

[ad_1]

This text is a part of the Circuits thread, an experimental format accumulating invited brief articles and important commentary delving into the internal workings of neural networks.
Introduction
If we consider interpretability as a sort of “anatomy of neural networks,” a lot of the circuits thread has concerned finding out tiny little veins – trying on the small-scale, at particular person neurons and the way they join. Nonetheless, there are lots of pure questions that the small-scale method doesn’t tackle.
In distinction, probably the most outstanding abstractions in organic anatomy contain larger-scale constructions: particular person organs like the guts, or total organ techniques just like the respiratory system. And so we marvel: is there a “respiratory system” or “coronary heart” or “mind area” of a synthetic neural community? Do neural networks have any emergent constructions that we might research which might be larger-scale than circuits?
This text describes department specialization, one among three bigger “structural phenomena” we’ve been ready observe in neural networks. (The opposite two, equivariance and weight banding, have separate devoted articles.) Department specialization happens when neural community layers are cut up up into branches. The neurons and circuits are likely to self-organize, clumping associated capabilities into every department and forming bigger useful items – a sort of “neural community mind area.” We discover proof that these constructions implicitly exist in neural networks with out branches, and that branches are merely reifying constructions that in any other case exist.
The earliest instance of department specialization that we’re conscious of comes from AlexNet
The primary two layers of AlexNet are cut up into two branches which might’t talk till they rejoin after the second layer. This construction was used to maximise the effectivity of coaching the mannequin on two GPUs, however the authors observed one thing very curious occurred consequently. The neurons within the first layer organized themselves into two teams: black-and-white Gabor filters shaped on one department and low-frequency colour detectors shaped on the opposite department.

1. Department specialization within the first two layers of AlexNet. Krizhevsky et al.
Though the primary layer of AlexNet is the one instance of department specialization we’re conscious of being mentioned within the literature, it appears to be a typical phenomenon. We discover that department specialization occurs in later hidden layers, not simply the primary layer. It happens in each low-level and high-level options. It happens in a variety of fashions, together with locations you may not anticipate it – for instance, residual blocks in resnets can functionally be branches and specialize. Lastly, department specialization seems to floor as a structural phenomenon in plain convolutional nets, even with none explicit construction inflicting it.
Is there a large-scale construction to how neural networks function? How are options and circuits organized throughout the mannequin? Does community structure affect the options and circuits that type? Department specialization hints at an thrilling story associated to all of those questions.
What’s a department?
Many neural community architectures have branches, sequences of layers which quickly don’t have entry to “parallel” data which remains to be handed to later layers.
2. Examples of branches in varied varieties of neural community architectures.
Prior to now, fashions with explicitly-labeled branches had been in style (reminiscent of AlexNet and the Inception household of networks
The implicit branching of residual networks has some necessary nuances. At first look, each layer is a two-way department. However as a result of the branches are mixed collectively by addition, we will really rewrite the mannequin to disclose that the residual blocks could be understood as branches in parallel:
3. Residual blocks as branches in parallel.
We sometimes see residual blocks focus on very deep residual networks (e.g. ResNet-152). One speculation for why is that, in these fashions, the precise depth of a layer doesn’t matter and the branching facet turns into extra necessary than the sequential facet.
One of many conceptual weaknesses of regular branching fashions is that though branches can save parameters, it nonetheless requires quite a lot of parameters to combine values between branches. Nonetheless, if you happen to purchase the department interpretation of residual networks, you possibly can see them as a method to sidestep this: residual networks intermix branches (e.g. block sparse weights) with low-rank connections (projecting all of the blocks into the identical sum after which again up). This looks like a extremely elegant technique to deal with branching. Extra virtually, it means that evaluation of residual networks could be well-served by paying shut consideration to the items within the blocks, and that we would anticipate the residual stream to be unusually polysemantic.
Why does department specialization happen?
Department specialization is outlined by options organizing between branches. In a traditional layer, options are organized randomly: a given characteristic is simply as prone to be any neuron in a layer. However in a branched layer, we regularly see options of a given sort cluster to 1 department. The department has specialised on that sort of characteristic.
How does this occur? Our instinct is that there’s a constructive suggestions loop throughout coaching.
4. Hypothetical constructive suggestions loop of department specialization throughout coaching.
One other means to consider that is that if it’s worthwhile to lower a neural community into items which have restricted means to speak with one another, it is smart to prepare comparable options shut collectively, as a result of they most likely have to share extra data.
Department specialization past the primary layer
To this point, the one concrete instance we’ve proven of department specialization is the primary and second layer of AlexNet. What about later layers? AlexNet additionally splits its later layers into branches, in spite of everything. This appears to be unexplored, since finding out options after the primary layer is far tougher.
Sadly, department specialization within the later layers of AlexNet can be very delicate. As an alternative of 1 general cut up, it’s extra like there’s dozens of small clusters of neurons, every cluster being assigned to a department. It’s onerous to be assured that one isn’t simply seeing patterns in noise.
However different fashions have very clear department specialization in later layers. This tends to occur when a department constitutes solely a really small fraction of a layer, both as a result of there are lots of branches or as a result of one is far smaller than others. In these instances, the department can specialize on a really small subset of the options that exist in a layer and reveal a transparent sample.
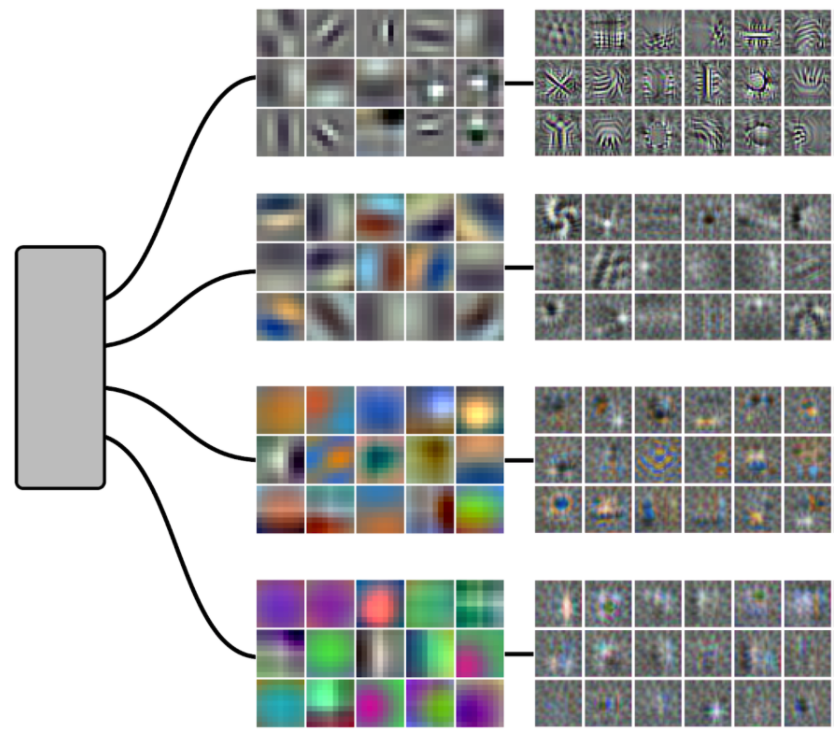
For instance, most of InceptionV1′s layers have a branched construction. The branches have various numbers of items, and ranging convolution sizes. The 5×5 department is the smallest department, and likewise has the biggest convolution dimension. It’s usually very specialised:
5. Examples of department specialization in mixed3a_5x5, mixed3b_5x5, and mixed4a_5x5.
That is exceptionally unlikely to have occurred by likelihood.
For instance, all 9 of the black and white vs. colour detectors in mixed3a are in mixed3a_5x5, regardless of it solely being 32 out of the 256 neurons within the layer. The chance of that occuring by likelihood is lower than 1/108. For a extra excessive instance, all 30 of the curve-related options in mixed3b are in mixed3b_5x5, regardless of it being solely 96 out of the 480 neurons within the layer. The chance of that occuring by likelihood is lower than 1/1020.
It’s value noting one confounding issue which could be influencing the specialization. The 5×5 branches are the smallest branches, but in addition have bigger convolutions (5×5 as an alternative of 3×3 or 1×1) than their neighbors.mixed3a_5x5 department or colour within the mixed3b_5x5 department?
Why is department specialization constant?
Maybe probably the most stunning factor about department specialization is that the identical department specializations appear to happen time and again, throughout totally different architectures and duties.
For instance, the department specialization we noticed in AlexNet – the primary layer specializing right into a black-and-white Gabor department vs. a low-frequency colour department – is a surprisingly strong phenomenon. It happens persistently if you happen to retrain AlexNet. It additionally happens if you happen to practice different architectures with the primary few layers cut up into two branches. It even happens if you happen to practice these fashions on different pure picture datasets, like Locations as an alternative of ImageNet. Anecdotally, we additionally appear to see different varieties of department specialization recur. For instance, discovering branches that appear to focus on curve detection appears to be fairly widespread (though InceptionV1′s mixed3b_5x5 is the one one we’ve fastidiously characterised).
So, why do the identical department specializations happen time and again?
One speculation appears very tempting. Discover that most of the identical options that type in regular, non-branched fashions additionally appear to type in branched fashions. For instance, the primary layer of each branched and non-branched fashions comprise Gabor filters and colour options. If the identical options exist, presumably the identical weights exist between them.
May it’s that branching is simply surfacing a construction that already exists? Maybe there’s two totally different subgraphs between the weights of the primary and second conv layer in a traditional mannequin, with comparatively small weights between them, and once you practice a branched mannequin these two subgraphs latch onto the branches.
(This might be directionally just like work discovering modular substructures
To check this, let’s have a look at fashions which have non-branched first and second convolutional layers. Let’s take the weights between them and carry out a singular worth decomposition (SVD) on absolutely the values of the weights. It will present us the primary components of variation wherein neurons connect with totally different neurons within the subsequent layer (regardless of whether or not these connections are excitatory or inhibitory).
Positive sufficient, the singular vector (the biggest issue of variation) of the weights between the primary two convolutional layers of InceptionV1 is colour.
6. Singular vectors for the primary and second convolutional layers of InceptionV1, skilled on ImageNet (above) or Places365 (beneath). One can consider neurons being plotted nearer collectively on this diagram as that means they doubtless have a tendency to connect with comparable neurons.
We additionally see that the second issue seems to be frequency. This means an fascinating prediction: maybe if we had been to separate the layer into greater than two branches, we’d additionally observe specialization in frequency along with colour.
This looks like it might be true. For instance, right here we see a high-frequency black-and-white department, a mid-frequency largely black-and-white department, a mid-frequency colour department, and a low-frequency colour department.

7. We constructed a small ImageNet mannequin with the primary layer cut up into 4 branches. The remainder of the mannequin is roughly an InceptionV1 structure.
Parallels to neuroscience
We’ve proven that department specialization is one instance of a structural phenomenon — a larger-scale construction in a neural community. It occurs in quite a lot of conditions and neural community architectures, and it occurs with consistency – sure motifs of specialization, reminiscent of colour, frequency, and curves, occur persistently throughout totally different architectures and duties.
Returning to our comparability with anatomy, though we hesitate to say specific parallels to neuroscience, it’s tempting to attract analogies between department specialization and the existence of areas of the mind centered on explicit duties.
The visible cortex, the auditory cortex, Broca’s space and Wernicke’s space
The subspecialization throughout the V2 space of the primate visible cortex is one other robust instance from neuroscience. One sort of stripe inside V2 is delicate to orientation or luminance, whereas the opposite sort of stripe accommodates color-selective neurons.
We’re grateful to Patrick Mineault for noting this analogy, and for additional noting that the high-frequency options are in line with a number of the recognized representations of high-level options within the primate V2 space.
– these are all examples of mind areas with such constant specialization throughout broad populations of people who neuroscientists and psychologists have been in a position to characterize as having remarkably constant capabilities.
As researchers with out experience in neuroscience, we’re unsure how helpful this connection is, however it might be value contemplating whether or not department specialization could be a helpful mannequin of how specialization may emerge in organic neural networks.
This text is a part of the Circuits thread, an experimental format accumulating invited brief articles and important commentary delving into the internal workings of neural networks.
Writer Contributions
As with many scientific collaborations, the contributions are troublesome to separate as a result of it was a collaborative effort that we wrote collectively.
Analysis. The phenomenon of department specialization was initially noticed by Chris Olah. Chris additionally developed the load PCA experiments suggesting that it implicitly happens in non-branched fashions. This investigation was completed within the context of and knowledgeable by collaborative analysis into circuits by Nick Cammarata, Gabe Goh, Chelsea Voss, Ludwig Schubert, and Chris. Chelsea and Nick contributed to framing this work within the significance of bigger scale constructions on high of circuits.
Infrastructure. Department specialization was solely found as a result of an early model of Microscope by Ludwig Schubert made it simple to browse the neurons that exist at sure layers. Michael Petrov, Ludwig and Nick constructed quite a lot of infrastructural instruments which made our analysis doable.
Writing and Diagrams. Chelsea wrote the article, based mostly on an preliminary article by Chris and with Chris’s assist. Diagrams had been illustrated by each Chelsea and Chris.
Acknowledgments
We’re grateful to Brice Ménard for pushing us to analyze whether or not we will discover larger-scale constructions such because the one investigated right here.
We’re grateful to individuals of #circuits within the Distill Slack for his or her engagement on this text, and particularly to Alex Bäuerle, Ben Egan, Patrick Mineault, Matt Nolan, and Vincent Tjeng for his or her remarks on a primary draft. We’re grateful to Patrick Mineault for noting the neuroscience comparability to subspecialization inside primate V2.
References
- Imagenet classification with deep convolutional neural networks
Krizhevsky, A., Sutskever, I. and Hinton, G.E., 2012. Advances in neural data processing techniques, Vol 25, pp. 1097–1105. - Visualizing higher-layer options of a deep community [PDF]
Erhan, D., Bengio, Y., Courville, A. and Vincent, P., 2009. College of Montreal, Vol 1341, pp. 3. - Deep inside convolutional networks: Visualising picture classification fashions and saliency maps
Simonyan, Okay., Vedaldi, A. and Zisserman, A., 2013. arXiv preprint arXiv:1312.6034. - Multifaceted characteristic visualization: Uncovering the various kinds of options discovered by every neuron in deep neural networks [PDF]
Nguyen, A., Yosinski, J. and Clune, J., 2016. arXiv preprint arXiv:1602.03616. - Function Visualization https://distill.pub/2020/circuits/branch-specialization
Olah, C., Mordvintsev, A. and Schubert, L., 2017. Distill. DOI: 10.23915/distill.00007 - Going deeper with convolutions
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V. and Rabinovich, A., 2015. Proceedings of the IEEE convention on pc imaginative and prescient and sample recognition, pp. 1–9. - Neural structure search with reinforcement studying
Zoph, B. and Le, Q.V., 2016. arXiv preprint arXiv:1611.01578. - Neural networks are surprisingly modular
Filan, D., Hod, S., Wild, C., Critch, A. and Russell, S., 2020. arXiv preprint arXiv:2003.04881. - Are Neural Nets Modular? Inspecting Useful Modularity By Differentiable Weight Masks
Csordás, R., Steenkiste, S.v. and Schmidhuber, J., 2020. - Segregation of type, colour, and stereopsis in primate space 18 https://distill.pub/2020/circuits/branch-specialization
Hubel, D. and Livingstone, M., 1987. Journal of Neuroscience, Vol 7(11), pp. 3378–3415. Society for Neuroscience. DOI: 10.1523/JNEUROSCI.07-11-03378.1987 - Illustration of Angles Embedded inside Contour Stimuli in Space V2 of Macaque Monkeys https://distill.pub/2020/circuits/branch-specialization
Ito, M. and Komatsu, H., 2004. Journal of Neuroscience, Vol 24(13), pp. 3313–3324. Society for Neuroscience. DOI: 10.1523/JNEUROSCI.4364-03.2004
Updates and Corrections
Should you see errors or wish to counsel modifications, please create an issue on GitHub.
Reuse
Diagrams and textual content are licensed below Artistic Commons Attribution CC-BY 4.0 with the source available on GitHub, except famous in any other case. The figures which were reused from different sources don’t fall below this license and could be acknowledged by a word of their caption: “Determine from …”.
Quotation
For attribution in educational contexts, please cite this work as
Voss, et al., "Department Specialization", Distill, 2021.
BibTeX quotation
@article{voss2021branch,
creator = {Voss, Chelsea and Goh, Gabriel and Cammarata, Nick and Petrov, Michael and Schubert, Ludwig and Olah, Chris},
title = {Department Specialization},
journal = {Distill},
12 months = {2021},
word = {https://distill.pub/2020/circuits/branch-specialization},
doi = {10.23915/distill.00024.008}
}
[ad_2]
Source link
