

[ad_1]
Picture by Creator
When working with fashions, you must keep in mind that totally different algorithms have totally different studying patterns when taking in knowledge. It’s a type of intuitive studying, to assist the mannequin study the patterns within the given dataset, referred to as coaching the mannequin.
The mannequin will then be examined on the testing dataset, a dataset the mannequin has not seen earlier than. You need to obtain an optimum efficiency degree the place the mannequin can produce correct outputs on each the coaching and testing dataset.
You’ll have additionally heard of the validation set. That is the tactic of splitting your dataset into two: the coaching dataset and the testing dataset. The primary break up of the information can be used to coach the mannequin, while the second break up of the information can be used to check the mannequin.
Nevertheless, the validation set technique comes with drawbacks.
The mannequin may have learnt all of the patterns within the coaching dataset, however it could have missed out on related info within the testing dataset. This has induced the mannequin to be disadvantaged of necessary info that may enhance its total efficiency.
One other downside is that the coaching dataset might face outliers or errors within the knowledge, which the mannequin will study. This turns into a part of the mannequin’s data base and can be utilized when testing within the second section.
So what can we do to enhance this? Resampling.
Resampling is a technique that includes repeatedly drawing samples from the coaching dataset. These samples are then used to refit a particular mannequin to retrieve extra details about the fitted mannequin. The purpose is to collect extra details about a pattern and enhance the accuracy and estimate the uncertainty.
For instance, when you’re taking a look at linear regression suits and need to study the variability. You’ll repeatedly use totally different samples from the coaching knowledge and match a linear regression to every of the samples. This may help you study how the outcomes differ based mostly on the totally different samples, in addition to receive new info.
The numerous benefit of resampling is you could repeatedly draw small samples from the identical inhabitants until your mannequin achieves its optimum efficiency. You’ll save plenty of money and time by with the ability to recycle the identical dataset, and never having to seek out new knowledge.
Beneath-sampling and Oversampling
If you’re working with extremely unbalanced datasets, resampling is a way you should use to assist with it.
- Beneath-sampling is once you take away samples from the bulk class, to supply extra steadiness.
- Over-sampling is once you duplicate random samples from the minority class resulting from inadequate knowledge collected.
Nevertheless, these include drawbacks. Eradicating samples in under-sampling can result in a lack of info. Duplicating random samples from the minority class can result in overfitting.
Two resampling strategies are continuously utilized in knowledge science:
- The Bootstrap Methodology
- Cross-Validation
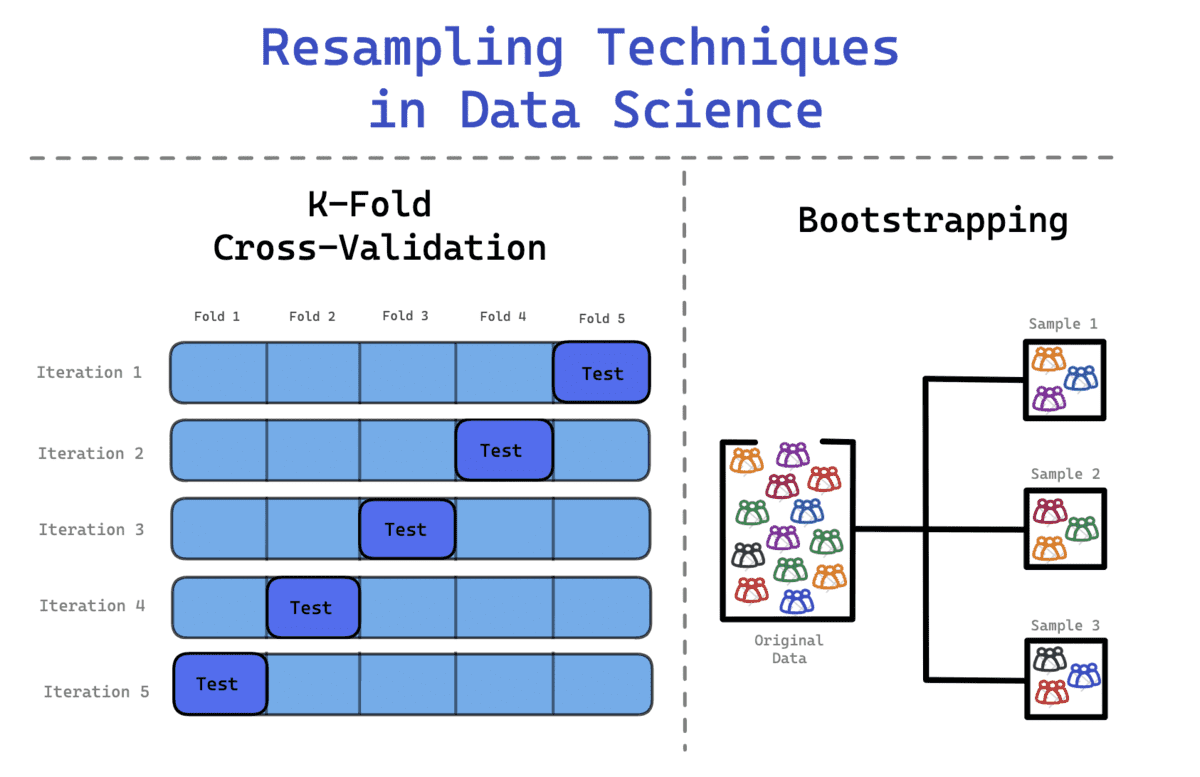
Bootstrap Methodology
You’ll come throughout datasets that don’t observe the standard regular distribution. Due to this fact, the Bootstrap technique could be utilized to look at the hidden info and distribution of the information set.
When utilizing the bootstrapping technique, the samples which are drawn are changed and the information that aren’t included within the samples are used to check the mannequin. It’s a versatile statistical technique that may assist knowledge scientists and machine studying engineers quantify uncertainty.
The method contains
- Repeatedly drawing pattern observations from the dataset
- Changing these samples to make sure the unique knowledge set stays on the identical dimension.
- An commentary can both seem greater than as soon as or by no means.
You’ll have heard of Bagging, the ensemble approach. It’s brief for Bootstrap Aggregation, which mixes bootstrapping and aggregation to kind one ensemble mannequin. It creates a number of units of the unique coaching knowledge, which is then aggregated to conclude a last prediction. Every mannequin learns the earlier mannequin’s errors.
A bonus of Bootstrapping is that they’ve decrease variance compared to the train-test break up technique talked about above.
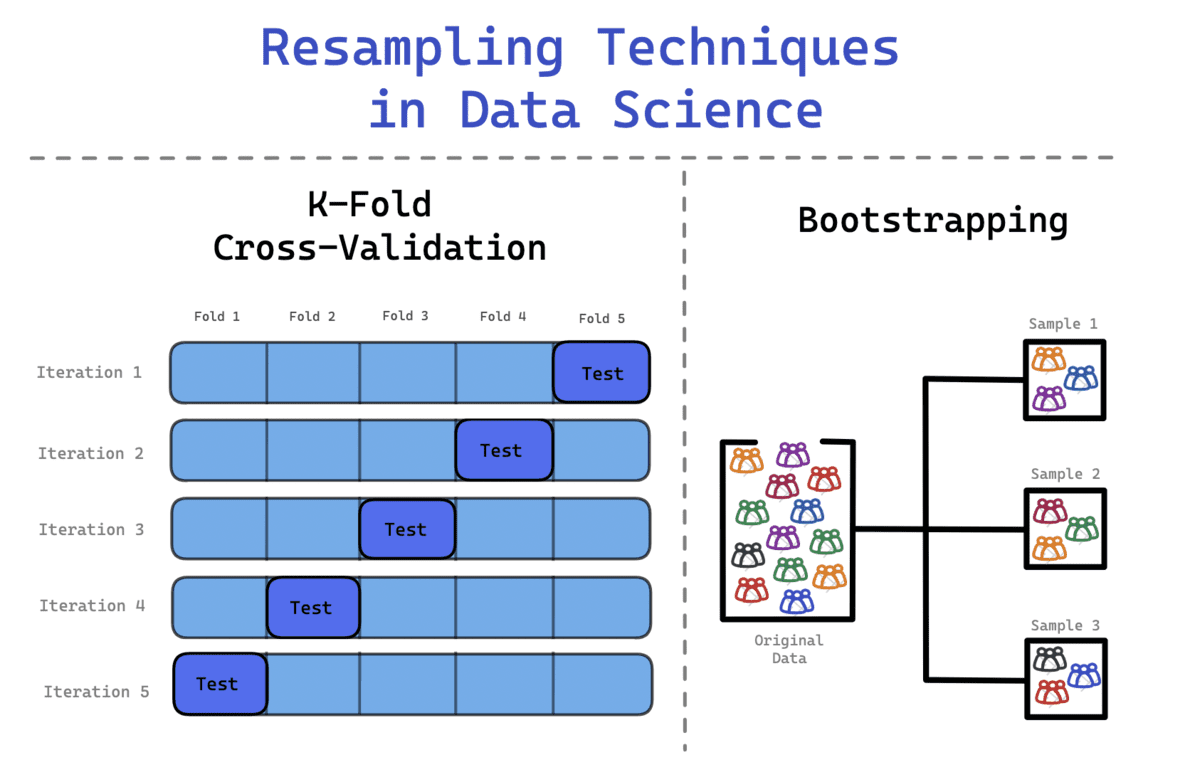
Cross-Validation
Whenever you repeatedly break up the dataset randomly, it might probably result in the pattern ending up in both the coaching or check units. This could sadly have an unbalanced affect in your mannequin from making correct predictions.
With a view to keep away from this, you should use Ok-Fold Cross Validation to separate the information extra successfully. On this course of, the information is split into okay equal units, the place one set is outlined because the check set while the remainder of the units are utilized in coaching the mannequin. The method will proceed until every set has acted because the check set and all of the units have gone by means of the coaching section.
The method contains:
- The information is break up in k-folds. For instance, a dataset is break up into 10 folds – 10 equal units.
- Throughout the first iteration, the mannequin is skilled on (k-1) and examined on the one remaining set. For instance, the mannequin is skilled on (10-1 = 9) and examined on the remaining 1 set.
- This course of is repeated until all of the folds have acted because the remaining 1 set within the testing section.
This permits for a balanced illustration of every pattern, guaranteeing that each one the information has been used to enhance the mannequin’s studying in addition to check the mannequin’s efficiency.
On this article, you’ll have understood what resampling is and how one can pattern your dataset in 3 alternative ways: train-test break up, bootstrap, and cross-validation.
The general purpose for all of those strategies is to assist the mannequin soak up as a lot info as attainable, in an efficient approach. The one approach to make sure that the mannequin has efficiently discovered is to coach the mannequin on a wide range of knowledge factors within the dataset.
Resampling is a crucial ingredient of the predictive modeling section; guaranteeing correct outputs, high-performance fashions, and efficient workflows.
Nisha Arya is a Information Scientist and Freelance Technical Author. She is especially keen on offering Information Science profession recommendation or tutorials and idea based mostly data round Information Science. She additionally needs to discover the alternative ways Synthetic Intelligence is/can profit the longevity of human life. A eager learner, looking for to broaden her tech data and writing abilities, while serving to information others.
[ad_2]
Source link
