


[ad_1]

Picture By Editor
The bona fide semantic understanding of human language textual content, exhibited by its efficient summarization, might be the holy grail of pure language processing (NLP). That assertion is not as hyperbolic because it sounds: as true human language understanding undoubtedly is the holy grail of NLP, and real efficient summarization of mentioned human language would essentially entail true understanding, transitivity would again me up on this.
Sadly — or maybe not, relying in your outlook — trustworthy to goodness “understanding” of human language will not be one thing we are able to at present rely on for textual content summarization. Nevertheless, the present should go on, and there at present exist an array of precise methods for summarizing textual content, a few of which stretch again a long time. These methods take totally different approaches to succeed in the identical purpose, and could be categorised into a reasonably slim set of classes for pursuing their shared purpose.
This text will current the principle approaches to textual content summarization at present employed, in addition to talk about a few of their traits.
To be clear, once we say “automated textual content summarization,” we’re speaking about using machines to carry out the summarization of a doc or doc utilizing some type of heuristics or statistical strategies. A abstract on this case is a shortened piece of textual content which precisely captures and conveys a very powerful and related info contained within the doc or paperwork we wish to be summarized. As hinted at above, there are a selection of those totally different tried and actually automated textual content summarization methods which can be at present in use.
There are just a few methods of going about classifying automated textual content summarization methods, as could be seen in Determine 1. This text will discover these methods from the viewpoint of summarization output kind. On this regard, there are 2 classes of methods: extractive and abstraction.
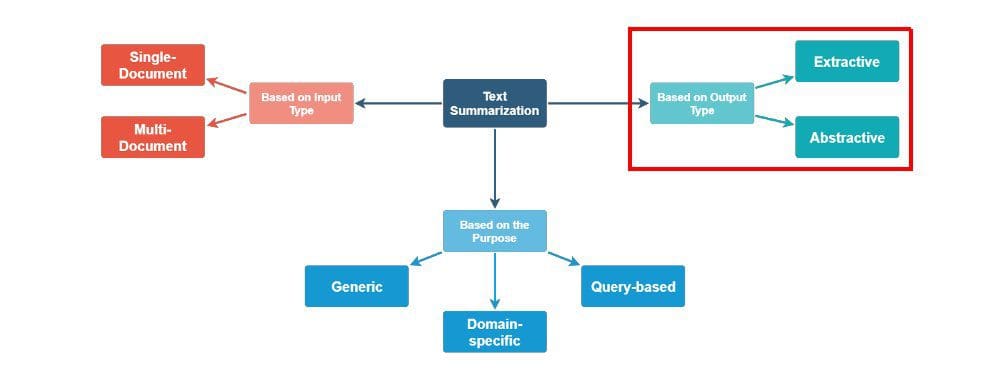
Determine 1. Automated textual content summarization approaches (supply: Kushal Chauhan, Jutana, modified).
Extractive textual content summarization strategies operate by figuring out the necessary sentences or excerpts from the textual content and reproducing them verbatim as a part of the abstract. No new textual content is generated; solely present textual content is used within the summarization course of.
Abstractive textual content summarization strategies make use of extra highly effective pure language processing methods to interpret textual content and generate new abstract textual content, versus choosing probably the most consultant present excerpts to carry out the summarization.
Whereas each are legitimate approaches to textual content summarization, it shouldn’t be tough to persuade you that abstractive methods are far tougher to implement. In actual fact, nearly all of summarization processes in the present day are extraction-based. This does not imply that abstractive strategies ought to be discounted or ignored; quite the opposite, analysis into their implementation — and true semantic understanding of human language normally — is a worthy pursuit, and far work is required earlier than we are able to confidently say that we’ve got gained a real foothold on this endeavor.
Because of this, the remainder of this text will concentrate on the specifics of extractive textual content summarization, and its differing implementation methods.
Extractive summarization methods range, but all of them share the identical primary duties:
- Assemble an intermediate illustration of the enter textual content (textual content to be summarized)
- Rating the sentences primarily based on the constructed intermediate illustration
- Choose a abstract consisting of the highest ok most necessary sentences
Duties 2 and three are simple sufficient; in sentence scoring, we wish to decide how nicely every sentence relays necessary facets of the textual content being summarized, whereas sentence choice is carried out utilizing some particular optimization method. Algorithms for every of those 2 steps can range, however they’re conceptually fairly easy: assign a rating to every sentence utilizing some metric, after which choose from the best-scored sentences by way of some well-defined sentence choice technique.
The primary process, intermediate illustration, may use additional elaboration.
Some sense must be fabricated from pure language previous to its sentence scoring and choice, and creating some intermediate illustration of every sentence serves this function. The two main classes of intermediate illustration, subject illustration and indicator illustration, are briefly outlined beneath, as are their sub-categories.
Matter Illustration – transformation of the textual content with a concentrate on textual content subject identification; main sub-categories of this method are:
The two hottest phrase frequency approaches are phrase likelihood and TF-IDF.
In subject phrases approaches, there are 2 methods to compute a sentence’s significance: by the variety of subject signatures it incorporates (the variety of matters the sentence discusses), or by the proportion of matters the sentence incorporates versus the variety of matters contained within the textual content. As such, the primary of those tends to reward longer sentences, whereas the second measures subject phrase density.
Explanations of latent semantic evaluation and Bayesian subject mannequin approaches, resembling LDA, are past the scope of this text, however could be examine within the hyperlinks above.

Determine 2. Developing bag of phrases characteristic vectors (supply: Dipanjan Sarkar).
Indicator Illustration – transformation of every sentence within the textual content into a listing of options of significance; attainable options embrace:
- sentence size
- sentence place
- whether or not sentence incorporates a specific phrase (see Determine 2 for an instance of such a characteristic extraction technique, bag of words)
- whether or not sentence incorporates a specific phrase
Utilizing a set of options to symbolize and rank the textual content knowledge could be carried out utilizing considered one of 2 overarching indicator illustration strategies: graph strategies and machine studying strategies.
Utilizing graph representations:
- we discover that sub-graphs find yourself representing matters coated within the textual content
- we’re capable of isolate necessary sentences within the textual content, provided that these are those which might be related to a higher variety of different sentences (in case you think about sentences as vertices and sentence similarity represented by edges)
- we don’t want to contemplate language-specific processing, and the identical strategies could be utilized to a wide range of languages
- we are able to typically discover that the semantic info gained by way of graph-exposed sentence similarity enhances summarization efficiency past extra easy frequency approaches
With machine studying representations:
- the summarization drawback is modeled as a classification drawback
- we require labeled coaching knowledge to construct a classifier to categorise sentences as abstract or non-summary sentences
- to fight the labeled knowledge conundrum, options resembling semi-supervised studying present promise
- we discover that sure strategies which assume dependency between sentences typically outperform different methods
Textual content summarization is an thrilling sub-discipline of pure language processing. Whereas a wide range of approaches to extractive summarization are in use and are being researched each day, an understanding of the idea of the ideas above ought to permit you to have some understanding of how any of those function, at the least at a 30,000 foot stage. You also needs to have the ability to decide up current papers or learn current implementation weblog posts with some confidence you have got the essential stage of understanding mandatory for such an enterprise.
A lot of this info owes a debt of gratitude to the paper, Text Summarization Techniques: A Brief Survey, by Mehdi Allahyari, Seyedamin Pouriyeh, Mehdi Assefi, Saeid Safaei, Elizabeth D. Trippe, Juan B. Gutierrez, and Krys Kochut.
References & additional studying:
- Text Summarization Techniques: A Brief Survey, Mehdi Allahyari, Seyedamin Pouriyeh, Mehdi Assefi, Saeid Safaei, Elizabeth D. Trippe, Juan B. Gutierrez, Krys Kochut, 2017.
- Unsupervised Text Summarization using Sentence Embeddings, Kushal Chauhan, 2018.
Additionally, this text centered on extractive summarization, however yow will discover extra about abstractive summarization within the following:
Matthew Mayo (@mattmayo13) is a Information Scientist and the Editor-in-Chief of KDnuggets, the seminal on-line Information Science and Machine Studying useful resource. His pursuits lie in pure language processing, algorithm design and optimization, unsupervised studying, neural networks, and automatic approaches to machine studying. Matthew holds a Grasp’s diploma in pc science and a graduate diploma in knowledge mining. He could be reached at editor1 at kdnuggets[dot]com.
[ad_2]
Source link
