

[ad_1]
With the appearance of AI, its use is being felt in all spheres of our lives. AI is discovering its utility in all walks of life. However AI wants knowledge for the coaching. AI’s effectiveness depends closely on knowledge availability for coaching functions.
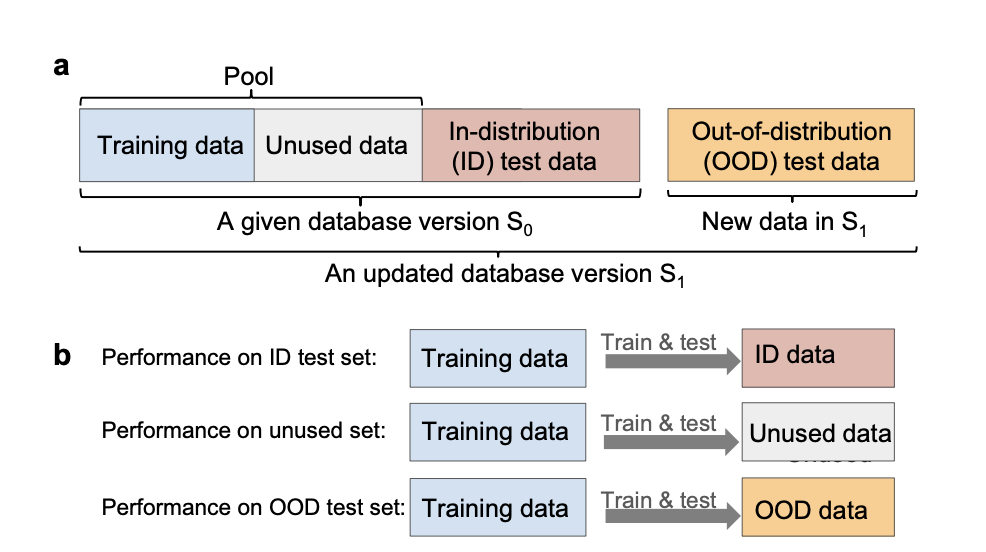
Conventionally, attaining accuracy in coaching AI fashions has been linked to the supply of considerable quantities of information. Addressing this problem on this discipline entails navigating an in depth potential search house. For instance, The Open Catalyst Challenge, makes use of greater than 200 million knowledge factors associated to potential catalyst supplies.
The computation assets required for evaluation and mannequin growth on such datasets are an enormous downside. Open Catalyst datasets used 16,000 GPU days for analyzing and creating fashions. Such coaching budgets are solely obtainable to some researchers, usually limiting mannequin growth to smaller datasets or a portion of the obtainable knowledge. Consequently, mannequin growth is often restricted to smaller datasets or a fraction of the obtainable knowledge.
A examine by College of Toronto Engineering researchers, revealed in Nature Communications, means that the idea that deep studying fashions require a number of coaching knowledge might not be all the time true.
The researchers mentioned that we have to discover a method to determine smaller datasets that can be utilized to coach fashions on. Dr. Kangming Li, a postdoctoral scholar at Hattrick-Simpers, used an instance of a mannequin that forecasts college students’ closing scores and emphasised that it performs finest on the dataset of Canadian college students on which it’s educated, but it surely may not have the ability to predict grades for college kids from of different international locations.
One attainable resolution is discovering subsets of information inside extremely big datasets to deal with the problems raised. These subsets ought to comprise all the range and data within the unique dataset however be simpler to deal with throughout processing.
Li developed strategies for finding high-quality subsets of data from supplies datasets which have already been made public, equivalent to JARVIS, The Supplies Challenge, and Open Quantum Supplies. The purpose was to achieve extra perception into how dataset properties have an effect on the fashions they practice.
To create his laptop program, he used the unique dataset and a a lot smaller subset with 95% fewer knowledge factors. The mannequin educated on 5% of the info carried out comparably to the mannequin educated on your complete dataset when predicting the properties of supplies inside the dataset’s area. In response to this, machine studying coaching can safely exclude as much as 95% of the info with little to no impact on the accuracy of in-distribution predictions. The overrepresented materials is the primary topic of the redundant knowledge.
In response to Li, the examine’s conclusions present a method to gauge how redundant a dataset is. If including extra knowledge doesn’t enhance mannequin efficiency, it’s redundant and doesn’t present the fashions with any new data to be taught.
The examine helps a rising physique of data amongst consultants in AI throughout a number of domains: fashions educated on comparatively small datasets can carry out effectively, supplied the info high quality is excessive.
In conclusion, the importance of data richness is pressured greater than the amount of information alone. The standard of the data must be prioritized over gathering huge volumes of information.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to affix our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
Rachit Ranjan is a consulting intern at MarktechPost . He’s presently pursuing his B.Tech from Indian Institute of Expertise(IIT) Patna . He’s actively shaping his profession within the discipline of Synthetic Intelligence and Information Science and is passionate and devoted for exploring these fields.
[ad_2]
Source link
