

[ad_1]
A group of UC Berkeley and Stanford researchers have developed a brand new parameter-efficient fine-tuning technique referred to as Low-Rank Adaptation (LoRA) for deploying LLMs. S-LoRA was designed to allow the environment friendly deployment of many LoRA adapters. S-LoRA permits hundreds of adapters to run on a single GPU or throughout a number of GPUs with minimal overhead. The tactic introduces unified paging to optimize GPU reminiscence utilization, using novel tensor parallelism and customized CUDA kernels for heterogeneous batch processing. These methods considerably scale back the computational necessities for deploying LLMs in real-world purposes.
LoRA is a extremely environment friendly fine-tuning approach for customizing pre-trained LLMs to new duties, dramatically decreasing the trainable parameters whereas sustaining excessive accuracy. LoRA is broadly embraced, ensuing within the creation of numerous LoRA adapters for LLMs and diffusion fashions. In at present’s purposes, LLMs are pervasive, catering to numerous domains and duties.
Trendy purposes extensively make the most of LLMs, and the pretrain-then-finetune technique has resulted within the creation of a number of fine-tuned variations of a single base LLM, every personalized for particular duties or domains. LoRA is a parameter-efficient fine-tuning approach that tailors pre-trained LLMs for brand spanking new duties, considerably lowering the variety of trainable parameters whereas sustaining excessive accuracy.
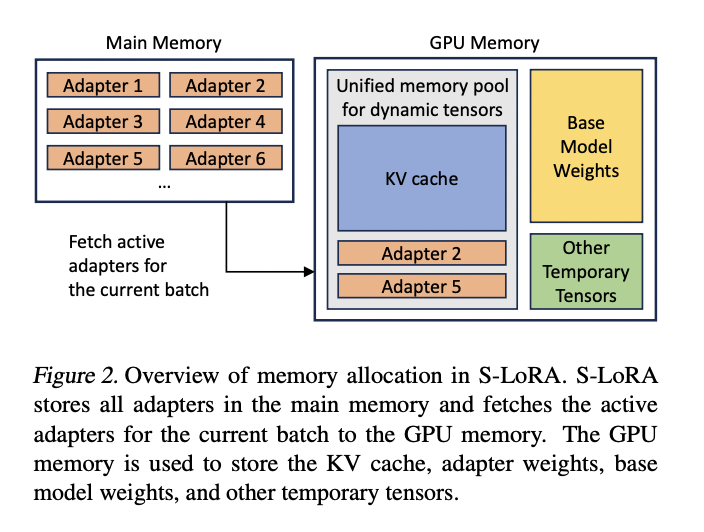
S-LoRA leverages LoRA to effectively fine-tune a base mannequin for a variety of duties, producing a considerable assortment of LoRA adapters from a single mannequin. It introduces Unified Paging, which optimizes GPU reminiscence utilization by managing dynamic adapter weights and KV cache tensors inside a unified reminiscence pool. S-LoRA permits the serving of hundreds of LoRA adapters with minimal overhead. The method can improve throughput fourfold and considerably scale up the variety of supported adapters in comparison with main libraries like HuggingFace PEFT and vLLM.
S-LoRA effectively handles 2,000 adapters concurrently with minimal overhead, sustaining low computational prices. It outperforms vLLM-packed by as much as 4 instances for just a few adapters and as much as 30 instances over PEFT whereas accommodating a considerably bigger adapter depend. S-LoRA surpasses its variations, S-LoRA-bmm and S-LoRA-no-unifymem, in throughput and latency, highlighting the effectiveness of reminiscence pooling and customized kernels. The system’s scalability is primarily restricted by obtainable major reminiscence, demonstrating strong efficiency for real-world workloads. S-LoRA’s spectacular capabilities make it a robust resolution for adapting giant language fashions to numerous duties.
The analysis goals to reinforce efficiency by investigating optimization avenues reminiscent of quantization, sparsification, and refining mannequin architectures. It explores the implementation of decomposed computation methods for each the bottom mannequin and adapters, together with the event of customized CUDA kernels for enhanced assist. The main focus additionally extends to addressing auto-regressive options and parameter-efficient adapters inside LLM serving, looking for to establish and bridge optimization gaps in present mannequin serving techniques.
In conclusion, S-LoRA has launched unified paging to fight reminiscence fragmentation, resulting in elevated batch sizes and improved scalability in serving. The research presents a scalable LoRA serving resolution, addressing the beforehand unexplored problem of serving fine-tuned variants at scale. The work optimizes LoRA serving by algorithmic methods like quantization, sparsification, and mannequin structure enhancements, complementing system-level enhancements.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to hitch our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
We’re additionally on Telegram and WhatsApp.
Whats up, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m at present pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m enthusiastic about know-how and need to create new merchandise that make a distinction.
[ad_2]
Source link
