


[ad_1]
Machine studying is witnessing speedy developments, particularly within the area of huge language fashions (LLMs). These fashions, which underpin numerous functions from language translation to content material creation, require common updates with new knowledge to remain related and efficient. Updating these fashions meant re-training them from scratch with every new dataset, which is time-consuming and requires important computational assets. This strategy poses a considerable barrier to sustaining cutting-edge fashions, because the computational prices can shortly turn out to be unsustainable.
Researchers from Université de Montréal, Concordia College, Mila, and EleutherAI have been exploring numerous methods to streamline the mannequin updating course of. Amongst these, “continuous pre-training” stands out as a promising answer. This strategy goals to replace LLMs by integrating new knowledge with out beginning the coaching course of from zero, thus preserving the information beforehand acquired by the mannequin. The important thing problem on this area is introducing new data to a mannequin with out erasing its current information, an issue referred to as catastrophic forgetting.
The research focuses on a complicated technique involving studying price changes and replaying a subset of the beforehand discovered knowledge. This technique’s essence lies in its skill to adapt the mannequin to new datasets whereas considerably lowering the computational load in comparison with conventional re-training strategies. The analysis highlights the effectiveness of adjusting the educational price by means of a course of referred to as re-warming and re-decaying, coupled with replaying a fraction of previous knowledge to assist the mannequin retain beforehand discovered data.
The strategy proposed by the researchers provides a number of compelling benefits:
- It demonstrates that LLMs will be effectively up to date with new knowledge by means of a easy and scalable methodology.
- The mannequin can adapt to new datasets with out shedding important information from the earlier datasets by using a mixture of studying price re-adjustments and selective knowledge replay.
- The strategy proves efficient throughout numerous situations, together with the transition between datasets of various languages, showcasing its versatility.
- This strategy matches the efficiency of totally re-trained fashions, reaching this with solely a fraction of the computational assets.
Intimately, the approach includes exactly manipulating the educational price to facilitate the mannequin’s adaptation to new datasets. That is achieved by growing the educational price (re-warming) on the onset of coaching on new knowledge and steadily reducing it after that (re-decaying). A fastidiously chosen portion of the earlier dataset is replayed throughout coaching. This twin technique permits the mannequin to combine new data effectively whereas mitigating the chance of catastrophic forgetting.
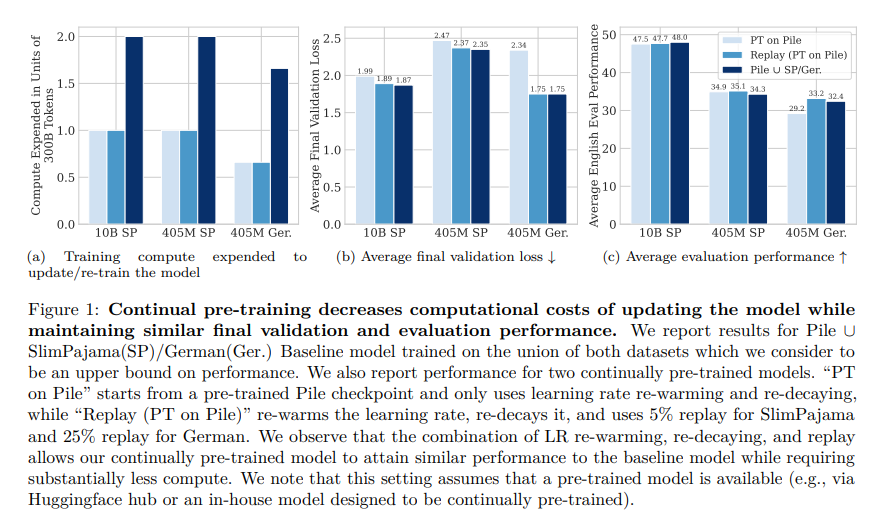
The research’s findings present that their methodology achieves comparable outcomes to the standard, computationally intensive re-training strategy and does so extra effectively. This analysis advances in continuous studying, presenting a viable and cost-effective methodology for updating LLMs. By lowering the computational calls for of the updating course of, this strategy makes it extra possible for organizations to take care of present and high-performing fashions.
In conclusion, this analysis offers a novel answer to the computational challenges of updating LLMs. Via a mixture of studying price changes and knowledge replay, the research demonstrates a way that maintains the relevancy and effectiveness of LLMs within the face of evolving datasets. This strategy not solely signifies a leap in machine studying effectivity but additionally opens up new prospects for growing and sustaining cutting-edge language fashions.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our newsletter..
Don’t Overlook to hitch our 38k+ ML SubReddit
Whats up, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m presently pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m keen about expertise and need to create new merchandise that make a distinction.
[ad_2]
Source link
