

[ad_1]
Mesh representations of 3D sceneries are important to many functions, from growing AR/VR property to laptop graphics. Nonetheless, making these 3D property remains to be laborious and calls for quite a lot of ability. Current efforts have utilized generative fashions, comparable to diffusion fashions, to successfully produce high-quality footage from a textual content within the 2D realm. These methods efficiently contribute to the democratization of content material manufacturing by significantly reducing the obstacles to producing footage that embrace a consumer’s chosen content material. A brand new space of analysis has tried to make use of comparable methods to generate 3D fashions from the textual content. Nonetheless, present strategies have drawbacks and want extra generality of 2D text-to-image fashions.
Coping with the dearth of 3D coaching information is without doubt one of the important difficulties in creating 3D fashions since 3D datasets are a lot smaller than these utilized in many different functions, comparable to 2D picture synthesis. For example, strategies that make use of 3D supervision straight are often restricted to datasets of fundamental kinds, like ShapeNet. Current methods overcome these information constraints by formalizing 3D creation as an iterative optimization drawback within the image area, enhancing the expressive potential of 2D text-to-image fashions into 3D. The capability to supply arbitrary (neural) kinds from textual content is demonstrated by their potential to assemble 3D objects saved in a radiance area illustration. Sadly, increasing on these methods to supply 3D construction and texture at room dimension will be difficult.
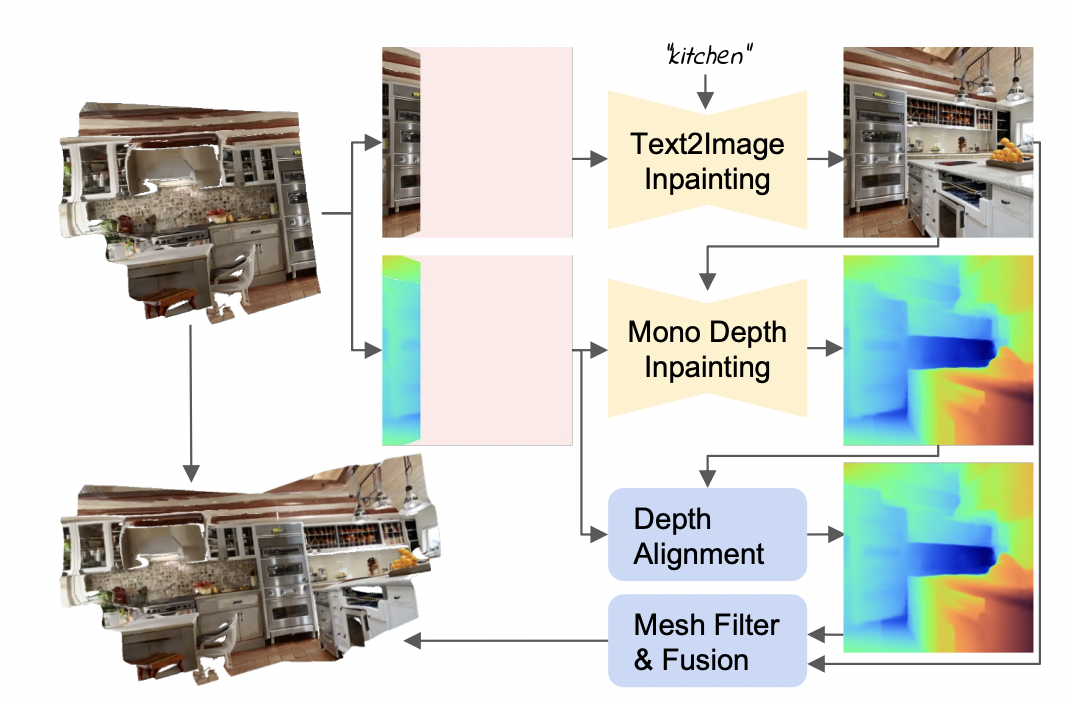
Ensuring that the output is dense and cohesive throughout outward-facing viewpoints and that these views embrace all needed options, comparable to partitions, flooring, and furnishings, is troublesome when creating monumental scenes. A mesh stays a most well-liked illustration for a number of end-user actions, together with rendering on reasonably priced expertise. Researchers from TU Munich and College of Michigan counsel a method that extracts scene-scale 3D meshes from commercially accessible 2D text-to-image fashions to resolve these drawbacks. Their approach employs inpainting and monocular depth notion to create a scene iteratively. Utilizing a depth estimate approach, they make the primary mesh by creating an image from textual content and again projecting it into three dimensions. The mannequin is then repeatedly rendered from recent angles.
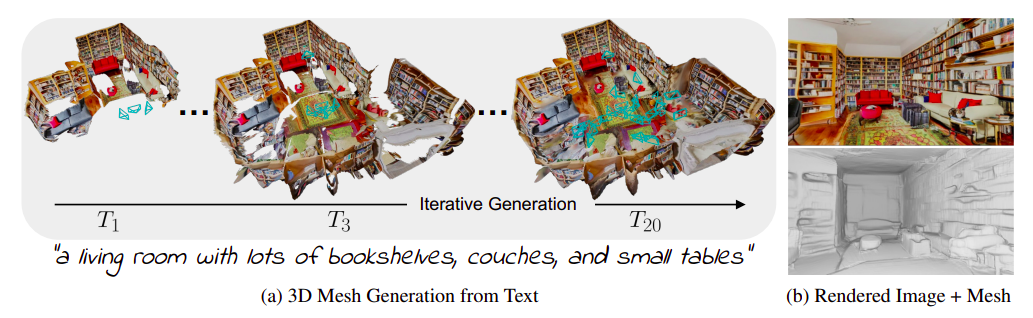
For every, they inpaint any gaps within the displayed footage earlier than fusing the created content material into the mesh (Fig. 1a). Two key design components for his or her iterative technology strategy are how they choose the views and the way they combine the created scene materials with the present geometry. They initially select views from predetermined trajectories that can cowl a good portion of the scene materials, they usually then choose viewpoints adaptively to fill in any gaps. To supply seamless transitions when combining generated content material with the mesh, they align the 2 depth maps and take away any areas of the mannequin with distorted textures.
Mixed, these selections present sizable, scene-scale 3D fashions (Fig. 1b) that may depict a wide range of rooms and have interesting supplies and uniform geometry. So, their contributions are as follows:
• A way that makes use of 2D text-to-image fashions and monocular depth estimation to carry frames into 3D in iterative scene creation.
• A way that creates 3D meshes of room-scale inside scenes with lovely textures and geometry from any textual content enter. They will produce seamless, undistorted geometry and textures utilizing their urged depth alignment and mesh fusion strategies.
• A two-stage personalized perspective choice that samples digicam poses from perfect angles to first lay out the furnishings and structure of the realm after which fill in any gaps to offer a watertight mesh.
Try the Paper, Project, and Github. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t neglect to hitch our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at present pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is obsessed with constructing options round it. He loves to attach with folks and collaborate on attention-grabbing initiatives.
[ad_2]
Source link
