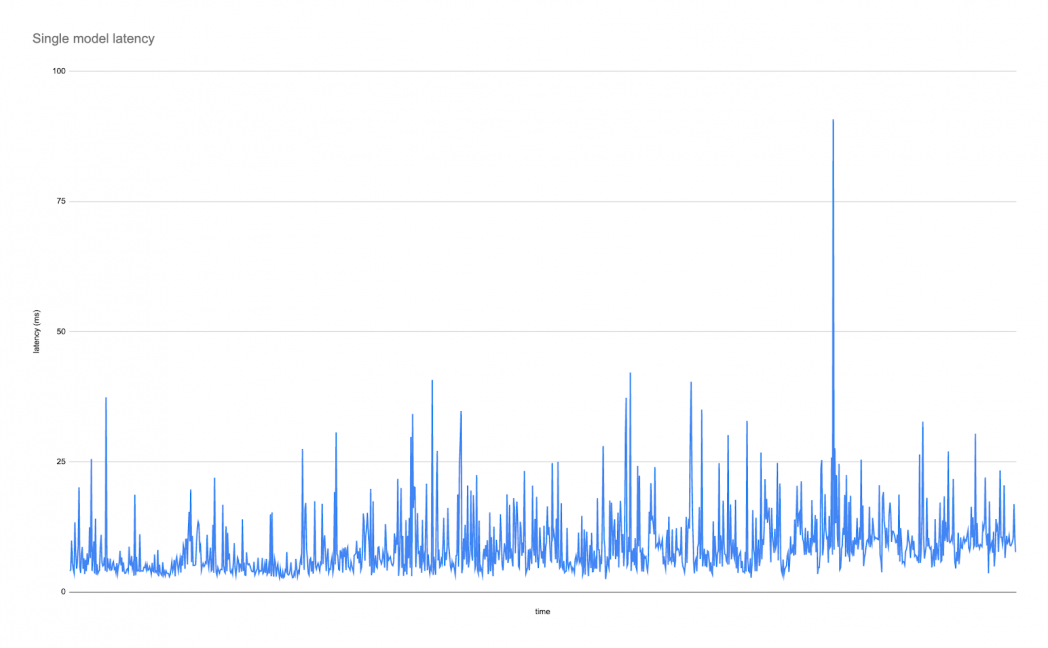
These graphs present the impact on tail latency, measured on this case because the 99th percentile latency since that’s sometimes the metric that’s most affected by multi-model serving and that customers are inclined to care about. This instance exhibits that latency can go as little as 4ms, with transient spikes as much as 40ms and just one single spike of double that. For some purposes, this variance in latency is unacceptable and single-model serving is the one affordable alternative for provisioning. It is because provisioning for a single use case results in predictable latency and low variability on tail latency, whereas common latency could be in the identical ballpark most often. Contemplate this state of affairs the “latency at any value” state of affairs. Provisioning for this case naively implies spinning up not less than 19 hosts, 1 per mannequin. For GPU fashions, apply the three.5x multiplier to the bottom prices.
On the different excessive, having all of those fashions in the identical host makes higher use of the RAM capability. This specific host is utilizing 40GB of RAM for these 19 fashions, or about 22% of capability. Internet hosting them collectively amortizes the prices, and makes use of present RAM capability by recognizing that no CPU comes with out not less than some RAM connected to it, subsequently minimizing stranding of assets.
Prices Versus Latency
At average CPU utilization, latency varies inversely with the quantity of vCPU connected to the VM, as ML fashions can make the most of parallel threads to course of queries sooner. Which means for “latency at any value,” giant VMs are greatest. From a value perspective for the overwhelming majority of fashions that serve at low QPS, reserving a whole giant VM for every mannequin is pricey, so a typical method is to make use of a smaller VM. This method reduces value, however sacrifices latency, because the graph under exhibits:
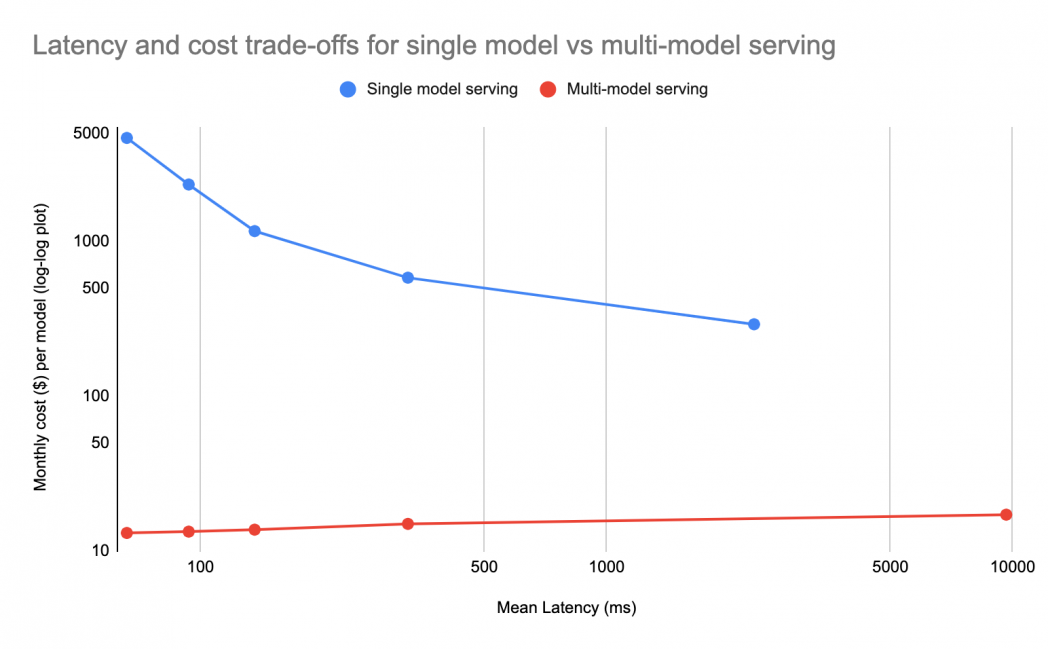
An alternate method is to pack as many fashions as attainable onto a single VM utilizing multi-model serving. This method affords the latency advantages of the big VM however divides the prices throughout many extra fashions, which might be lots of. The above graph exhibits the latency versus value tradeoff for a comparatively sluggish parallel mannequin with 10 QPS peak and 0.1 QPS on common, 3 VMs per area over 2 areas, going from 32 vCPU VMs on the left to 2 vCPU VMs on the best. Every level on the graph represents a separate VM dimension. Word how multi-model serving is about the identical value per mannequin on bigger VMs as a result of extra fashions can match on the bigger VMs, and the prices even have slight economies of scale as a result of binary overhead, whereas for single-model serving, the left of the graph exhibits latency at any value.
For the rarer fashions with excessive QPS, the advantages of multi-model serving diminish however are nonetheless important. Multi-model serving solely must provision assets for the height of sums load, enabling substantial financial savings when peak load for various fashions happens at completely different instances.
Conclusion
Multi-model serving allows decrease value whereas sustaining excessive availability and acceptable latency, by higher utilizing the RAM capability of huge VMs. Whereas it’s common and easy to deploy just one mannequin per server, as an alternative load a lot of fashions on a big VM that gives low latency, which ought to provide acceptable latency at a decrease value. These value financial savings additionally apply to serving on accelerators similar to GPUs.
1 Sourced from the official GCP VM pricing documentation
This put up is a part of a collaboration between O’Reilly and Google. See our statement of editorial independence.
[ad_2]
Source link
