


[ad_1]
Central to Pure Language Processing (NLP) developments are giant language fashions (LLMs), which have set new benchmarks for what machines can obtain in understanding and producing human language. One of many main challenges in NLP is the computational demand for autoregressive decoding in LLMs. This course of, important for duties like machine translation and content material summarization, requires substantial computational sources, making it much less possible for real-time functions or on units with restricted processing capabilities.
Present methodologies to deal with the computational depth of LLMs contain numerous mannequin compression methods like pruning quantization and parallel decoding methods. Information distillation is one other method the place a smaller mannequin learns from the outputs of bigger fashions. Parallel decoding goals to generate a number of tokens concurrently, nevertheless it raises challenges like output inconsistencies and estimating response size. Conditional approaches are utilized in multimodal studying, the place language fashions are conditioned on imaginative and prescient options or bigger encoders. Nevertheless, these approaches typically compromise the mannequin’s efficiency or fail to cut back the computational prices related to autoregressive decoding considerably.
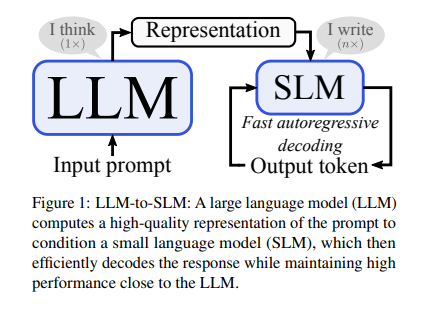
Researchers from the College of Potsdam, Qualcomm AI Analysis, and Amsterdam launched a novel hybrid method, combining LLMs with SLMs to optimize the effectivity of autoregressive decoding. This methodology employs a pretrained LLM to encode enter prompts in parallel, then circumstances an SLM to generate the following response. A considerable discount in decoding time with out considerably sacrificing efficiency is without doubt one of the necessary perks of this method.
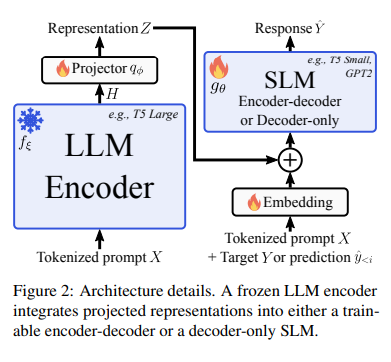
The modern LLM-to-SLM methodology enhances the effectivity of SLMs by leveraging the detailed immediate representations encoded by LLMs. This course of begins with the LLM encoding the immediate right into a complete illustration. A projector then adapts this illustration to the SLM’s embedding house, permitting the SLM to generate responses autoregressively. To make sure seamless integration, the tactic replaces or provides LLM representations into SLM embeddings, prioritizing early-stage conditioning to take care of simplicity. It aligns sequence lengths utilizing the LLM’s tokenizer, guaranteeing the SLM can interpret the immediate precisely, thus marrying the depth of LLMs with the agility of SLMs for environment friendly decoding.
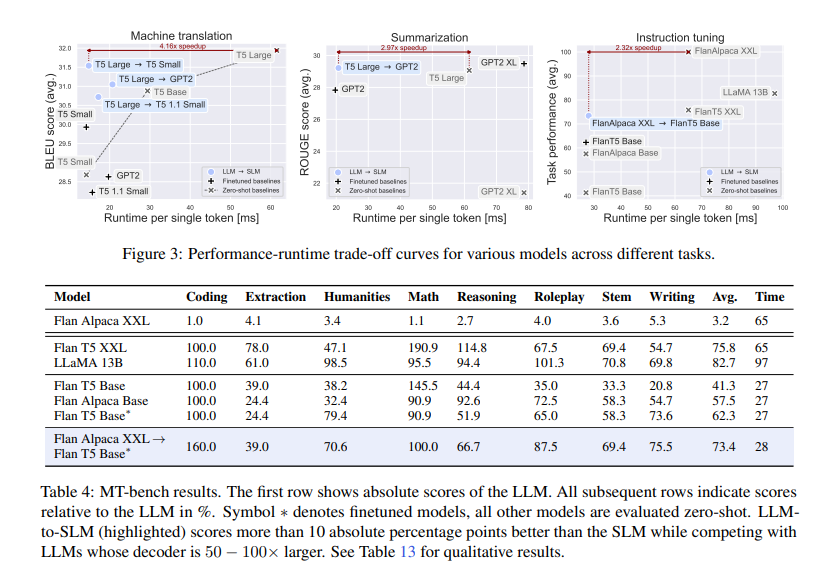
The proposed hybrid method achieved substantial speedups of as much as 4×, with minor efficiency penalties of 1 − 2% for translation and summarization duties in comparison with the LLM. The LLM-to-SLM method matched the efficiency of the LLM whereas being 1.5x sooner, in comparison with a 2.3x speedup of LLM-to-SLM alone. The analysis additionally reported extra outcomes for the interpretation job, displaying that the LLM-to-SLM method will be helpful for brief era lengths and that its FLOPs depend is much like that of the SLM.
In conclusion, the analysis presents a compelling answer to the computational challenges of autoregressive decoding in giant language fashions. By ingeniously combining the excellent encoding capabilities of LLMs with the agility of SLMs, the crew has opened new avenues for real-time language processing functions. This hybrid method maintains high-performance ranges and considerably reduces computational calls for, showcasing a promising path for future developments within the area.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and Google News. Be part of our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our newsletter..
Don’t Overlook to hitch our Telegram Channel
You may additionally like our FREE AI Courses….
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]
Source link
