

[ad_1]
Perceive Semantic Buildings with Transformers and Subject Modeling
We dwell within the age of huge knowledge. At this level it’s develop into a cliche to say that knowledge is the oil of the twenty first century but it surely actually is so. Knowledge assortment practices have resulted in enormous piles of information in nearly everybody’s palms.
Decoding knowledge, nevertheless, is not any simple job, and far of the business and academia nonetheless depend on options, which offer little within the methods of explanations. Whereas deep studying is extremely helpful for predictive functions, it not often offers practitioners an understanding of the mechanics and constructions that underlie the info.
Textual knowledge is particularly tough. Whereas pure language and ideas like “matters” are extremely simple for people to have an intuitive grasp of, producing operational definitions of semantic constructions is way from trivial.
On this article I’ll introduce you to totally different conceptualizations of discovering latent semantic constructions in pure language, we are going to take a look at operational definitions of the speculation, and finally I’ll display the usefulness of the strategy with a case examine.
Whereas matter to us people looks like a totally intuitive and self-explanatory time period, it’s hardly so after we attempt to give you a helpful and informative definition. The Oxford dictionary’s definition is fortunately right here to assist us:
A topic that’s mentioned, written about, or studied.
Nicely, this didn’t get us a lot nearer to one thing we will formulate in computational phrases. Discover how the phrase topic, is used to cover all of the gory particulars. This needn’t deter us, nevertheless, we will definitely do higher.

In Pure Language Processing, we regularly use a spatial definition of semantics. This may sound fancy, however basically we think about that semantic content material of textual content/language will be expressed in some steady house (typically high-dimensional), the place ideas or texts which can be associated are nearer to one another than people who aren’t. If we embrace this principle of semantics, we will simply give you two doable definitions for matter.
Matters as Semantic Clusters
A somewhat intuitive conceptualization is to think about matter as teams of passages/ideas in semantic house which can be intently associated to one another, however not as intently associated to different texts. This by the way implies that one passage can solely belong to 1 matter at a time.

This clustering conceptualization additionally lends itself to fascinated with matters hierarchically. You may think about that the subject “animals” may include two subclusters, one which is “Eukaryates”, whereas the opposite is “Prokaryates”, after which you possibly can go down this hierarchy, till, on the leaves of the tree one can find precise situations of ideas.
After all a limitation of this strategy is that longer passages may include a number of matters in them. This might both be addressed by splitting up texts to smaller, atomic elements (e.g. phrases) and modeling over these, however we will additionally ditch the clustering conceptualization alltogether.
Matters as Axes of Semantics
We are able to additionally consider matters because the underlying dimensions of the semantic house in a corpus. Or in different phrases: As an alternative of describing what teams of paperwork there are we’re explaining variation in paperwork by discovering underlying semantic alerts.

We’re explaining variation in paperwork by discovering underlying semantic alerts.
You possibly can as an illustration think about that a very powerful axes that underlie restaurant opinions could be:
- Satisfaction with the meals
- Satisfaction with the service
I hope you see why this conceptualization is helpful for sure functions. As an alternative of us discovering “good opinions” and “dangerous opinions”, we get an understanding of what it’s that drives variations between these. A popular culture instance of this type of theorizing is in fact the political compass. But once more, as a substitute of us being serious about discovering “conservatives” and “progressives”, we discover the components that differentiate these.
Now that we received the philosophy out of the best way, we will get our palms soiled with designing computational fashions primarily based on our conceptual understanding.
Semantic Representations
Classically the best way we represented the semantic content material of texts, was the so-called bag-of-words mannequin. Basically you make the very sturdy, and virtually trivially incorrect assumption, that the unordered assortment of phrases in a doc is constitutive of its semantic content material. Whereas these representations are plagued with quite a lot of points (curse of dimensionality, discrete house, and so forth.) they’ve been demonstrated helpful by many years of analysis.
Fortunately for us, the cutting-edge has progressed past these representations, and we now have entry to fashions that may symbolize textual content in context. Sentence Transformers are transformer fashions which may encode passages right into a high-dimensional steady house, the place semantic similarity is indicated by vectors having excessive cosine similarity. On this article I’ll primarily concentrate on fashions that use these representations.
Clustering Fashions
Fashions which can be presently probably the most widespread within the matter modeling group for contextually delicate matter modeling (Top2Vec, BERTopic) are primarily based on the clustering conceptualization of matters.

They uncover matters in a course of that consists of the next steps:
- Cut back dimensionality of semantic representations utilizing UMAP
- Uncover cluster hierarchy utilizing HDBSCAN
- Estimate importances of phrases for every cluster utilizing post-hoc descriptive strategies (c-TF-IDF, proximity to cluster centroid)
These fashions have gained loads of traction, primarily resulting from their interpretable matter descriptions and their capacity to recuperate hierarchies, in addition to to be taught the variety of matters from the info.
If we wish to mannequin nuances in topical content material, and perceive components of semantics, clustering fashions should not sufficient.
I don’t intend to enter nice element in regards to the sensible benefits and limitations of those approaches, however most of them stem from philosophical concerns outlined above.
Semantic Sign Separation
If we’re to find the axes of semantics in a corpus, we are going to want a brand new statistical mannequin.
We are able to take inspiration from classical matter fashions, akin to Latent Semantic Allocation. LSA makes use of matrix decomposition to search out latent elements in bag-of-words representations. LSA’s predominant objective is to search out phrases which can be extremely correlated, and clarify their cooccurrence as an underlying semantic part.
Since we’re not coping with bag-of-words, explaining away correlation won’t be an optimum technique for us. Orthogonality shouldn’t be statistical independence. Or in different phrases: Simply because two elements are uncorrelated, it doesn’t imply that they’re statistically impartial.
Orthogonality shouldn’t be statistical independence
Different disciplines have fortunately give you decomposition fashions that uncover maximally impartial elements. Impartial Part Evaluation has been extensively utilized in Neuroscience to find and take away noise alerts from EEG knowledge.

The primary thought behind Semantic Sign Separation is that we will discover maximally impartial underlying semantic alerts in a corpus of textual content by decomposing representations with ICA.
We are able to achieve human-readable descriptions of matters by taking phrases from the corpus that rank highest on a given part.
To display the usefulness of Semantic Sign Separation for understanding semantic variation in corpora, we are going to match a mannequin on a dataset of roughly 118k machine studying abstracts.
To reiterate as soon as once more what we’re attempting to realize right here: We wish to set up the scale, alongside which all machine studying papers are distributed. Or in different phrases we want to construct a spatial principle of semantics for this corpus.
For this we’re going to use a Python library I developed referred to as Turftopic, which has implementations of most matter fashions that make the most of representations from transformers, together with Semantic Sign Separation. Moreover we’re going to set up the HuggingFace datasets library in order that we will obtain the corpus at hand.
pip set up turftopic datasets
Allow us to obtain the info from HuggingFace:
from datasets import load_datasetds = load_dataset("CShorten/ML-ArXiv-Papers", break up="prepare")
We’re then going to run Semantic Sign Separation on this knowledge. We’re going to use the all-MiniLM-L12-v2 Sentence Transformer, as it’s fairly quick, however offers fairly top quality embeddings.
from turftopic import SemanticSignalSeparationmannequin = SemanticSignalSeparation(10, encoder="all-MiniLM-L12-v2")
mannequin.match(ds["abstract"])
mannequin.print_topics()

These are highest rating key phrases for the ten axes we discovered within the corpus. You may see that almost all of those are fairly readily interpretable, and already enable you see what underlies variations in machine studying papers.
I’ll concentrate on three axes, form of arbitrarily, as a result of I discovered them to be attention-grabbing. I’m a Bayesian evangelist, so Subject 7 looks like an attention-grabbing one, as evidently this part describes how probabilistic, mannequin primarily based and causal papers are. Subject 6 appears to be about noise detection and removing, and Subject 1 is generally involved with measurement units.
We’re going to produce a plot the place we show a subset of the vocabulary the place we will see how excessive phrases rank on every of those elements.
First let’s extract the vocabulary from the mannequin, and choose quite a lot of phrases to show on our graphs. I selected to go together with phrases which can be within the 99th percentile primarily based on frequency (in order that they nonetheless stay considerably seen on a scatter plot).
import numpy as npvocab = mannequin.get_vocab()
# We'll produce a BoW matrix to extract time period frequencies
document_term_matrix = mannequin.vectorizer.remodel(ds["abstract"])
frequencies = document_term_matrix.sum(axis=0)
frequencies = np.squeeze(np.asarray(frequencies))
# We choose the 99th percentile
selected_terms_mask = frequencies > np.quantile(frequencies, 0.99)
We’ll make a DataFrame with the three chosen dimensions and the phrases so we will simply plot later.
import pandas as pd# mannequin.components_ is a n_topics x n_terms matrix
# It comprises the power of all elements for every phrase.
# Right here we're choosing elements for the phrases we chosen earlier
terms_with_axes = pd.DataFrame({
"inference": mannequin.components_[7][selected_terms],
"measurement_devices": mannequin.components_[1][selected_terms],
"noise": mannequin.components_[6][selected_terms],
"time period": vocab[selected_terms]
})
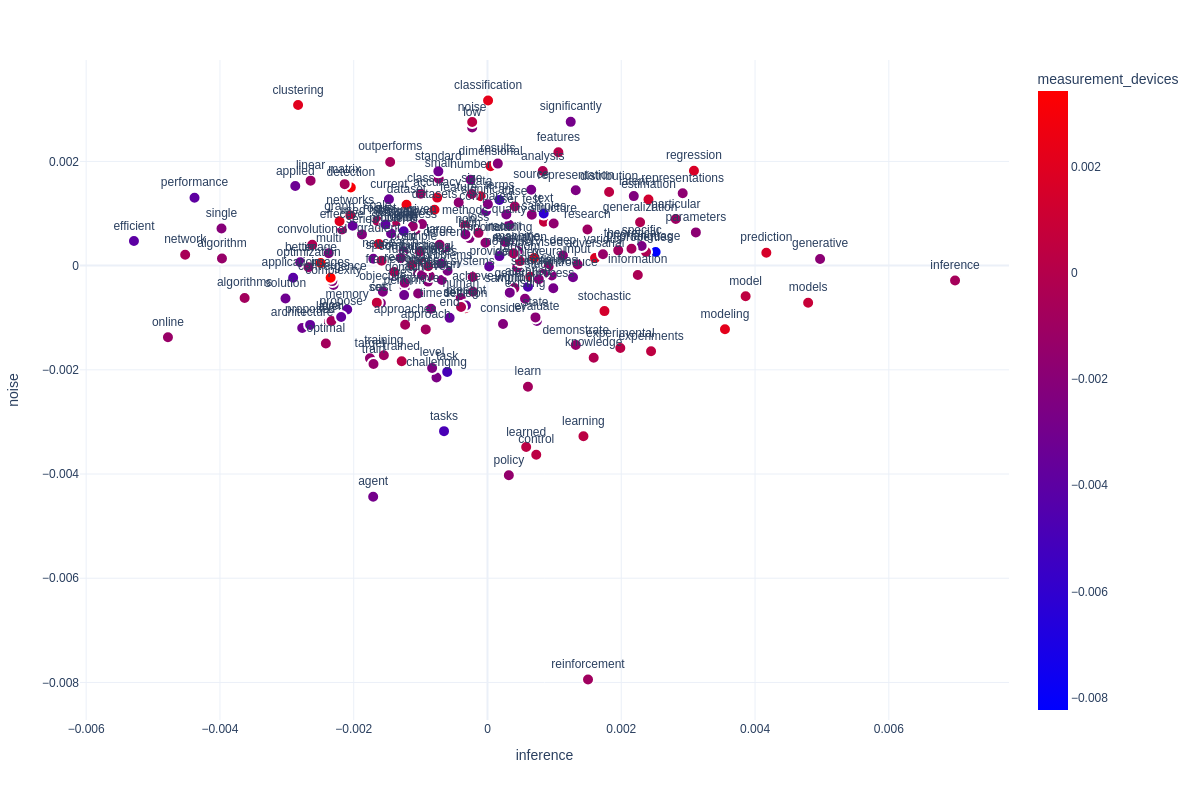
We’ll use the Plotly graphing library for creating an interactive scatter plot for interpretation. The X axis goes to be the inference/Bayesian matter, Y axis goes to be the noise matter, and the colour of the dots goes to be decided by the measurement system matter.
import plotly.categorical as pxpx.scatter(
terms_with_axes,
textual content="time period",
x="inference",
y="noise",
shade="measurement_devices",
template="plotly_white",
color_continuous_scale="Bluered",
).update_layout(
width=1200,
peak=800
).update_traces(
textposition="high heart",
marker=dict(dimension=12, line=dict(width=2, shade="white"))
)

We are able to already infer quite a bit in regards to the semantic construction of our corpus primarily based on this visualization. As an illustration we will see that papers which can be involved with effectivity, on-line becoming and algorithms rating very low on statistical inference, that is considerably intuitive. However what Semantic Sign Separation has already helped us do in a data-based strategy is verify, that deep studying papers should not very involved with statistical inference and Bayesian modeling. We are able to see this from the phrases “community” and “networks” (together with “convolutional”) rating very low on our Bayesian axis. This is likely one of the criticisms the sector has obtained. We’ve simply given assist to this declare with empirical proof.
Deep studying papers should not very involved with statistical inference and Bayesian modeling, which is likely one of the criticisms the sector has obtained. We’ve simply given assist to this declare with empirical proof.
We are able to additionally see that clustering and classification may be very involved with noise, however that agent-based fashions and reinforcement studying isn’t.
Moreover an attention-grabbing sample we might observe is the relation of our Noise axis to measurement units. The phrases “picture”, “photographs”, “detection” and “strong” stand out as scoring very excessive on our measurement axis. These are additionally in a area of the graph the place noise detection/removing is comparatively excessive, whereas discuss statistical inference is low. What this means to us, is that measurement units seize loads of noise, and that the literature is attempting to counteract these points, however primarily not by incorporating noise into their statistical fashions, however by preprocessing. This makes loads of sense, as as an illustration, Neuroscience is understood for having very in depth preprocessing pipelines, and plenty of of their fashions have a tough time coping with noise.

We are able to additionally observe that the bottom scoring phrases on measurement units is “textual content” and “language”. It appears that evidently NLP and machine studying analysis shouldn’t be very involved with neurological bases of language, and psycholinguistics. Observe that “latent” and “illustration can be comparatively low on measurement units, suggesting that machine studying analysis in neuroscience shouldn’t be tremendous concerned with illustration studying.

After all the chances from listed below are limitless, we may spend much more time deciphering the outcomes of our mannequin, however my intent was to display that we will already discover claims and set up a principle of semantics in a corpus through the use of Semantic Sign Separation.
Semantic Sign Separation ought to primarily be used as an exploratory measure for establishing theories, somewhat than taking its outcomes as proof of a speculation.
One factor I want to emphasize is that Semantic Sign Separation ought to primarily be used as an exploratory measure for establishing theories, somewhat than taking its outcomes as proof of a speculation. What I imply right here, is that our outcomes are adequate for gaining an intuitive understanding of differentiating components in our corpus, an then constructing a principle about what is going on, and why it’s taking place, however it’s not adequate for establishing the speculation’s correctness.
Exploratory knowledge evaluation will be complicated, and there are in fact no one-size-fits-all options for understanding your knowledge. Collectively we’ve checked out how you can improve our understanding with a model-based strategy from principle, by way of computational formulation, to observe.
I hope this text will serve you effectively when analysing discourse in giant textual corpora. In the event you intend to be taught extra about matter fashions and exploratory textual content evaluation, ensure to take a look at a few of my different articles as effectively, as they focus on some features of those topics in better element.
(( Except acknowledged in any other case, figures have been produced by the creator. ))
[ad_2]
Source link
