

[ad_1]
Knowledge scientists and engineers regularly collaborate on machine studying ML duties, making incremental enhancements, iteratively refining ML pipelines, and checking the mannequin’s generalizability and robustness. There are main worries about information traceability and reproducibility as a result of, not like code, information modifications don’t at all times present sufficient details about the precise supply information used to create the printed information and the transformations made to every supply.
To construct a well-documented ML pipeline, information traceability is essential. It ensures that the information used to coach the fashions is correct and helps them adjust to guidelines and greatest practices. Monitoring the unique information’s utilization, transformation, and compliance with licensing necessities turns into tough with out satisfactory documentation. Datasets may be discovered on information.gov and Accutus1, two open information portals and sharing platforms; nonetheless, information transformations are not often offered. Due to this lacking info, replicating the outcomes is harder, and individuals are much less prone to settle for the information.
An information repository undergoes exponential adjustments because of the myriad of potential transformations. Many columns, tables, all kinds of features, and new information varieties are commonplace in such updates. Transformation discovery strategies are generally employed to make clear variations throughout information repository desk variations. The programming-by-example (PBE) strategy is normally used when they should create a program that takes an enter and turns it into an output. Nevertheless, their inflexibility makes them ill-suited to take care of sophisticated and diverse information sorts and transformations. Moreover, they battle to regulate to altering information distributions or unfamiliar domains.
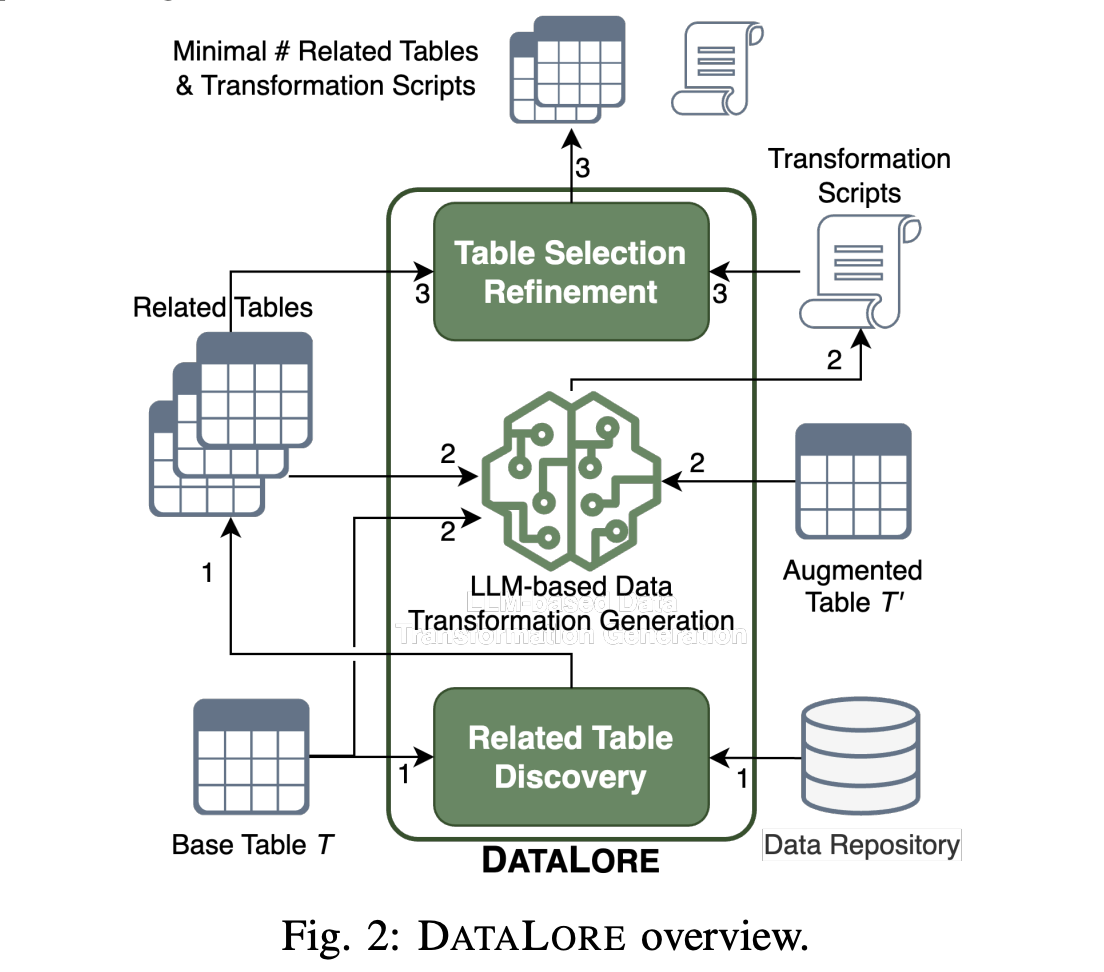
A staff of AI researchers and engineers at Amazon labored collectively to construct ML pipelines utilizing DATALORE, a brand new machine studying system that robotically generates information transformations amongst tables in a shared information repository. DATALORE employs a generative technique to resolve the lacking information transformation difficulty. DATALORE makes use of Giant Language Fashions (LLMs) to cut back semantic ambiguity and guide work as an information transformation synthesis software. These fashions have been skilled on billions of strains of code. Second, for every offered base desk T, the researchers use information discovery algorithms to search out potential associated candidate tables. This facilitates a sequence of information transformations and enhances the effectiveness of the proposed LLM-based system. The third step in acquiring the improved desk is for DATALORE to stick to the Minimal Description Size idea, which reduces the variety of linked tables. This improves DATALORE’s effectivity by avoiding the pricey investigation of search areas.
Examples of DATALORE utilization.
Customers can benefit from DATALORE’s information governance, information integration, and machine studying companies, amongst others, on cloud computing platforms like Amazon Net Companies, Microsoft Azure, and Google Cloud. Nevertheless, discovering appropriate tables or datasets to look queries and manually checking their validity and usefulness may be time-consuming for service customers.
There are 3 ways wherein DATALORE enhances the person expertise:
- DATALORE’s associated desk discovery can enhance search outcomes by sorting related tables (each semantic and transformation-based) into distinct classes. Via an offline methodology, DATALORE may be utilized to search out datasets derived from those they presently have. This info will then be listed as a part of an information catalog.
- Including extra particulars about linked tables in a database to the information catalog mainly helps statistical-based search algorithms overcome their limitations.
- Moreover, by displaying the potential transformations between a number of tables, DATALORE’s LLM-based information transformation technology can considerably improve the return outcomes’ explainability, notably helpful for customers thinking about any linked desk.
- Bootstrapping ETL pipelines utilizing the offered information transformation tremendously reduces the person’s burden of writing their code. To attenuate the potential for errors, the person should repeat and examine every step of the machine-learning workflow.
- DATALORE’s desk choice refinement recovers information transformations throughout a couple of linked tables to make sure the person’s dataset may be reproduced and forestall errors within the ML workflow.
The staff employs Auto-Pipeline Benchmark (APB) and Semantic Knowledge Versioning Benchmark (SDVB). Take into account that pipelines comprising many tables are maintained utilizing a be part of. To make sure that each datasets cowl all forty varied sorts of transformation features, they modify them so as to add additional transformations. A state-of-the-art methodology that produces information transformations to elucidate adjustments between two provided dataset variations, Clarify-DaV (EDV), is in comparison with the DATALORE. The researchers selected a 60-second delay for each methods, mimicking EDV’s default, as a result of producing transformations in DATALORE and EDV has exponential worst-case temporal complexity. Moreover, with DATALORE, they cap the utmost variety of columns utilized in a multi-column transformation at 3.
Within the SDVB benchmark, 32% of the check instances are associated to numerical-to-numerical transformations. As a result of it will possibly deal with numeric, textual, and categorical information, DATALORE usually beats EDV in each class. As a result of transformations with a be part of are solely supported by DATALORE, additionally they see an even bigger efficiency margin over the APB dataset. When DATALORE was in contrast with EDV throughout many transformation classes, the researchers discovered that it excels in text-to-text and text-to-numerical transformations. The intricacy of DATALORE means there may be nonetheless house for improvement concerning numeric-to-numeric and numeric-to-categorical transformations.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our newsletter..
Don’t Overlook to affix our 39k+ ML SubReddit
Dhanshree Shenwai is a Laptop Science Engineer and has expertise in FinTech firms protecting Monetary, Playing cards & Funds and Banking area with eager curiosity in purposes of AI. She is smitten by exploring new applied sciences and developments in right now’s evolving world making everybody’s life simple.
[ad_2]
Source link
