


[ad_1]
A vital problem on the core of the developments in giant language fashions (LLMs) is making certain that their outputs align with human moral requirements and intentions. Regardless of their sophistication, these fashions can generate content material that may be technically correct however could not align with particular person expectations or societal norms. This misalignment highlights the necessity for efficient mechanisms to information LLM outputs towards desired moral and sensible targets, posing a major hurdle in harmonizing machine-generated content material with human values and intentions.
Present strategies to deal with this alignment problem primarily deal with modifying the coaching course of of those fashions, using methods like Reinforcement Studying with Human Suggestions (RLHF). Nevertheless, these approaches are restricted by their reliance on static, predefined reward features and their lack of ability to adapt to nuanced or evolving human preferences.
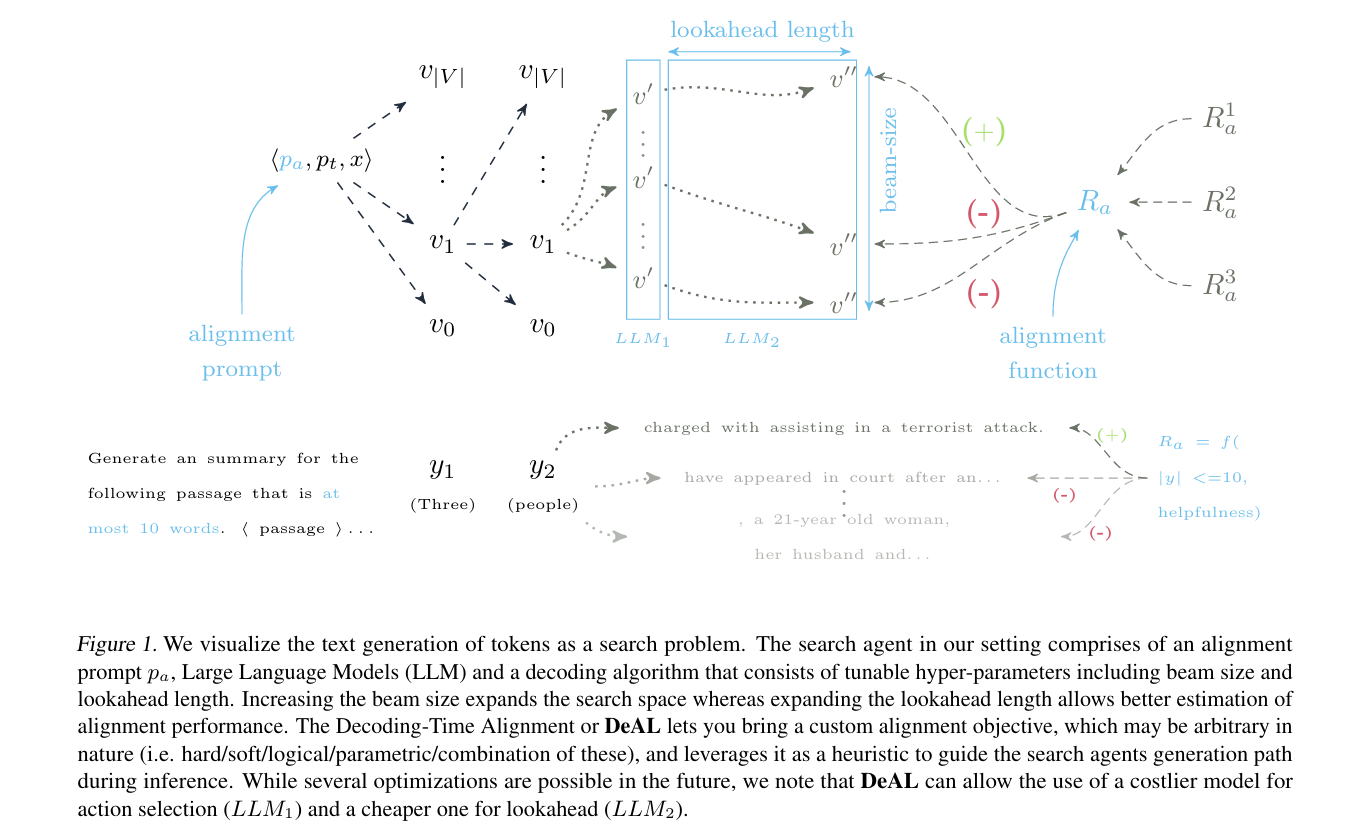
Researchers have launched a novel framework, DeAL (Decoding-time Alignment for Massive Language Fashions), that reimagines the strategy to mannequin alignment by permitting for the customization of reward features on the decoding stage moderately than throughout coaching. This innovation gives a extra versatile and dynamic technique for aligning mannequin outputs with particular person targets.
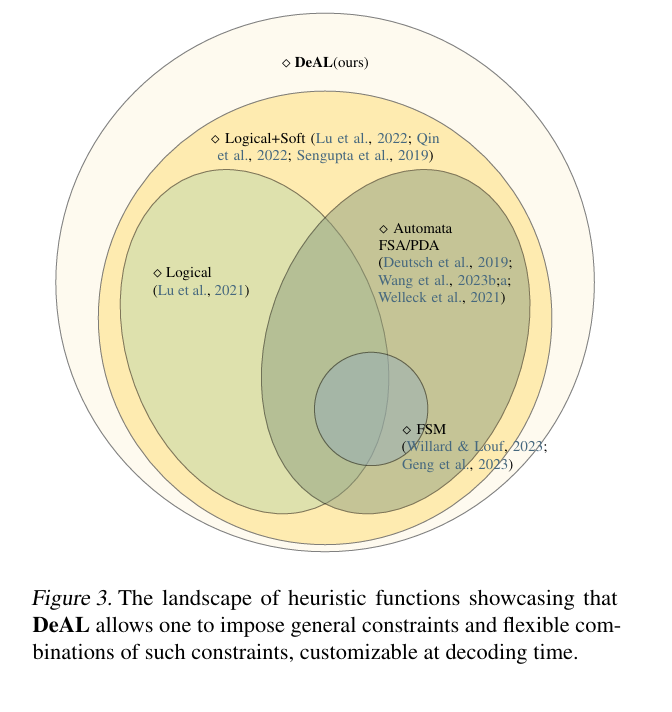
Navigating this search includes using the A* search algorithm powered by an auto-regressive LLM. This technique is finely tuned by means of hyper-parameters and a heuristic perform designed to approximate the alignment rewards, optimizing the era outcomes. Because the search unfolds, the agent dynamically adapts the beginning state, tweaking the enter immediate to refine era outcomes additional. An vital step on this course of is motion choice, the place a choose group of candidate actions is chosen primarily based on their chance, as decided by the LLM. This strategy is strengthened by alignment metrics serving as heuristics to evaluate every motion’s potential, with lookahead mechanisms providing invaluable insights on probably the most promising paths. The choice for the next motion hinges on a scoring perform that integrates the motion’s likelihood with the heuristic rating, permitting for a selection between deterministic and stochastic strategies. This framework’s versatility extends to accommodating programmatically verifiable constraints and parametric estimators as heuristics, addressing the hole left by earlier works in contemplating parametric alignment targets for LLMs.
The experiments showcase DeAL’s capability to reinforce alignment to targets throughout assorted eventualities with out compromising process efficiency. From keyword-constrained era duties demonstrating improved key phrase protection within the CommonGen dataset to length-constrained summarization duties within the XSUM dataset displaying higher size satisfaction, DeAL proves superior. It excels in eventualities requiring summary alignment targets like harmlessness and helpfulness, providing a versatile and efficient resolution, significantly in safety conditions. DeAL’s capability to be calibrated for particular alignment ranges additional underscores its adaptability and effectiveness in comparison with conventional strategies.
In conclusion, DeAL represents a exceptional development within the quest for extra aligned and ethically acutely aware AI fashions. By integrating with present alignment methods like system prompts and fine-tuning, DeAL boosts alignment high quality. It emerges as a pivotal resolution in safety contexts, overcoming the restrictions of conventional strategies that wrestle with incorporating a number of customized rewards and the subjective biases of builders. Experimental proof helps DeAL’s effectiveness in refining alignment, addressing LLMs’ residual gaps, and managing nuanced trade-offs, marking a major development in moral AI growth.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and Google News. Be part of our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our newsletter..
Don’t Neglect to affix our Telegram Channel
You might also like our FREE AI Courses….
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]
Source link
