

[ad_1]
A number of current vision-language fashions have demonstrated outstanding multi-modal technology skills. However sometimes, they name for coaching huge fashions on huge datasets. Researchers introduce Prismer, a data- and parameter-efficient vision-language mannequin that makes use of an ensemble of area specialists, as a scalable different. By inheriting many of the community weights from publicly accessible, pre-trained area specialists and freezing them throughout coaching, Prismer solely requires coaching just a few elements.
The generalization skills of huge pre-trained fashions are distinctive throughout many various duties. Nonetheless, these options come at a excessive value, necessitating numerous coaching knowledge and computational sources for coaching and inference. Fashions with tons of of billions of trainable parameters are frequent within the language area, and so they sometimes necessitate a computing finances on the yottaFLOP scale.
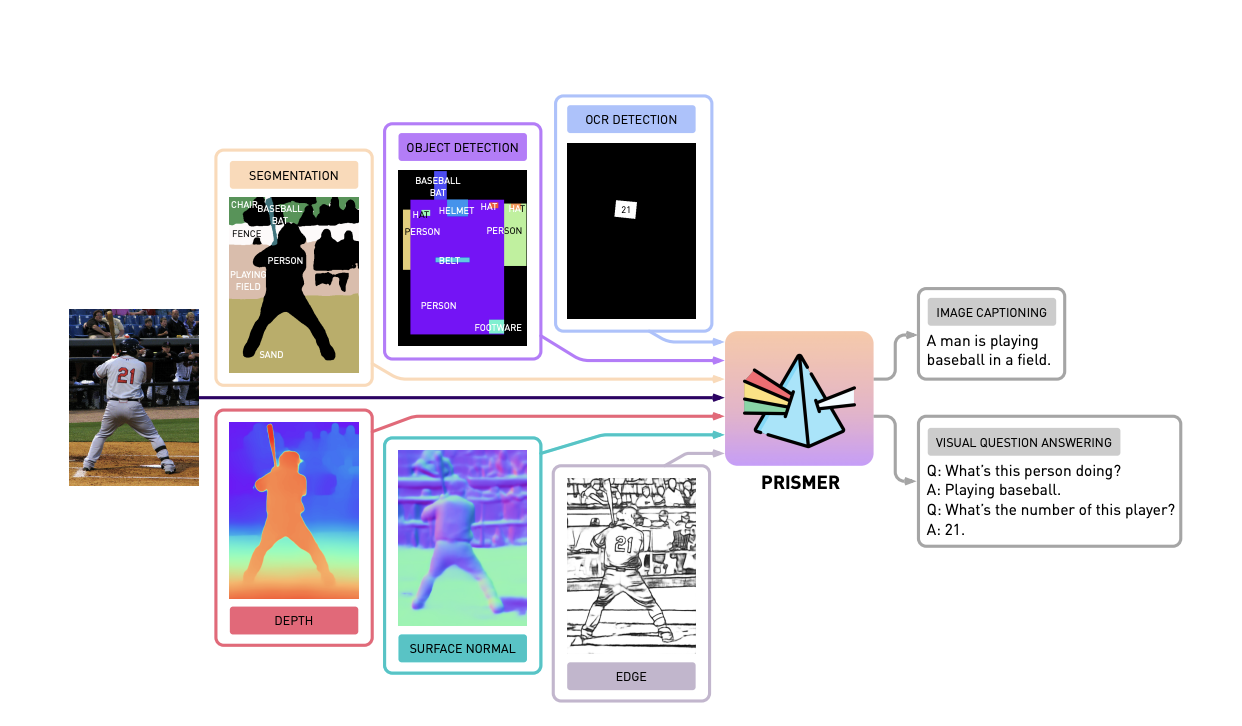
Points associated to visible language studying are harder to unravel. Though this subject is a superset of language processing, it additionally necessitates visible and multi-modal considering experience. Utilizing its projected multi-modal alerts, Prismer is a data-efficient vision-language mannequin that makes use of a variety of pre-trained specialists. It will possibly deal with visible query answering and movie captioning, two examples of vision-language reasoning duties. Utilizing a prism for instance, Prismer divides a basic reasoning job into a number of smaller, extra manageable chunks.
Researchers developed a visually conditioned autoregressive textual content technology mannequin toTwo of Prismer’s most essential design options are I vision-only. Language-only fashions for web-scale information to assemble our core community backbones, and (ii) modalities-specific imaginative and prescient specialists encoding a number of kinds of visible data, from low-level imaginative and prescient alerts like depth to high-level imaginative and prescient alerts like occasion and semantic labels, as auxiliary information, straight from their corresponding community outputs. Researchers developed a visually conditioned autoregressive textual content technology mannequin to higher use varied pre-trained area specialists for exploratory vision-language reasoning duties.
Though Prismer was solely skilled on 13M examples of publicly accessible picture/alt-text knowledge, it reveals robust multi-modal reasoning efficiency in duties like picture captioning, picture classification, and visible query answering, which is aggressive with many state-of-the-art imaginative and prescient language fashions. Researchers conclude with a radical investigation of Prismer’s studying habits, the place researchers discover a number of good options.
Mannequin Design:
The Prismer mannequin, proven in its encoder-decoder transformer model, attracts on a big pool of already-trained subject material specialists to hurry up the coaching course of. A visible encoder plus an autoregressive language decoder make up this method. The imaginative and prescient encoder receives a sequence of RGB and multi-modal labels (depth, floor regular, and segmentation labels anticipated from the frozen pre-trained specialists) as enter. It produces a sequence of RGB and multi-modal options as output. Because of this cross-attention coaching, the language decoder is conditioned to generate a string of textual content tokens.
Benefits:
- The Prismer mannequin has a number of advantages, however one of the crucial notable is that it makes use of knowledge extraordinarily effectively whereas being skilled. Prismer is constructed on prime of pre-trained vision-only and language-only spine fashions to attain this purpose with a substantial lower in GPU hours obligatory to achieve equal efficiency to different state-of-the-art vision-language fashions. One might use these pre-trained parameters to make use of the large quantities of obtainable web-scale information.
- Researchers additionally developed a multi-modal sign enter for the imaginative and prescient encoder. The created multi-modal auxiliary information can higher seize semantics and details about the enter picture. Prismer’s structure is optimized for maximizing the usage of skilled specialists with few trainable parameters.
Researchers have included two forms of pre-trained specialists in Prismer:
- Specialists within the Spine The pre-trained fashions liable for translating textual content and footage right into a significant sequence of tokens are known as “vision-only” and “language-only” fashions, respectively.
- Relying on the info used of their coaching, moderators of Discourse Fashions might label duties in varied methods.
Properties
- The extra educated folks there are, the higher the outcomes. Because the variety of modality specialists in Prismer grows, its efficiency enhances.
- Extra Expert Professionals, Greater Outcomes researchers substitute some fraction of the expected depth labels with random noise taken from a Uniform Distribution to create a corrupted depth skilled and assess the impact of skilled high quality on Prismer’s efficiency.
- Resistance to Unhelpful Opinions the findings additional show that Prismer’s efficiency is regular when noise-predicting specialists are included.
Try the Paper and Github. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t overlook to hitch our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
Dhanshree Shenwai is a Laptop Science Engineer and has expertise in FinTech corporations protecting Monetary, Playing cards & Funds and Banking area with eager curiosity in functions of AI. She is obsessed with exploring new applied sciences and developments in right this moment’s evolving world making everybody’s life simple.
[ad_2]
Source link
