


[ad_1]

Photograph by Towfiqu barbhuiya on Unsplash
There isn’t any scarcity of textual content knowledge accessible at the moment. Huge quantities of textual content are created each day, with this knowledge starting from totally structured to semi-structured to completely unstructured.
What can we do with this textual content? Nicely, fairly a bit, really; relying on precisely what your goals are, there are 2 intricately associated but differentiated umbrellas of duties which may be exploited with a view to leverage the supply of all of this knowledge.
Let’s begin with some definitions.
Pure language processing (NLP) issues itself with the interplay between pure human languages and computing gadgets. NLP is a significant facet of computational linguistics, and likewise falls inside the realms of laptop science and synthetic intelligence.
Textual content mining exists in the same realm as NLP, in that it’s involved with figuring out attention-grabbing, non-trivial patterns in textual knowledge.
As you could possibly inform from the above, the precise boundaries of those 2 ideas usually are not well-defined and agreed-upon, and bleed into each other to various levels, relying on the practitioners and researchers with whom one would talk about such issues. I discover it best to distinguish by diploma of perception. If uncooked textual content is knowledge, then textual content mining can extract info, whereas NLP extracts information (see the Pyramid of Understanding beneath). Syntax versus semantics, if you’ll.
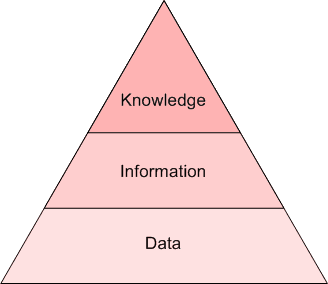
The Pyramid of Understanding: knowledge, info, information
Varied different explanations as to the exact relationship between textual content mining and NLP exist, and you might be free to search out one thing that works higher for you. We aren’t actually as involved with the precise definitions — absolute or relative — as a lot as we’re with the intuitive recognition that the ideas are associated with some overlap, but nonetheless distinct.
The purpose we are going to transfer ahead with: though NLP and textual content mining usually are not the identical factor, they’re carefully associated, cope with the identical uncooked knowledge kind, and have some crossover of their makes use of. For the rest of our dialogue, we are going to conveniently refer to those 2 ideas as NLP. Importantly, a lot of the preprocessing of information for the duties falling below these 2 umbrellas is equivalent.
Whatever the precise NLP process you want to carry out, sustaining textual content that means and avoiding ambiguity is paramount. As such, makes an attempt to keep away from ambiguity is a big a part of the textual content preprocessing course of. We need to protect supposed that means whereas eliminating noise. So as to take action, the next is required:
- Data about language
- Data in regards to the world
- A technique to mix information sources
If this have been straightforward, we possible would not be speaking about it. What are some the explanation why processing textual content is tough?

Supply: CS124 Stanford (https://net.stanford.edu/class/cs124/)
You will have seen one thing curious in regards to the above: “non-standard English.” Whereas actually not the intention of the determine — we’re taking it totally out of context right here — for quite a lot of causes, a lot of NLP analysis has traditionally taken place inside the confines of the English language. So we will add to the query of “Why is processing textual content tough?” the extra layers of hassle which non-English languages — and particularly languages with smaller numbers of audio system, and even endangered languages — should undergo with a view to be processed and have insights drawn from.

Image by rawpixel.com on Freepik
Simply being cognizant of the truth that NLP ≠ English when considering and talking about NLP is one small means wherein this bias may be stemmed.
Can we craft a sufficiently common framework for approaching textual knowledge science duties? It seems that processing textual content is similar to different non-text processing duties, and so we will look to the KDD Process for inspiration.
We are able to say that these are the principle steps of a generic text-based process, one which falls below textual content mining or NLP.
1. Knowledge Assortment or Meeting
- Acquire or construct corpus, which might be something from emails, to the complete set of English Wikipedia articles, to our firm’s monetary reviews, to the whole works of Shakespeare, to one thing completely different altogether
2. Knowledge Preprocessing
- Carry out the preparation duties on the uncooked textual content corpus in anticipation of textual content mining or NLP process
- Knowledge preprocessing consists of quite a few steps, any variety of which can or not apply to a given process, however usually fall below the broad classes of tokenization, normalization, and substitution
3. Knowledge Exploration & Visualization
- No matter what our knowledge is — textual content or not — exploring and visualizing it’s an important step in gaining perception
- Widespread duties might embody visualizing phrase counts and distributions, producing wordclouds, and performing distance measures
4. Mannequin Constructing
- That is the place our bread and butter textual content mining or NLP process takes place (contains coaching and testing)
- Additionally contains characteristic choice & engineering when relevant
- Language fashions: Finite state machines, Markov fashions, vector house modeling of phrase meanings
- Machine studying classifiers: Naive bayes, logistic regression, choice timber, Help Vector Machines, neural networks
- Sequence fashions: Hidden Markov fashions, recursive neural networks (RNNs), Lengthy brief time period reminiscence neural networks (LSTMs)
5. Mannequin Analysis
- Did the mannequin carry out as anticipated?
- Metrics will differ depending on what kind of textual content mining or NLP process
- Even considering outdoors of the field with chatbots (an NLP process) or generative fashions: some type of analysis is important
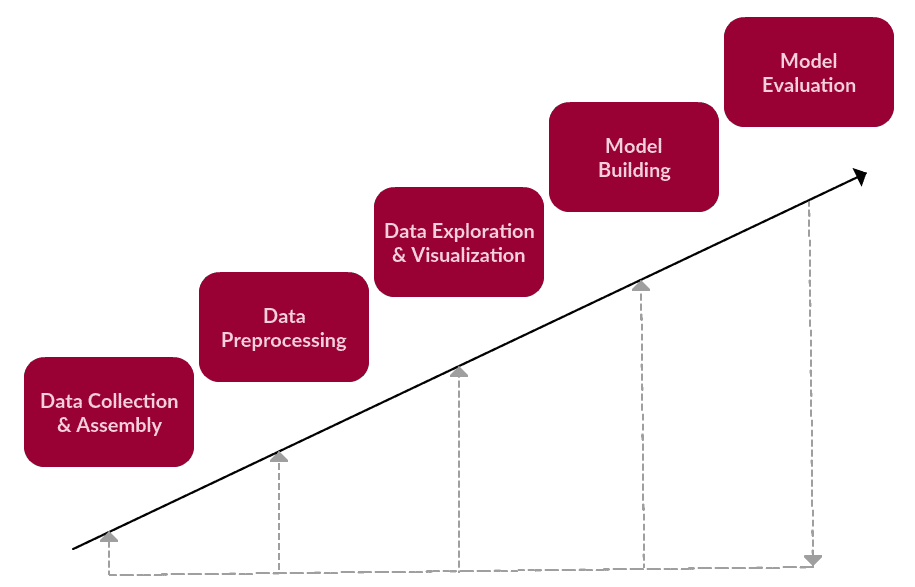
A easy textual knowledge process framework
Clearly, any framework centered on the preprocessing of textual knowledge must be synonymous with step quantity 2. Increasing upon this step, particularly, we had the next to say about what this step would possible entail:
- Carry out the preparation duties on the uncooked textual content corpus in anticipation of textual content mining or NLP process
- Knowledge preprocessing consists of quite a few steps, any variety of which can or not apply to a given process, however usually fall below the broad classes of tokenization, normalization, and substitution
- Extra usually, we’re enthusiastic about taking some predetermined physique of textual content and performing upon it some fundamental evaluation and transformations, with a view to be left with artefacts which shall be rather more helpful for performing some additional, extra significant analytic process afterward. This additional process could be our core textual content mining or pure language processing work.
So, as talked about above, it appears as if there are 3 principal parts of textual content preprocessing:
- tokenization
- normalization
- subsitution
As we lay out a framework for approaching preprocessing, we should always preserve these high-level ideas in thoughts.
We are going to introduce this framework conceptually, unbiased of instruments. We are going to then followup with a sensible implementation of those steps subsequent time, with a view to see how they’d be carried out within the Python ecosystem.
The sequence of those duties shouldn’t be essentially as follows, and there may be some iteration upon them as nicely.
1. Noise Removing
Noise elimination performs among the substitution duties of the framework. Noise elimination is a way more task-specific part of the framework than are the next steps.
Take note once more that we aren’t coping with a linear course of, the steps of which should completely be utilized in a specified order. Noise elimination, due to this fact, can happen earlier than or after the previously-outlined sections, or in some unspecified time in the future between).
Corpus (actually Latin for physique) refers to a set of texts. Such collections could also be shaped of a single language of texts, or can span a number of languages; there are quite a few causes for which multilingual corpora (the plural of corpus) could also be helpful. Corpora can also encompass themed texts (historic, Biblical, and many others.). Corpora are usually solely used for statistical linguistic evaluation and speculation testing.
How about one thing extra concrete. Let’s assume we obtained a corpus from the world vast net, and that it’s housed in a uncooked net format. We are able to, then, assume that there’s a excessive probability our textual content might be wrapped in HTML or XML tags. Whereas this accounting for metadata can happen as a part of the textual content assortment or meeting course of (step 1 of our textual knowledge process framework), it depends upon how the info was acquired and assembled. Typically we now have management of this knowledge assortment and meeting course of, and so our corpus might have already got been de-noised throughout assortment.
However this isn’t all the time the case. If the corpus you occur to be utilizing is noisy, it’s important to cope with it. Recall that analytics duties are sometimes talked about as being 80% knowledge preparation!
The nice factor is that sample matching may be your good friend right here, as can current software program instruments constructed to cope with simply such sample matching duties.
- take away textual content file headers, footers
- take away HTML, XML, and many others. markup and metadata
- extract useful knowledge from different codecs, comparable to JSON, or from inside databases
- for those who concern common expressions, this might probably be the a part of textual content preprocessing wherein your worst fears are realized
Common expressions, typically abbreviated regexp or regexp, are a tried and true methodology of concisely describing patterns of textual content. A daily expression is represented as a particular textual content string itself, and is supposed for creating search patterns on picks of textual content. Common expressions may be considered an expanded algorithm past the wildcard characters of ? and *. Although typically cited as irritating to study, common expressions are extremely highly effective textual content looking out instruments.
As you possibly can think about, the boundary between noise elimination and knowledge assortment and meeting is a fuzzy one, and as such some noise elimination should completely happen earlier than different preprocessing steps. For instance, any textual content required from a JSON construction would clearly should be eliminated previous to tokenization.
2. Normalization
Earlier than additional processing, textual content must be normalized.
Normalization usually refers to a collection of associated duties meant to place all textual content on a degree taking part in subject: changing all textual content to the identical case (higher or decrease), eradicating punctuation, increasing contractions, changing numbers to their phrase equivalents, and so forth. Normalization places all phrases on equal footing, and permits processing to proceed uniformly.
Normalizing textual content can imply performing quite a few duties, however for our framework we are going to method normalization in 3 distinct steps: (1) stemming, (2) lemmatization, and (3) all the things else.
working → run
For instance, stemming the phrase “higher” would fail to return its quotation kind (one other phrase for lemma); nonetheless, lemmatization would end result within the following:
higher → good
It needs to be straightforward to see why the implementation of a stemmer could be the more easy feat of the 2.
The whole lot else
A intelligent catch-all, proper? Stemming and lemmatization are main components of a textual content preprocessing endeavor, and as such they should be handled with the respect they deserve. These aren’t easy textual content manipulation; they depend on detailed and nuanced understanding of grammatical guidelines and norms.
There are, nonetheless, quite a few different steps that may be taken to assist put all textual content on equal footing, lots of which contain the comparatively easy concepts of substitution or elimination. They’re, nonetheless, no much less necessary to the general course of. These embody:
- set all characters to lowercase
- take away numbers (or convert numbers to textual representations)
- take away punctuation (usually a part of tokenization, however nonetheless value protecting in thoughts at this stage, whilst affirmation)
- strip white house (additionally usually a part of tokenization)
- take away default cease phrases (common English cease phrases)
The fast brown fox jumps over the lazy canine.
- take away given (task-specific) cease phrases
- take away sparse phrases (not all the time essential or useful, although!)
A this level, it needs to be clear that textual content preprocessing depends closely on pre-built dictionaries, databases, and guidelines. You may be relieved to search out that after we undertake a sensible textual content preprocessing process within the Python ecosystem in our subsequent article that these pre-built assist instruments are available for our use; there isn’t any should be inventing our personal wheels.
3. Tokenization
Tokenization is, usually, an early step within the NLP course of, a step which splits longer strings of textual content into smaller items, or tokens. Bigger chunks of textual content may be tokenized into sentences, sentences may be tokenized into phrases, and many others. Additional processing is usually carried out after a chunk of textual content has been appropriately tokenized.
Tokenization can also be known as textual content segmentation or lexical evaluation. Typically segmentation is used to check with the breakdown of a big chunk of textual content into items bigger than phrases (e.g. paragraphs or sentences), whereas tokenization is reserved for the breakdown course of which ends completely in phrases.
This will sound like a simple course of, however it’s something however. How are sentences recognized inside bigger our bodies of textual content? Off the highest of your head you in all probability say “sentence-ending punctuation,” and will even, only for a second, suppose that such an announcement is unambiguous.
Certain, this sentence is well recognized with some fundamental segmentation guidelines:
The short brown fox jumps over the lazy canine.
However what about this one:
Dr. Ford didn't ask Col. Mustard the identify of Mr. Smith's canine.
Or this one:
"What's all of the fuss about?" requested Mr. Peters.
And that is simply sentences. What about phrases? Simple, proper? Proper?
This full-time scholar is not dwelling in on-campus housing, and she or he's not wanting to go to Hawai'i.
It needs to be intuitive that there are various methods not just for figuring out section boundaries, but in addition what to do when boundaries are reached. For instance, we would make use of a segmentation technique which (appropriately) identifies a selected boundary between phrase tokens because the apostrophe within the phrase she’s (a method tokenizing on whitespace alone wouldn’t be adequate to acknowledge this). However we may then select between competing methods comparable to protecting the punctuation with one a part of the phrase, or discarding it altogether. One among these approaches simply appears right, and doesn’t appear to pose an actual drawback. However simply consider all the opposite particular circumstances in simply the English language we must have in mind.
Consideration: after we section textual content chunks into sentences, ought to we protect sentence-ending delimiters? Are we enthusiastic about remembering the place sentences ended?
We’ve lined some textual content (pre)processing steps helpful for NLP duties, however what in regards to the duties themselves?
There are not any arduous traces between these process varieties; nonetheless, many are pretty well-defined at this level. A given macro NLP process might embody quite a lot of sub-tasks.
We first outlined the principle approaches, for the reason that applied sciences are sometimes centered on for inexperienced persons, but it surely’s good to have a concrete thought of what sorts of NLP duties there are. Under are the principle classes of NLP duties.
1. Textual content Classification Duties
- Illustration: bag of phrases, n-grams, one-hot encoding (sparse matrix) – these strategies don’t protect phrase order
- Aim: predict tags, classes, sentiment
- Utility: filtering spam emails, classifying paperwork primarily based on dominant content material
Precise storage mechanisms for the bag of phrases illustration can differ, however the next is an easy instance utilizing a dictionary for intuitiveness. Pattern textual content:
"Nicely, nicely, nicely," stated John.
“There, there,” stated James. “There, there.”
The ensuing bag of phrases illustration as a dictionary:
{
'nicely': 3,
'stated': 2,
'john': 1,
'there': 4,
'james': 1
}
An instance of trigram (3-gram) mannequin of the second sentence of the above instance (“There, there,” stated James. “There, there.”) seems as a listing illustration beneath:
[
"there there said",
"there said james",
"said james there",
"james there there",
]
Previous to the wide-spread use of neural networks in NLP — in what we are going to check with as “conventional” NLP — vectorization of textual content typically occurred through one-hot encoding (notice that this persists as a helpful encoding observe for quite a few workouts, and has not fallen out of trend resulting from using neural networks). For one-hot encoding, every phrase, or token, in a textual content corresponds to a vector ingredient.
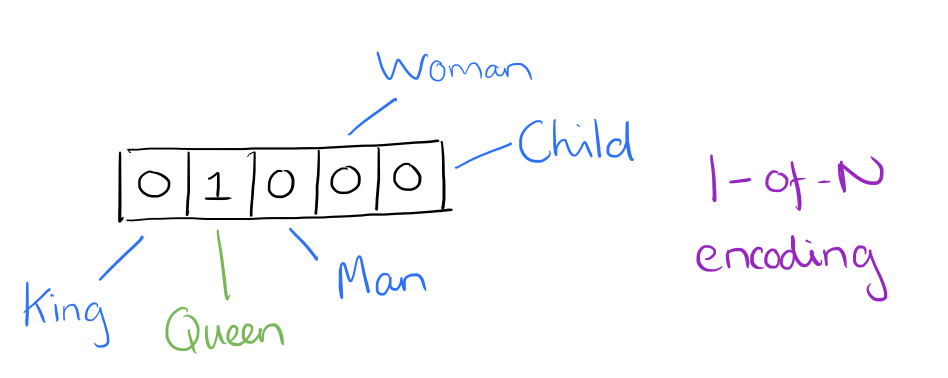
Supply: Adrian Colyer
We may think about the picture above, for instance, as a small excerpt of a vector representing the sentence “The queen entered the room.” Word that solely the ingredient for “queen” has been activated, whereas these for “king,” “man,” and many others. haven’t. You’ll be able to think about how in another way the one-hot vector illustration of the sentence “The king was as soon as a person, however is now a toddler” would seem in the identical vector ingredient part pictured above.
2. Phrase Sequence Duties
- Illustration: sequences (preserves phrase order)
- Aim: language modeling – predict subsequent/earlier phrase(s), textual content era
- Utility: translation, chatbots, sequence tagging (predict POS tags for every phrase in sequence), named entity recognition
Language modeling is the method of constructing a statistical language mannequin which is supposed to supply an estimate of a pure language. For a sequence of enter phrases, the mannequin would assign a likelihood to the complete sequence, which contributes to the estimated probability of varied doable sequences. This may be particularly helpful for NLP functions which generate or predict textual content.
3. Textual content Which means Duties
- Illustration: phrase vectors, the mapping of phrases to vectors (n-dimensional numeric vectors) aka embeddings
- Aim: how will we signify that means?
- Utility: discovering comparable phrases (comparable vectors), sentence embeddings (versus phrase embeddings), matter modeling, search, query answering
Dense embedding vectors aka phrase embeddings end result within the illustration of core options embedded into an embedding house of dimension d dimensions. We are able to compress, if you’ll, the variety of dimensions used to signify 20,000 distinctive phrases right down to, maybe, 50 or 100 dimensions. On this method, every characteristic now not has its personal dimension, and is as a substitute mapped to a vector.
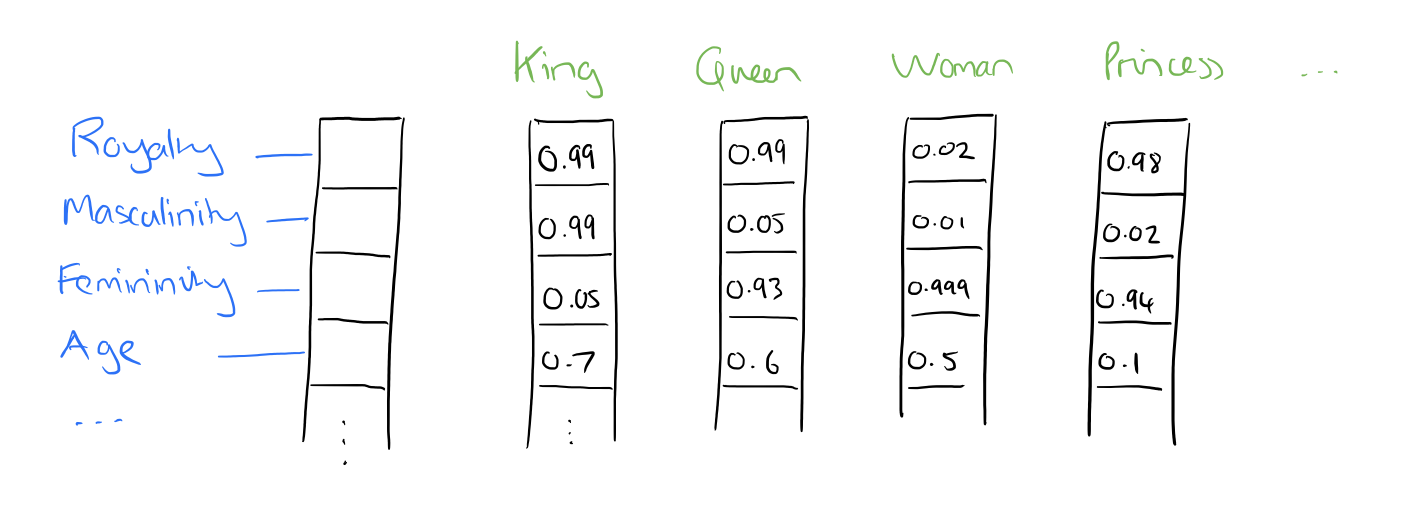
Supply: Adrian Colyer
So, what precisely are these options? We depart it to a neural community to find out the necessary facets of relationships between phrases. Although human interpretation of those options wouldn’t be exactly doable, the picture above supplies an perception into what the underlying course of might appear to be, regarding the well-known King - Man + Girl = Queen example.

Named entity recognition (NER) utilizing spaCy (textual content excerpt taken from here)
Half-of-speech tagging consists of assigning a class tag to the tokenized components of a sentence. The preferred POS tagging could be figuring out phrases as nouns, verbs, adjectives, and many others.
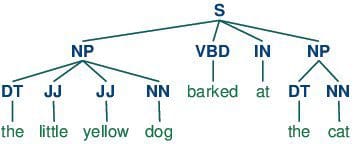
Half-of-speech tagging
4. Sequence to Sequence Duties
- Many duties in NLP may be framed as such
- Examples are machine translation, summarization, simplification, Q&A techniques
- Such techniques are characterised by encoders and decoders, which work in complement to discover a hidden illustration of textual content, and to make use of that hidden illustration
5. Dialog Programs
- 2 principal classes of dialog techniques, categorized by their scope of use
- Aim-oriented dialog techniques deal with being helpful in a selected, restricted area; extra precision, much less generalizable
- Conversational dialog techniques are involved with being useful or entertaining in a way more common context; much less precision, extra generalization
Whether or not it’s in dialog techniques or the sensible distinction between rule-based and extra advanced approaches to fixing NLP duties, notice the trade-off between precision and generalizability; you usually sacrifice in a single space for a rise within the different.
Whereas not minimize and dry, there are 3 principal teams of approaches to fixing NLP duties.
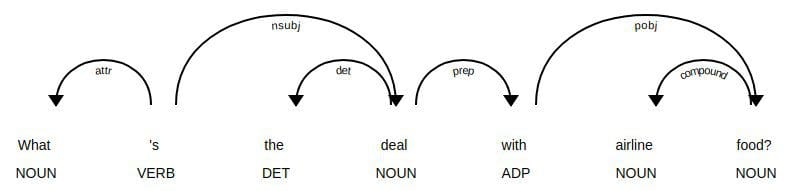
Dependency parse tree utilizing spaCy
1. Rule-based
Rule-based approaches are the oldest approaches to NLP. Why are they nonetheless used, you would possibly ask? It is as a result of they’re tried and true, and have been confirmed to work nicely. Guidelines utilized to textual content can provide a variety of perception: consider what you possibly can study arbitrary textual content by discovering what phrases are nouns, or what verbs finish in -ing, or whether or not a sample recognizable as Python code may be recognized. Regular expressions and context free grammars are textbook examples of rule-based approaches to NLP.
Rule-based approaches:
- are likely to deal with pattern-matching or parsing
- can typically be considered “fill within the blanks” strategies
- are low precision, excessive recall, that means they’ll have excessive efficiency in particular use circumstances, however typically undergo efficiency degradation when generalized
2. “Conventional” Machine Studying
“Conventional” machine studying approaches embody probabilistic modeling, probability maximization, and linear classifiers. Notably, these usually are not neural community fashions (see these beneath).
Conventional machine studying approaches are characterised by:
- coaching knowledge – on this case, a corpus with markup
- characteristic engineering – phrase kind, surrounding phrases, capitalized, plural, and many others.
- coaching a mannequin on parameters, adopted by becoming on take a look at knowledge (typical of machine studying techniques usually)
- inference (making use of mannequin to check knowledge) characterised by discovering most possible phrases, subsequent phrase, greatest class, and many others.
- “semantic slot filling”
3. Neural Networks
That is just like “conventional” machine studying, however with a couple of variations:
- characteristic engineering is usually skipped, as networks will “study” necessary options (that is usually one of many claimed massive advantages of utilizing neural networks for NLP)
- as a substitute, streams of uncooked parameters (“phrases” — really vector representations of phrases) with out engineered options, are fed into neural networks
- very giant coaching corpus
Particular neural networks of use in NLP have “traditionally” included recurrent neural networks (RNNs) and convolutional neural networks (CNNs). Right now, the one structure that guidelines all of them is the transformer.
Why use “conventional” machine studying (or rule-based) approaches for NLP?
- nonetheless good for sequence labeling (utilizing probabilistic modeling)
- some concepts in neural networks are similar to earlier strategies (word2vec comparable in idea to distributional semantic strategies)
- use strategies from conventional approaches to enhance neural community approaches (for instance, phrase alignments and a spotlight mechanisms are comparable)
Why deep studying over “conventional” machine studying?
- SOTA in lots of functions (for instance, machine translation)
- a variety of analysis (majority?) in NLP occurring right here now
Importantly, each neural community and non-neural community approaches may be helpful for modern NLP in their very own proper; they’ll additionally can be utilized or studied in tandem for max potential profit
References
- From Languages to Information, Stanford
- Natural Language Processing, Nationwide Analysis College Increased Faculty of Economics (Coursera)
- Neural Network Methods for Natural Language Processing, Yoav Goldberg
- Natural Language Processing, Yandex Knowledge Faculty
- The amazing power of word vectors, Adrian Colyer
Matthew Mayo (@mattmayo13) is a Knowledge Scientist and the Editor-in-Chief of KDnuggets, the seminal on-line Knowledge Science and Machine Studying useful resource. His pursuits lie in pure language processing, algorithm design and optimization, unsupervised studying, neural networks, and automatic approaches to machine studying. Matthew holds a Grasp’s diploma in laptop science and a graduate diploma in knowledge mining. He may be reached at editor1 at kdnuggets[dot]com.
[ad_2]
Source link
