


[ad_1]
We work together with machines every day – whether or not it is asking “OK Google, set the alarm for six AM” or “Alexa, play my favourite playlist”. However these machines don’t perceive pure language. So what occurs after we discuss to a tool? It must convert the speech i.e. textual content to numbers for processing the data and studying the context. On this submit, you’ll study one of the in style instruments to transform the language to numbers utilizing CountVectorizer. Scikit-learn’s CountVectorizer is used to recast and preprocess corpora of textual content to a token rely vector illustration.

Source
Let’s take an instance of a ebook title from a preferred children’ ebook for example how CountVectorizer works.
textual content = ["Brown Bear, Brown Bear, What do you see?"]
There are six distinctive phrases within the vector; thus the size of the vector illustration is six. The vector represents the frequency of prevalence of every token/phrase within the textual content.

Let’s add one other doc to our corpora to witness how the dimension of the ensuing matrix will increase.
textual content = ["Brown Bear, Brown Bear, What do you see?", “I love you to the moon and back”]
The CountVectorizer would produce the under output, the place the matrix turns into a 2 X 13 from 1 X 6 by including yet another doc.

Every column within the matrix represents a novel token (phrase) within the dictionary shaped by a union of all tokens from the corpus of paperwork, whereas every row represents a doc. The above instance has two ebook titles i.e. paperwork represented by two rows the place every cell accommodates a worth figuring out the corresponding phrase rely within the doc. Because of such illustration, sure cells have zero worth wherever the token is absent within the corresponding doc.
Notably, it turns into unmanageable to retailer enormous matrices in reminiscence with the rising dimension of the corpora. Thus, CountVectorizer shops them as a sparse matrix, a compressed type of the full-blown matrix mentioned above.
Let’s choose the Harry Potter collection of eight films and one Indiana Jones film for this demo. This might assist us perceive some essential attributes of CountVectorizer.
Begin with importing Pandas library and CountVectorizer from Sklearn > feature_extraction > textual content.
import pandas as pd from sklearn.feature_extraction.textual content import CountVectorizer
Declare the paperwork as an inventory of strings.
textual content = [
"Harry Potter and the Philosopher's Stone",
"Harry Potter and the Chamber of Secrets",
"Harry Potter and the Prisoner of Azkaban",
"Harry Potter and the Goblet of Fire",
"Harry Potter and the Order of the Phoenix",
"Indiana Jones and the Raiders of the Lost Ark",
"Harry Potter and the Half-Blood Prince",
"Harry Potter and the Deathly Hallows - Part 1",
"Harry Potter and the Deathly Hallows - Part 2"
]
Vectorization
Initialize the CountVectorizer object with lowercase=True (default worth) to transform all paperwork/strings into lowercase. Subsequent, name fit_transform and go the listing of paperwork as an argument adopted by including column and row names to the information body.
count_vector = CountVectorizer(lowercase = True) count_vektor = count_vector.fit_transform(textual content) count_vektor = count_vektor.toarray() df = pd.DataFrame(information = count_vektor, columns = count_vector.get_feature_names()) df.index = textual content df
Excellent news! The paperwork are transformed to numbers. However, a detailed look exhibits that “Harry Potter and the Order of the Phoenix” is much like “Indiana Jones and the Raiders of the Misplaced Ark” as in comparison with different Harry Potter films – a minimum of on the first look.
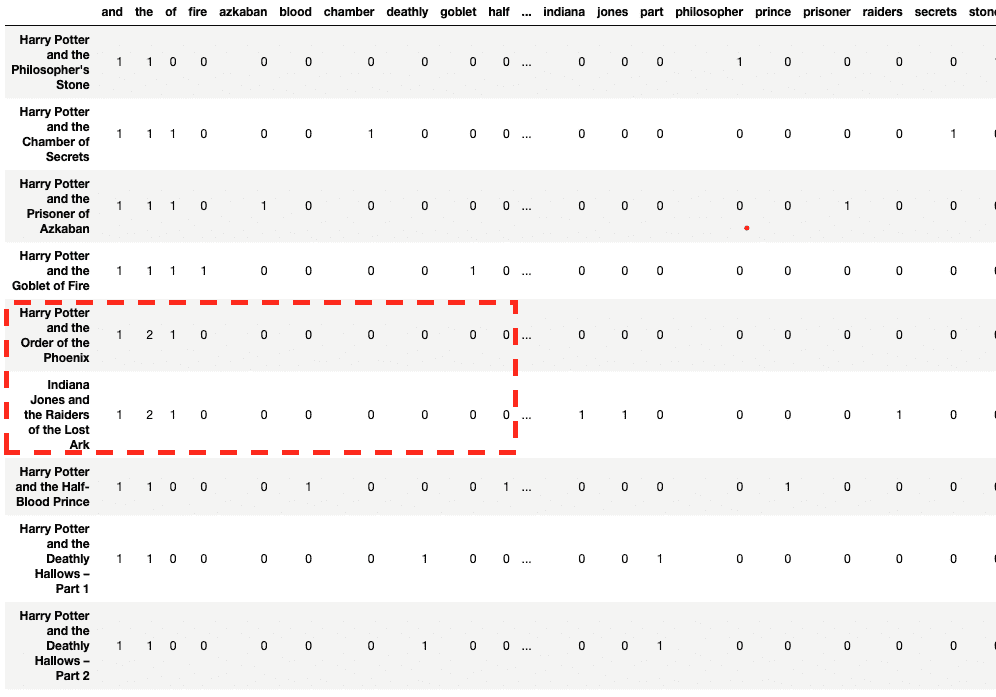
You have to be questioning if tokens like ‘and’, ‘the’, and ‘of’ add any data to our function set. That takes us to our subsequent step i.e. eradicating cease phrases.
stop_words
Uninformative tokens like ‘and’, ‘the’, and ‘of’ are known as cease phrases. It is very important take away cease phrases as they impression the doc’s similarity and unnecessarily increase the column dimension.
Argument ‘stop_words’ removes such preidentified cease phrases – specifying ‘english’ removes English-specific cease phrases. You may also explicitly add an inventory of cease phrases i.e. stop_words = [‘and’, ‘of’, ‘the’].
count_vector = CountVectorizer(lowercase = True, stop_words="english") count_vektor = count_vector.fit_transform(textual content) count_vektor = count_vektor.toarray() df = pd.DataFrame(information = count_vektor, columns = count_vector.get_feature_names()) df.index = textual content df
Appears higher! Now the row vectors look extra significant.
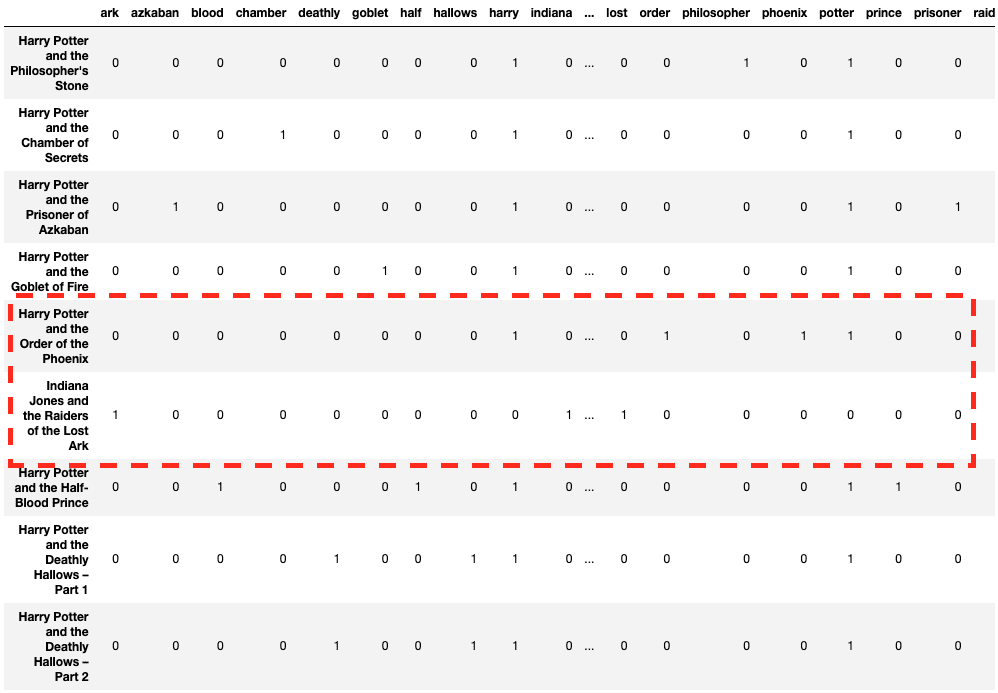
max_df
Phrases like “Harry” and “Potter” aren’t “cease phrases” however are fairly widespread and add little data to the Rely Matrix. Therefore, you may add max_df argument to stem repetitive phrases as options.
count_vector = CountVectorizer(lowercase = True, max_df = 0.2) count_vektor = count_vector.fit_transform(textual content) count_vektor = count_vektor.toarray() df = pd.DataFrame(information = count_vektor, columns = count_vector.get_feature_names()) df.index = textual content df
Under output demonstrates that cease phrases in addition to “harry” and “potter” are faraway from columns:
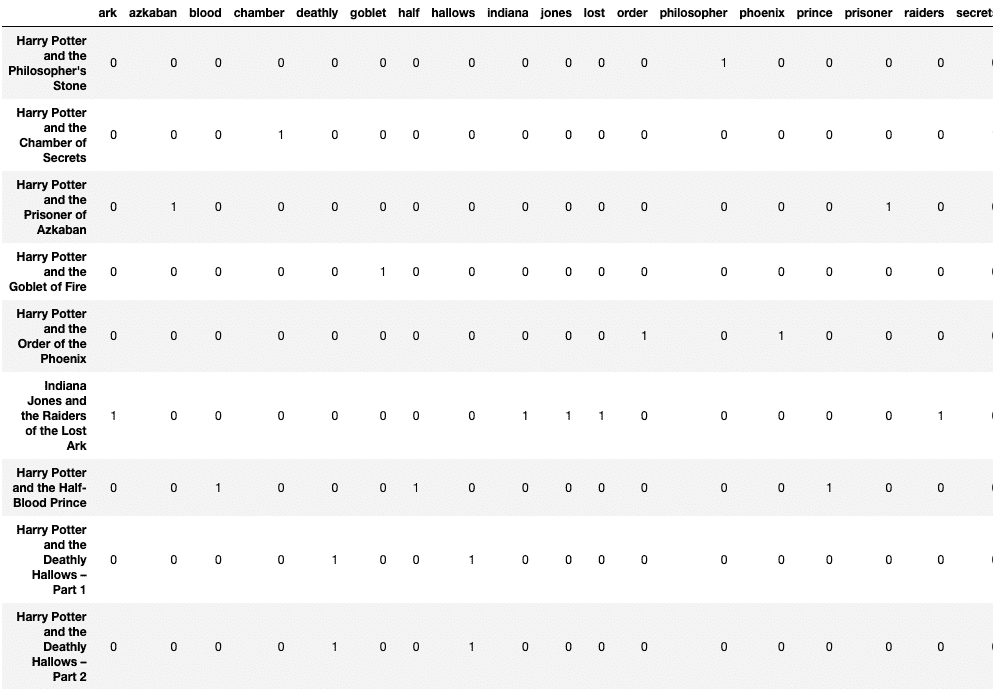
min_df
It’s precisely reverse to max_df and signifies the least variety of paperwork (or proportion and proportion) that ought to have the actual function.
count_vector = CountVectorizer(lowercase = True, min_df = 2) count_vektor = count_vector.fit_transform(textual content) count_vektor = count_vektor.toarray() df = pd.DataFrame(information = count_vektor, columns = count_vector.get_feature_names()) df.index = textual content df
Right here the under columns (phrases) are current in a minimum of two paperwork.

max_features
It represents the topmost occurring options/phrases/columns.
count_vector = CountVectorizer(lowercase = True, max_features = 4) count_vektor = count_vector.fit_transform(textual content) count_vektor = count_vektor.toarray() df = pd.DataFrame(information = count_vektor, columns = count_vector.get_feature_names()) df.index = textual content df
Prime 4 generally occurring phrases are chosen under.
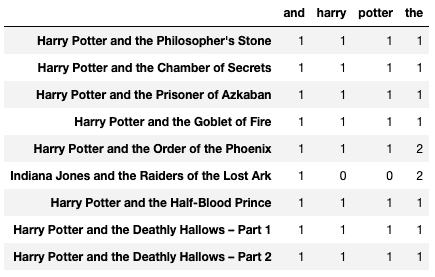
binary
The binary argument replaces all constructive occurrences of phrases by ‘1’ in a doc. It signifies the presence or absence of a phrase or token as a substitute of frequency and is helpful in evaluation like sentiment or product evaluation.
count_vector = CountVectorizer(lowercase = True, binary = True,
max_features = 4)
count_vektor = count_vector.fit_transform(textual content)
count_vektor = count_vektor.toarray()
df = pd.DataFrame(information = count_vektor, columns = count_vector.get_feature_names())
df.index = textual content
df
Upon evaluating with the earlier output, the frequency desk of the column named “the” is capped to ‘1’ within the outcome proven under:

vocabulary_
It returns the place of columns and is used to map algorithm outcomes to interpretable phrases.
count_vector = CountVectorizer(lowercase = True) count_vector.fit_transform(textual content) count_vector.vocabulary_
The output of the above code is proven under.
{
'harry': 10,
'potter': 19,
'and': 0,
'the': 25,
'thinker': 17,
'stone': 24,
'chamber': 4,
'of': 14,
'secrets and techniques': 23,
'prisoner': 21,
'azkaban': 2,
'goblet': 7,
'fireplace': 6,
'order': 15,
'phoenix': 18,
'indiana': 11,
'jones': 12,
'raiders': 22,
'misplaced': 13,
'ark': 1,
'half': 8,
'blood': 3,
'prince': 20,
'deathly': 5,
'hallows': 9,
'half': 16
}
The tutorial mentioned the significance of pre-processing textual content aka vectorizing it as an enter into machine studying algorithms. The submit additionally demonstrated sklearn’s implementation of CountVectorizer with numerous enter parameters on a small set of paperwork.
Vidhi Chugh is an award-winning AI/ML innovation chief and an AI Ethicist. She works on the intersection of knowledge science, product, and analysis to ship enterprise worth and insights. She is an advocate for data-centric science and a number one skilled in information governance with a imaginative and prescient to construct reliable AI options.
[ad_2]
Source link