

[ad_1]
Diffusion fashions are quickly advancing and making lives simpler. From Pure Language Processing and Pure Language Understanding to Pc Imaginative and prescient, diffusion fashions have proven promising leads to virtually each area. These fashions are a current growth in generative AI and are a sort of deep generative mannequin that can be utilized to generate lifelike samples from advanced distributions.
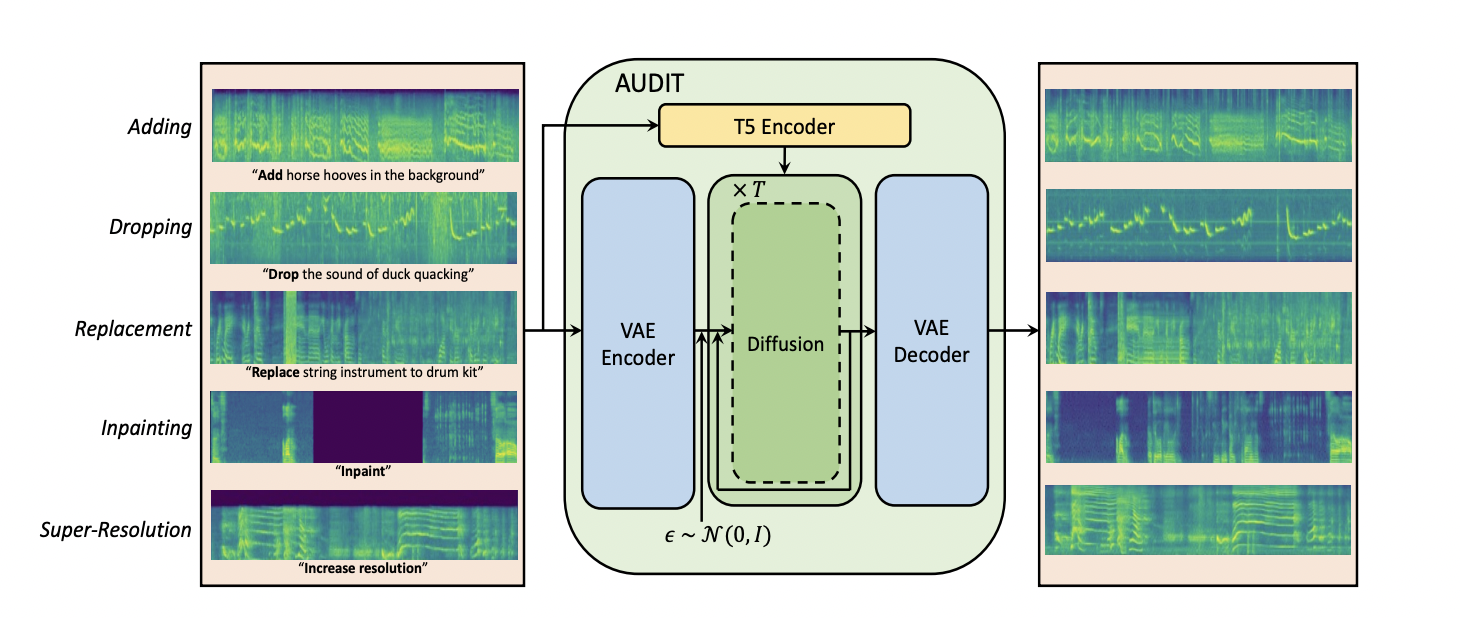
A brand new diffusion mannequin has been just lately launched by researchers that may simply edit audio clips. Referred to as AUDIT, this latent diffusion mannequin is an instruction-guided audio enhancing mannequin. Audio enhancing primarily entails altering an enter audio sign to supply an edited audio output. This consists of duties reminiscent of including background sound results, changing background music, repairing incomplete audio, or enhancing low-quality audio. AUDIT takes each the enter audio and human directions as situations and generates the edited audio output.
The researchers have used triplet information to coach the audio enhancing diffusion mannequin in a supervised method. The triplet information used is instruction, enter audio, and output audio. The enter audio has been instantly used as a conditional enter to make sure consistency within the audio segments with out enhancing. The enhancing directions have additionally been instantly used as textual content steering to make the mannequin extra versatile and appropriate for real-world eventualities.
The workforce of researchers behind AUDIT has summarized their contributions as follows –
- AUDIT is the primary growth through which a diffusion mannequin has been educated for audio enhancing, which takes human textual content directions because the situation.
- A knowledge building framework has been designed to coach AUDIT in a supervised method.
- AUDIT is able to maximizing the preservation of audio segments that don’t require enhancing.
- AUDIT works nicely with easy directions as textual content steering with out the necessity for an in depth description of the enhancing goal.
- AUDIT has achieved noteworthy leads to each goal and subjective metrics for plenty of audio enhancing duties.
The workforce has shared a number of examples the place AUDIT has carried out significantly and edited audios exactly. These embrace including the sound of automotive honks within the audio, changing the sound of laughter with the sound of a trumpet, eradicating the sound of a girl speaking from the audio of somebody whistling, and so forth. AUDIT carried out extraordinarily nicely in audio enhancing duties and confirmed nice leads to goal and subjective metrics, together with the next duties.
- Including a sound to an audio clip.
- Dropping or eradicating a sound from an audio clip
- Substituting a sound occasion within the enter audio with one other sound.
- Audio inpainting: Finishing a masked phase of audio primarily based on the context or offered textual immediate.
- Tremendous-resolution process with which low-sampled enter audio might be transformed into high-sampled output audio.
In conclusion, AUDIT looks like a promising method for the longer term that may simplify versatile and efficient audio enhancing by following human directions.
Take a look at the Paper and Project. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t overlook to hitch our 18k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
Tanya Malhotra is a closing 12 months undergrad from the College of Petroleum & Vitality Research, Dehradun, pursuing BTech in Pc Science Engineering with a specialization in Synthetic Intelligence and Machine Studying.
She is a Knowledge Science fanatic with good analytical and important considering, together with an ardent curiosity in buying new abilities, main teams, and managing work in an organized method.
[ad_2]
Source link
