

[ad_1]
Picture by Creator
Deep studying is a sort of intelligence developed to imitate the methods and neurons within the human mind, which play a necessary function within the human pondering course of.
This know-how makes use of deep neural networks, that are composed of layers of synthetic neurons that may analyze and course of huge quantities of information, enabling them to be taught and enhance over time.
We, people, depend on our 5 senses to interpret the world round us. We use our senses of sight, listening to, contact, style, and odor to assemble details about our surroundings and make sense of it.
In an identical vein, multimodal studying is an thrilling new subject of AI that seeks to duplicate this potential by combining info from a number of fashions. By integrating info from various sources equivalent to textual content, picture, audio, and video, multimodal fashions can construct a richer and extra full understanding of the underlying information, unlock new insights, and allow a variety of purposes.
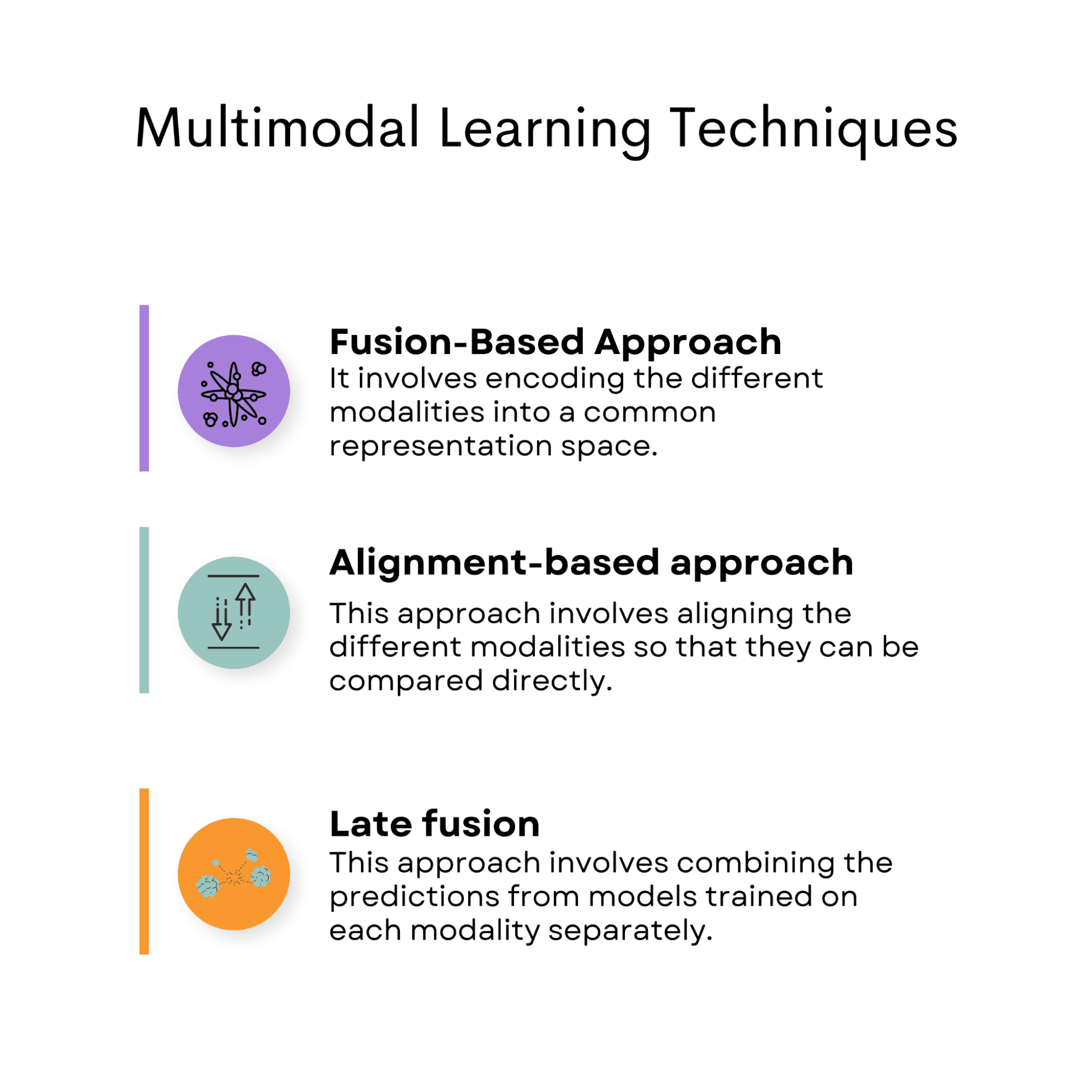
The methods utilized in multimodal studying embody fusion-based approaches, alignments-based approaches, and late fusion.
On this article, we’ll discover the basics of multimodal studying, together with the totally different methods used to fuse info from various sources, in addition to its many thrilling purposes, from speech recognition to autonomous vehicles and past.
Picture by Creator
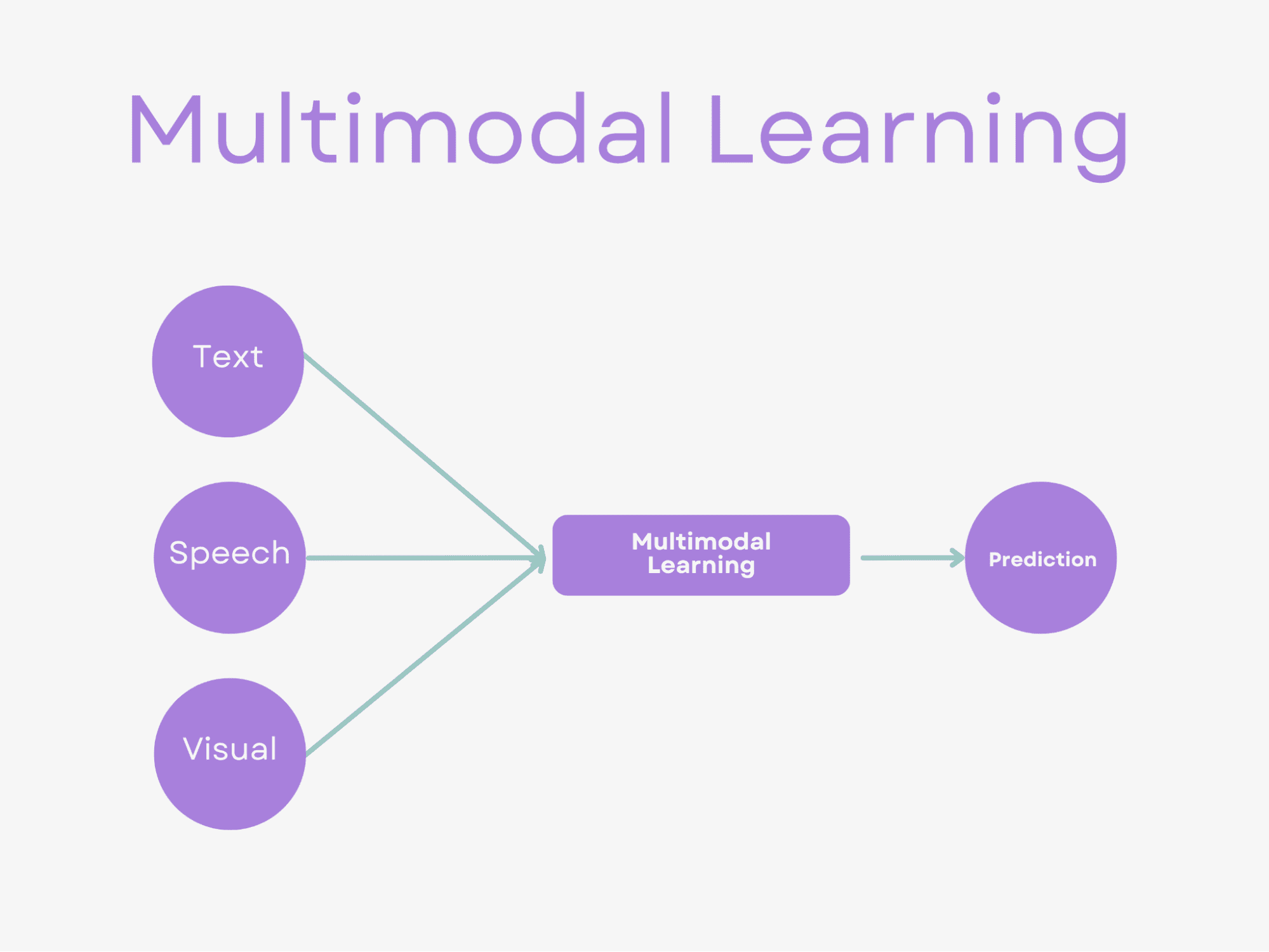
Multimodal studying is a subfield of synthetic intelligence that seeks to successfully course of and analyze information from a number of modalities.
In easy phrases, this implies combining info from totally different sources equivalent to textual content, picture, audio, and video to construct a extra full and correct understanding of the underlying information.
The idea of multimodal studying has discovered purposes in a variety of topics, together with speech recognition, autonomous automobile, and emotion recognition. We’ll speak about them within the following sections.
The multimodal studying methods allow fashions to course of and analyze information from a number of modalities successfully, offering a extra full and correct understanding of the underlying information.
Within the subsequent part, we’ll point out these methods, however earlier than doing that, let’s speak about combining fashions.
These two ideas would possibly look alike, however you’ll quickly uncover they aren’t.
Combining fashions is a method in machine studying that includes utilizing a number of fashions to enhance the efficiency of a single mannequin.
The thought behind combining fashions is that one mannequin’s strengths can compensate for one more’s weak point, leading to a extra correct and strong prediction. Ensemble fashions, stacking, and bagging are methods utilized in combining fashions.

Picture by Creator
Ensemble fashions

Picture by Creator
Ensemble fashions contain combining the outputs of a number of base fashions to supply a greater general mannequin.
One instance of an ensemble mannequin is random forests. Random forests are a call tree algorithm that mixes a number of choice timber to enhance the mannequin’s accuracy. Every choice tree is educated on a unique subset of the info, and the ultimate prediction is made by averaging the predictions of all of the timber.
You’ll be able to see find out how to use the random forests algorithm within the scikit-learn library here.
Stacking

Picture by Creator
Stacking includes utilizing the outputs of a number of fashions as inputs to a different mannequin.
One real-life instance of stacking is in pure language processing, the place it may be utilized to sentiment evaluation.
For example, the Stanford Sentiment Treebank dataset accommodates film evaluations with sentiment labels starting from very detrimental to very optimistic. On this case, a number of fashions equivalent to random forest, Support Vector Machines (SVM), and Naive Bayes will be educated to foretell the sentiment of the evaluations.
The predictions of those fashions can then be mixed utilizing a meta-model equivalent to logistic regression or neural community, which is educated on the outputs of the bottom fashions to make the ultimate prediction.
Stacking can enhance the accuracy of sentiment prediction and make sentiment evaluation extra strong.
Bagging

Picture by Creator
Bagging is one other approach of making ensembles, the place a number of base fashions are educated on totally different subsets of information, and their predictions are averaged to make a closing choice.
One instance of bagging is the bootstrap aggregating methodology, the place a number of fashions are educated on totally different subsets of the coaching information. The ultimate prediction is made by averaging the predictions of all of the fashions.
An instance of bagging in actual life is in finance. The S&P 500 dataset accommodates historic information on the inventory costs of the five hundred largest publicly traded firms in the USA between 2012 and 2018.
Bagging can be utilized on this dataset by coaching a number of fashions in scikit-learn, equivalent to random forests and gradient boosting, to foretell the businesses’ inventory costs.
Every mannequin is educated on a unique subset of the coaching information, and their predictions are averaged to make the ultimate prediction. The usage of bagging can enhance the accuracy of the inventory worth prediction and make the monetary evaluation extra strong.
In combining fashions, the fashions are educated independently, and the ultimate prediction is made by combining the outputs of those fashions utilizing methods equivalent to ensemble fashions, stacking, or bagging.
Combining fashions is especially helpful when the person fashions have complementary strengths and weaknesses, as the mix can result in a extra correct and strong prediction.
In multimodal studying, the objective is to mix info from totally different modalities to carry out a prediction activity. This could contain utilizing methods such because the fusion-based strategy, alignment-based strategy, or late fusion to create a high-dimensional illustration that captures the semantic info of the info from every modality.
Multimodal studying is especially helpful when totally different modalities present complementary info that may enhance the accuracy of the prediction.
The principle distinction between combining fashions and multimodal studying is that combining fashions contain utilizing a number of fashions to enhance the efficiency of a single mannequin. In distinction, multimodal studying includes studying from and mixing info from a number of modalities equivalent to picture, textual content, and audio to carry out a prediction check.
Now, let’s have a look at multimodal studying methods.
Picture by Creator
Fusion-Primarily based Method
The fusion-based strategy includes encoding the totally different modalities into a standard illustration area, the place the representations are fused to create a single modality-invariant illustration that captures the semantic info from all modalities.
This strategy will be additional divided into early fusion and mid-fusion methods, relying on when the fusion happens.
Textual content Captioning
A typical instance of a fusion-based strategy is a picture and textual content captioning.
It’s the fusion-based strategy as a result of the picture’s visible options and the textual content’s semantic info are encoded into a standard illustration area after which fused to generate a single modality-invariant illustration that captures the semantic info from each modalities.
Particularly, the visible options of the picture are extracted utilizing a convolutional neural community (CNN), and the semantic info of the textual content is captured utilizing a recurrent neural community (RNN).
These two modalities are then encoded into a standard illustration area. The visible and textual options are fused utilizing concatenation or element-wise multiplication methods to create a single modality-invariant illustration.
This closing illustration can then be used to generate a caption for the picture.
One open-source dataset that can be utilized to carry out picture and textual content captioning is the Flickr30k dataset, which accommodates 31,000 pictures together with 5 captions per picture. This dataset accommodates pictures of varied on a regular basis scenes, with every picture annotated by a number of individuals to offer various captions.

Supply: https://paperswithcode.com/dataset/flickr30k-cna
The Flickr30k dataset can be utilized to use the fusion-based strategy for picture and textual content captioning by extracting visible options from pre-trained CNNs and utilizing methods equivalent to phrase embeddings or bag-of-words representations for textual options. The ensuing fused illustration can be utilized to generate extra correct and informative captions.
Alignment-Primarily based Method
This strategy includes aligning the totally different modalities in order that they are often in contrast instantly.
The objective is to create modality-invariant representations that may be in contrast throughout modalities. This strategy is advantageous when the modalities share a direct relationship, equivalent to in audio-visual speech recognition.
Signal Language Recognition

Picture by Creator
One instance of an alignment-based strategy is within the activity of signal language recognition.
This use includes the alignment-based strategy as a result of it requires the mannequin to align the temporal info of each visible (video frames) and audio (audio waveform) modalities.
The duty is for the mannequin to acknowledge signal language gestures and translate them into textual content. The gestures are captured utilizing a video digital camera, and the corresponding audio and the 2 modalities should be aligned to acknowledge the gestures precisely. This includes figuring out the temporal alignment between the video frames and the audio waveform to acknowledge the gestures and the corresponding spoken phrases.
One open-source dataset for signal language recognition is the RWTH-PHOENIX-Weather 2014T dataset which accommodates video recordings of German Signal Language (DGS) from numerous signers. The dataset consists of each visible and audio modalities, making it appropriate for multimodal studying duties that require alignment-based approaches.
Late Fusion
This strategy includes combining the predictions from fashions educated on every modality individually. The person predictions are then mixed to create a closing prediction. This strategy is especially helpful when the modalities should not instantly associated, or the person modalities present complementary info.
Emotion Recognition

Picture by Creator
An actual-life instance of late fusion is emotion recognition in music. On this activity, the mannequin should acknowledge the emotional content material of a chunk of music utilizing each the audio options and the lyrics.
The late fusion strategy is utilized on this instance as a result of it combines the predictions from fashions educated on separate modalities (audio options and lyrics) to create a closing prediction.
The person fashions are educated individually on every modality, and the predictions are mixed at a later stage.Subsequently, late fusion.
The audio options will be extracted utilizing methods equivalent to Mel-frequency cepstral coefficients (MFCCs), whereas the lyrics will be encoded utilizing methods equivalent to bag-of-words or phrase embeddings. Fashions will be educated individually on every modality, and the predictions will be mixed utilizing late fusion to generate a closing prediction.
The DEAM dataset was designed to help analysis on music emotion recognition and evaluation, and it consists of each audio options and lyrics for a set of over 2,000 songs. The audio options embody numerous descriptors equivalent to MFCCs, spectral distinction, and rhythm options, whereas the lyrics are represented utilizing bag-of-words and phrase embedding methods.
The late fusion strategy will be utilized to the DEAM dataset by combining the predictions from separate fashions educated on every modality (audio and lyrics).

Supply: DEAM Dataset – Emotional Analysis in Music
For instance, you possibly can prepare a separate machine studying mannequin to foretell the emotional content material of every music utilizing audio options, equivalent to MFCCs and spectral distinction.
One other mannequin will be educated to foretell the emotional content material of every music utilizing the lyrics, represented utilizing methods equivalent to bag-of-words or phrase embeddings.
After coaching the person fashions, the predictions from every mannequin will be mixed utilizing the late fusion strategy to generate a closing prediction.
Picture by Creator
Illustration
Multimodal information can come in several modalities, equivalent to textual content and audio. Combining them in a approach that preserves their particular person traits whereas nonetheless capturing their relationships will be difficult.
This could result in points such because the mannequin failing to generalize effectively, being biased in direction of one modality, or not successfully capturing the joint info.
To unravel illustration issues in multimodal studying, a number of methods will be employed:
Joint illustration: As talked about earlier, this strategy includes encoding each modalities right into a shared high-dimensional area. Strategies like deep learning-based fusion strategies can be utilized to be taught optimum joint representations.
Coordinated illustration: As a substitute of fusing the modalities instantly, this strategy maintains separate encodings for every modality however ensures that their representations are associated and convey the identical that means. Alignment or consideration mechanisms can be utilized to realize this coordination.
Picture-Caption Pairs
The MS COCO dataset is broadly utilized in laptop imaginative and prescient and pure language processing analysis, containing many pictures with objects in numerous contexts, together with a number of textual captions describing the content material of the photographs.
When working with the MS COCO dataset, two predominant methods for dealing with illustration challenges are joint illustration and coordinated illustration.
Joint illustration: By combining the data from each modalities, the mannequin can perceive their mixed that means. For example, you need to use a deep studying mannequin with layers designed to course of and merge options from picture and textual content information. This leads to a joint illustration that captures the connection between the picture and caption.
Coordinated illustration: On this strategy, the picture and caption are encoded individually, however their representations are associated and convey the identical that means. As a substitute of instantly fusing the modalities, the mannequin maintains separate encodings for every modality whereas making certain they’re meaningfully related.
Each joint and coordinated illustration methods will be employed when working with the MS COCO dataset to successfully deal with the challenges of multimodal studying and create fashions that may course of and perceive the relationships between visible and textual info.
Fusion
Fusion is a method utilized in multimodal studying to mix info from totally different information modalities, equivalent to textual content, pictures, and audio, to create a extra complete understanding of a specific state of affairs or context. The fusion course of helps fashions make higher predictions and selections primarily based on the mixed info as a substitute of counting on a single modality.
One problem in multimodal studying is figuring out one of the simplest ways to fuse the totally different modalities. Completely different fusion methods could also be more practical than others for particular duties or conditions, and discovering the best one will be troublesome.
Film Score

Picture by Creator
An actual-life instance of fusion in multimodal studying is a film suggestion system. On this case, the system would possibly use textual content information (film descriptions, evaluations, or consumer profiles), audio information (soundtracks, dialogue), and visible information (film posters, video clips) to generate customized suggestions for customers.
The fusion course of combines these totally different sources of data to create a extra correct and significant understanding of the consumer’s preferences and pursuits, main to raised film strategies.
One real-life dataset appropriate for growing a film suggestion system with fusion is the MovieLens dataset. MovieLens is a set of film rankings and metadata, together with user-generated tags, collected by the GroupLens Analysis mission on the College of Minnesota. The dataset accommodates details about motion pictures, equivalent to titles, genres, consumer rankings, and consumer profiles.
To create a multimodal film suggestion system utilizing the MovieLens dataset, you may mix the textual info (film titles, genres, and tags) with further visible information (film posters) and audio information (soundtracks, dialogue). You’ll be able to get hold of film posters and audio information from different sources, equivalent to IMDB or TMDB.
How Fusion May Be a Problem?
Fusion could be difficult when making use of multimodal studying to this dataset as a result of it’s worthwhile to decide the simplest solution to mix the totally different modalities.
For instance, it’s worthwhile to discover the best stability between the significance of textual information (genres, tags), visible information (posters), and audio information (soundtracks, dialogue) for the advice activity.
Moreover, some motion pictures might have lacking or incomplete information, equivalent to missing posters or audio samples.
On this case, the advice system must be strong sufficient to deal with lacking information and nonetheless present correct suggestions primarily based on the accessible info.
In abstract, utilizing the MovieLens dataset, together with further visible and audio information, you possibly can develop a multimodal film suggestion system that leverages fusion methods.
Nevertheless, challenges might come up when figuring out the simplest fusion methodology and dealing with lacking or incomplete information.
Alignment
Alignment is a vital activity in purposes equivalent to audio-visual speech recognition. On this activity, audio and visible modalities should be aligned to acknowledge speech precisely.
Researchers have used alignment strategies such because the hidden Markov mannequin and dynamic time warping to realize this synchronization.
For instance, the hidden Markov mannequin can be utilized to mannequin the connection between the audio and visible modalities and to estimate the alignment between the audio waveform and the video frames. Dynamic time warping can be utilized to align the info sequences by stretching or compressing them in time in order that they match extra intently.
Audio-Visible Speech Recognition

Picture by Creator
By aligning the audio and visible information within the GRID Corpus dataset, researchers can create coordinated representations that seize the relationships between the modalities after which use these representations to acknowledge speech precisely utilizing each modalities.
The GRID Corpus dataset accommodates audio-visual recordings of audio system producing sentences in English. Every recording consists of the audio waveform and the video of the speaker’s face, which captures the motion of the lips and different facial options. The dataset is broadly used for analysis in audio-visual speech recognition, the place the objective is to acknowledge speech precisely utilizing audio and visible modalities.
Translation
The interpretation is a standard multimodal problem the place totally different modalities of information, equivalent to textual content and pictures, should be aligned to create a coherent illustration. One instance of such a problem is the duty of picture captioning, the place a picture must be described in pure language.
On this activity, a mannequin wants to have the ability to acknowledge not solely the objects and context in a picture but in addition generate a pure language description that precisely conveys the that means of the picture.
This requires aligning the visible and textual modalities to create coordinated representations that seize the relationships between them.
Dall-E
An oil portray of pandas meditating in Tibet

Reference: Dall-E
One latest instance of a mannequin that may carry out multimodal translation is DALL-E2. DALL-E2 is a neural community mannequin developed by OpenAI that may generate high-quality pictures from textual descriptions. It will probably additionally generate textual descriptions from pictures, successfully translating between the visible and textual modalities.
DALL-E2 achieves this by studying a joint illustration area that captures the relationships between the visible and textual modalities.
The mannequin is educated on a big dataset of the image-caption pairs and learns to affiliate pictures with their corresponding captions. It will probably then generate pictures from textual descriptions by sampling from the realized illustration area and generate textual descriptions from pictures by decoding the realized illustration.
General, multimodal translation is a big problem that requires aligning totally different modalities of information to create coordinated representations. Fashions like DALL-E2 can carry out this activity by studying joint illustration areas that seize the relationships between the visible and textual modalities and will be utilized to duties equivalent to picture captioning and visible query answering.
Co-learning
Multimodal co-learning goals to switch data realized by way of a number of modalities to duties involving one other.
Co-learning is very vital in low-resource goal duties, fully/partly lacking or noisy modalities.
Nevertheless, discovering efficient strategies to switch data from one modality to a different whereas retaining the semantic that means is a big problem in multimodal studying.
In medical analysis, totally different medical imaging modalities, equivalent to CT scans and MRI scans, present complementary info for a analysis. Multimodal co-learning can be utilized to mix these modalities to enhance the accuracy of the analysis.
Multimodal Tumor Segmentation
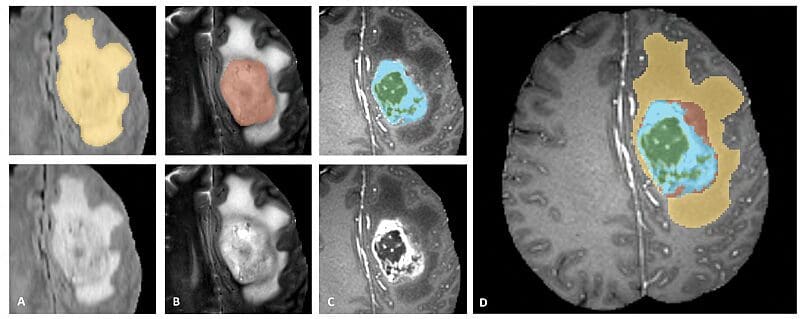
Supply: https://www.med.upenn.edu/sbia/brats2018.html
For example, within the case of mind tumors, MRI scans present high-resolution pictures of soppy tissues, whereas CT scans present detailed pictures of the bone construction. Combining these modalities can present an entire image of the affected person’s situation and inform remedy selections.
A dataset that features MRI and CT scans of mind tumors to be used in multimodal co-learning is the multimodal Brain Tumor Segmentation (BraTS) dataset. This dataset consists of MRI and CT scans of mind tumors and annotations for segmentation of the tumor areas.
To implement co-learning with the MRI and CT scans of mind tumors, we have to develop an strategy that mixes the data from each modalities in a approach that improves the accuracy of the analysis. One doable strategy is to make use of a multimodal deep studying mannequin educated on MRI and CT scans.
We’ll point out a number of different purposes of multimodal studying, like speech recognition and autonomous vehicles.
Speech Recognition

Picture by Creator
Multimodal studying can enhance speech recognition accuracy by combining audio and visible information.
For example, a multimodal mannequin can analyze each the audio sign of speech and corresponding lip actions to enhance speech recognition accuracy. By combining audio and visible modalities, multimodal fashions can scale back the consequences of noise and variability in speech indicators, resulting in improved speech recognition efficiency.

Supply: CMU-MOSEI Dataset
One instance of a multimodal dataset that can be utilized for speech recognition is the CMU-MOSEI dataset. This dataset accommodates 23,500 sentences pronounced by 1,000 Youtube audio system and consists of each audio and visible information of the audio system.
The dataset can be utilized to develop multimodal fashions for emotion recognition, sentiment evaluation, and speaker identification.
By combining the audio sign of speech with the visible traits of the speaker, multimodal fashions can enhance the accuracy of speech recognition and different associated duties.
Autonomous Automobile
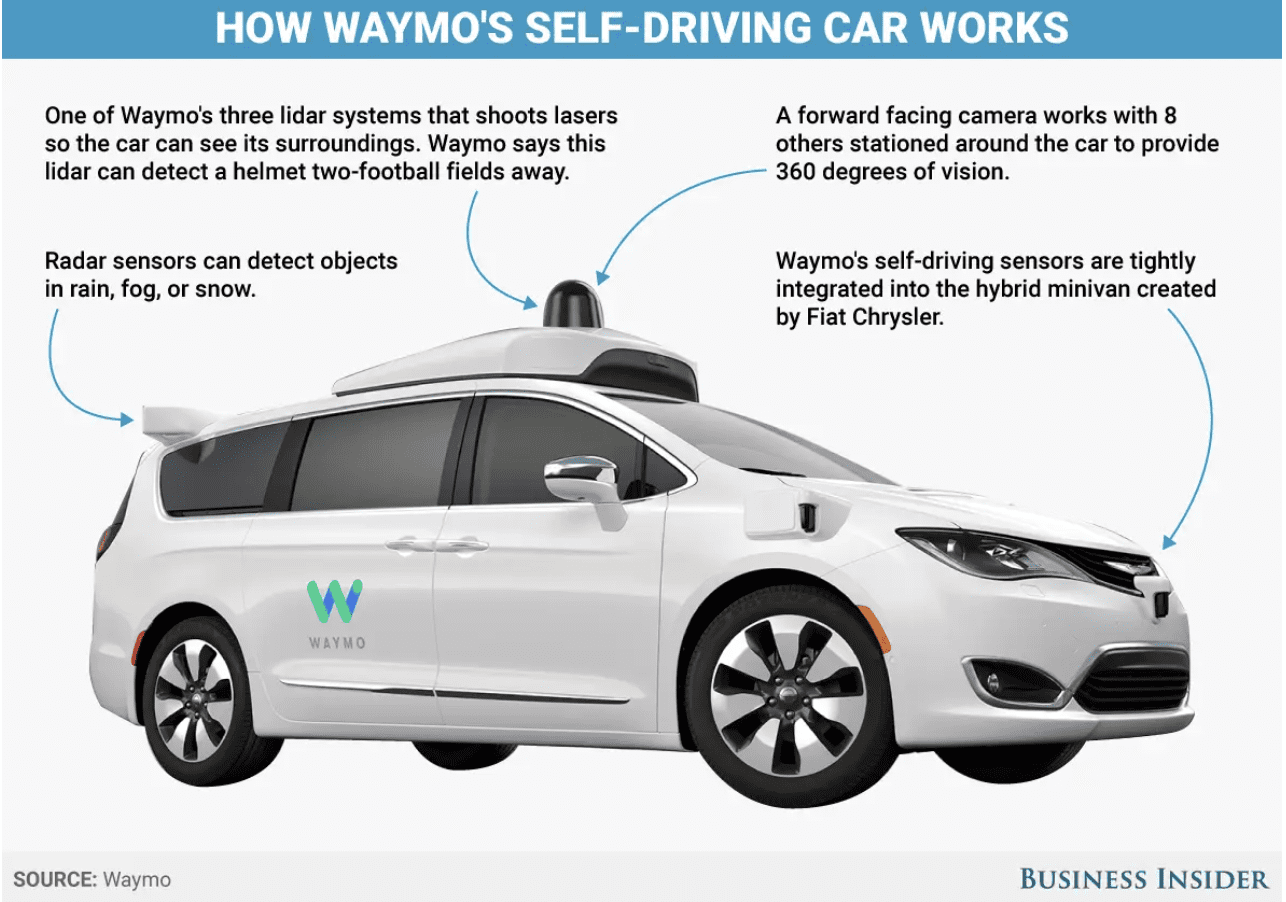
Supply: Waymo; Business Insider
Multimodal studying can be utilized to boost the capabilities of robots by integrating info from a number of sensors.
For example, it’s important in growing self-driving vehicles, which depend on info from a number of sensors equivalent to cameras, lidar, and radar to navigate and make selections.
Multimodal studying may help to combine info from these sensors, permitting the automobile to understand and react to its surroundings extra precisely and effectively.
One instance of a dataset for self-driving vehicles is the Waymo Open Dataset, which incorporates high-resolution sensor information from Waymo’s self-driving vehicles, together with labels for objects equivalent to autos, pedestrians, and cyclists. Waymo is Google’s self-driving automobile firm.
The dataset can be utilized to develop and consider multimodal fashions for numerous duties associated to self-driving vehicles, equivalent to object detection, monitoring, and predictions.
Voice Recording Evaluation

Picture by Creator
The Voice Recordings Analysis project got here up through the interviews for the info science positions at Sandvik. It is a superb instance of a multimodal studying software, because it seeks to foretell an individual’s gender primarily based on vocal options derived from audio information.
On this state of affairs, the issue includes analyzing and processing info from two distinct modalities: audio indicators and textual options. These modalities contribute useful info that may improve the accuracy and effectiveness of the predictive mannequin.
Increasing on the multimodal nature of this mission:
Audio Alerts

Picture by Creator
The first information supply on this mission is the audio recordings of the English-speaking female and male voices. These audio indicators comprise wealthy and sophisticated details about the speaker’s vocal traits. By extracting related options from these audio indicators, equivalent to pitch, frequency, and spectral entropy, the mannequin can determine patterns and developments that relate to gender-specific vocal properties.
Textual Options

Picture by Creator
Accompanying every audio recording is a textual content file that gives essential details about the pattern, such because the speaker’s gender, the language spoken, and the phrase uttered by the individual. This textual content file not solely presents the bottom reality (gender labels) for coaching and evaluating the machine studying fashions however will also be used to create further options together with the audio information. By leveraging the data within the textual content file, the mannequin can higher perceive the context and content material of every audio pattern, doubtlessly bettering its general predictive efficiency.
So, the Voice Recordings Evaluation mission exemplifies a multimodal studying software by leveraging information from a number of modalities, audio indicators, and textual options to foretell an individual’s gender utilizing extracted vocal traits.
This strategy highlights the significance of contemplating totally different information sorts when growing machine studying fashions, as it may possibly assist uncover hidden patterns and relationships that might not be obvious when analyzing every modality in isolation.
In abstract, multimodal studying has turn out to be a potent instrument for integrating various information to boost the ability of the precision of machine learning algorithms. Combining totally different information sorts, together with textual content, audio, and visible info, can yield extra strong and correct predictions. That is significantly true in speech recognition, textual content and picture fusion, and the autonomous automobile trade.
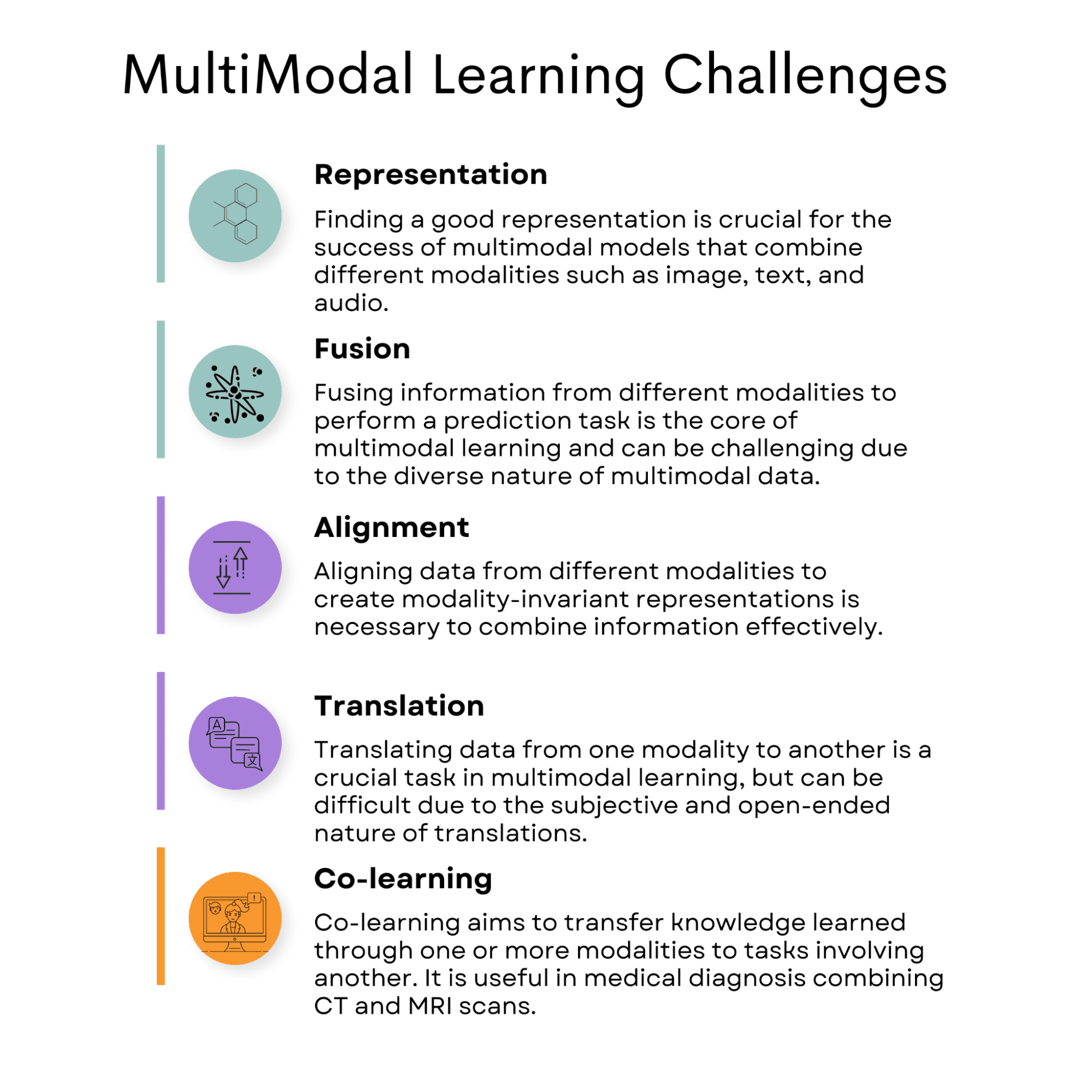
But, multimodal studying does include a number of challenges, equivalent to these associated to illustration, fusion, alignment, translation, and co-learning. This necessitates cautious consideration and a spotlight.
However, as machine studying methods and computing energy proceed to evolve, we will anticipate the emergence of much more superior multimodal within the years to come back.
Nate Rosidi is a knowledge scientist and in product technique. He is additionally an adjunct professor educating analytics, and is the founding father of StrataScratch, a platform serving to information scientists put together for his or her interviews with actual interview questions from prime firms. Join with him on Twitter: StrataScratch or LinkedIn.
[ad_2]
Source link
