

[ad_1]
When constructing machine studying (ML) fashions utilizing preexisting datasets, specialists within the discipline should first familiarize themselves with the info, decipher its construction, and decide which subset to make use of as options. A lot so {that a} primary barrier, the good vary of knowledge codecs, is slowing development in ML.
Textual content, structured information, images, audio, and video are just some content material classes in ML datasets. Even amongst datasets that embrace the identical material, there isn’t a customary structure of recordsdata or information codecs. This impediment lowers productiveness by means of machine studying improvement—from information discovery to mannequin coaching. Moreover, it makes it more durable to create important instruments for coping with big datasets.
Database metadata will be expressed in numerous codecs, together with schema.org and DCAT. Sadly, these codecs weren’t made with machine studying information in thoughts. ML information has distinctive necessities, like combining and extracting information from structured and unstructured sources, having metadata permitting for accountable information use, or describing ML utilization traits like coaching, check, and validation units.
Google has lately launched Croissant, a brand new format for metadata in ML-ready datasets. Together with the format specification, instance datasets, and open-source Python library for validating, consuming, and producing Croissant metadata, this 1.0 launch of Croissant additionally contains an open-source visible editor for loading, inspecting, and intuitively creating Croissant dataset descriptions.
Though it affords a constant methodology of describing and organizing information, the Croissant format doesn’t change the info’s precise illustration (equivalent to image or textual content file codecs). With over 40 million datasets at the moment utilizing it, schema.org is the gold customary for publishing structured information on-line, and Croissant is an extension of that customary. Croissant provides intensive layers for information assets, default ML semantics, metadata, and information administration to make it much more ML-relevant.
From the start, the first goal of the Croissant initiative was to advertise Accountable AI (RAI). As well as, the group additionally introduced the primary launch of the Croissant RAI vocabulary extension. This extension enhances Croissant by including properties that describe numerous RAI use circumstances. These embrace information life cycle administration, labeling, participatory information, ML security and equity analysis, explainability, compliance, and extra.
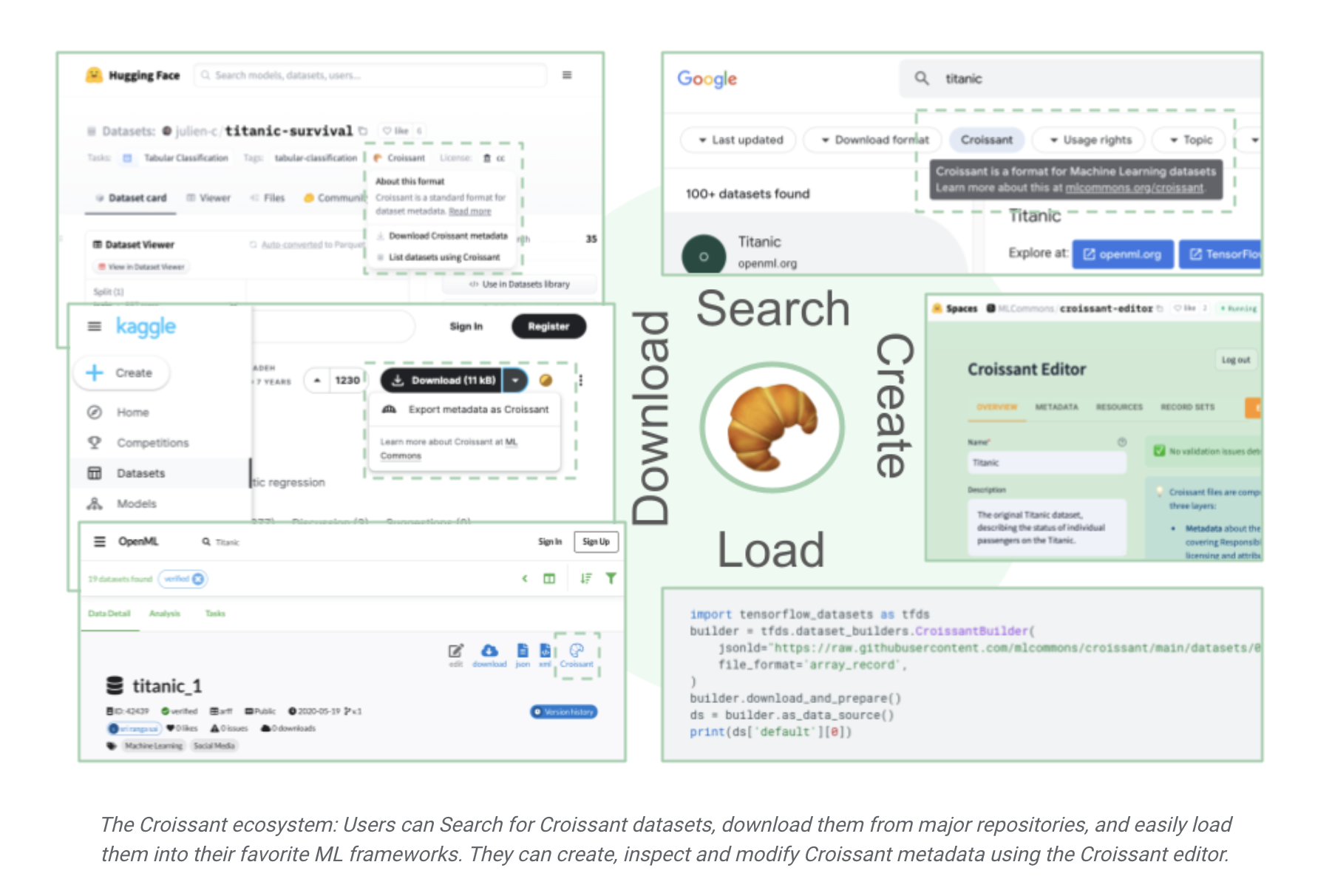
Dataset repositories and search engines like google can use metadata to assist customers find the proper dataset. The information assets and group info make instruments for information cleansing, refining, and evaluation simpler to design. Due to this metadata and default ML semantics, ML frameworks can use information for mannequin coaching and testing with little coding. Taken as an entire, these enhancements considerably reduce the load of knowledge improvement.
Dataset writers additionally prioritize their datasets’ discoverability and use. Due to the available technology instruments and help from ML information platforms, adopting Croissant enhances the worth of their datasets with no effort.
Use the Croissant editor’s consumer interface (GitHub) to look at and alter the metadata.
By evaluating the info the consumer provides, the Croissant editor UI (GitHub) could robotically construct a serious proportion of Croissant metadata. Necessary metadata fields, like RAI properties, can then be stuffed out. Customers can then publish their datasets.
Make the Croissant information simply discoverable and reusable by publishing it on their dataset web site.
Croissant metadata can be robotically generated if customers submit their information to a Croissant-compatible repository (e.g., OpenML, Kaggle, or HuggingFace).
Necessary instruments and repositories supporting this, together with Kaggle, Hugging Face, and OpenML, are three standard ML dataset collections that can begin supporting the Croissant format at present. Customers can seek for Croissant datasets on the net with the Dataset Search instrument. TensorFlow, PyTorch, and JAX, three standard ML frameworks, can load Croissant datasets simply with the TensorFlow Datasets (TFDS) bundle.
The researchers strongly counsel that platforms that host datasets make Croissant recordsdata obtainable for obtain and supply Croissant info on dataset net pages. This may assist dataset search engines like google discover them extra simply. Knowledge evaluation and labeling instruments, amongst others that help customers in working with ML datasets, also needs to take into account including help for Croissant datasets. Working collectively, the group believes we will ease the load of knowledge improvement and pave the best way for a extra sturdy ML analysis and improvement atmosphere.
Try the Blog and Project. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and Google News. Be a part of our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group
In the event you like our work, you’ll love our newsletter..
Don’t Neglect to affix our Telegram Channel
You may additionally like our FREE AI Courses….
Dhanshree Shenwai is a Pc Science Engineer and has a very good expertise in FinTech firms protecting Monetary, Playing cards & Funds and Banking area with eager curiosity in purposes of AI. She is smitten by exploring new applied sciences and developments in at present’s evolving world making everybody’s life straightforward.
[ad_2]
Source link
