

[ad_1]
With current technological breakthroughs in synthetic intelligence, Massive Language Fashions, or LLMs briefly, have turn into more and more prevalent. Over the previous few years, researchers have made speedy developments in fixing a number of complicated language-related duties by coaching these fashions on huge quantities of information to be able to comprehend intricate language patterns, generate coherent responses, and so on. One space of analysis that has notably gained the curiosity of researchers and builders is the appliance of LLMs relating to dealing with long-form content material to incorporate broader contexts. Some examples of those duties vary from comparatively easy duties like textual content summarization and code era to extra complicated downside statements like protein construction prediction and data retrieval. Lengthy textual sequences consist of knowledge in various types, similar to paragraphs, tables, pictures, and so on.; thus, LLMs have to be skilled to course of and perceive such parts. Furthermore, by successfully contemplating long-distance structural dependencies, LLMs can establish the connections between totally different components of the textual content and extract probably the most related info. Thus, publicity to a broader vary of data permits LLMs to offer extra correct and contextually related solutions to person queries.
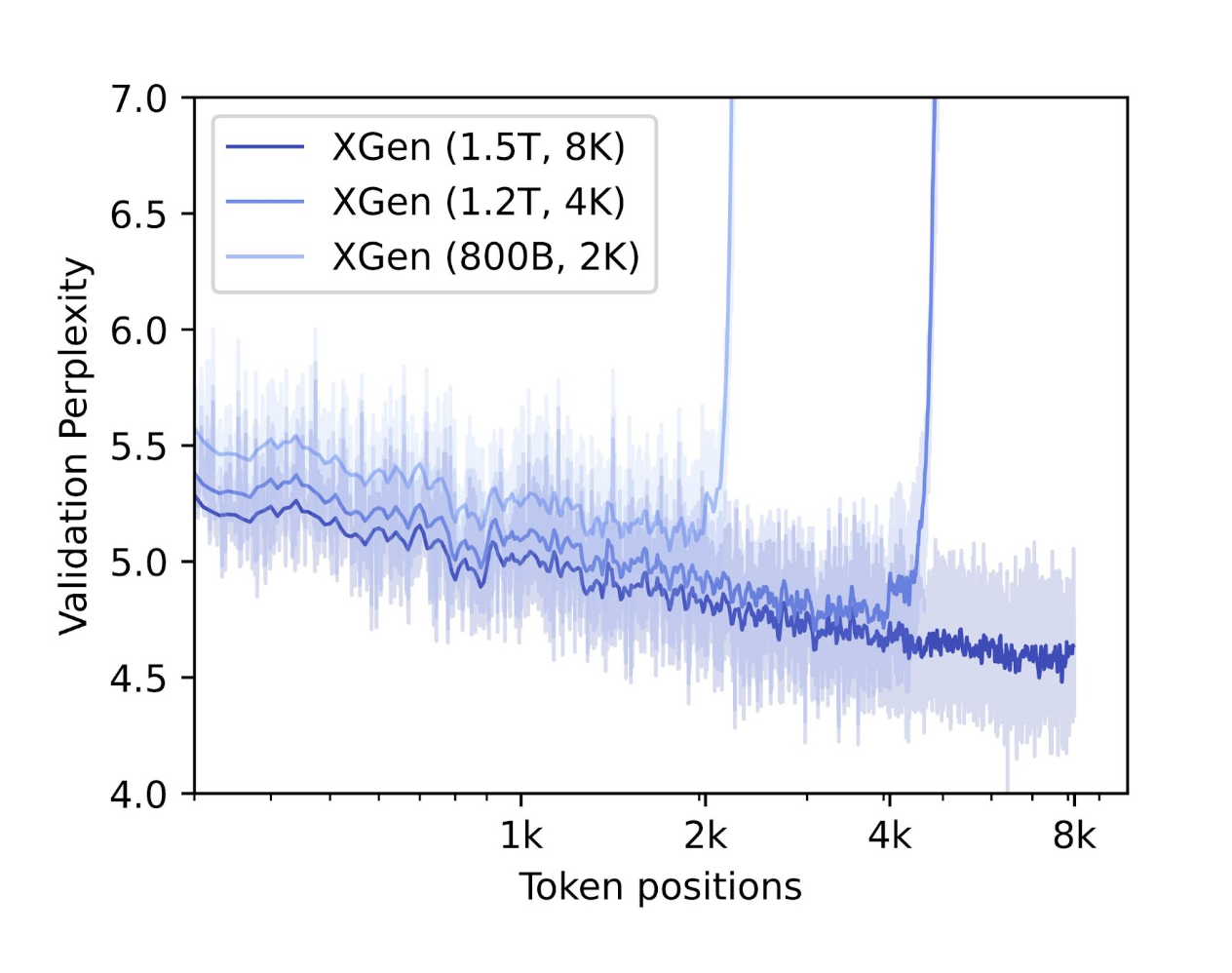
But, regardless of the quite a few potential use instances, most accessible open-source LLMs, starting from Meta’s LLaMA to MosaicML’s MPT LLM fashions, have been skilled on sequences with a most of 2K tokens. This limitation presents a big problem relating to modeling longer sequences. Moreover, earlier analysis on mannequin scaling has proven that smaller fashions skilled on a higher variety of tokens outperform bigger fashions when given a set computational finances. Thus, impressed by the issue at hand and present advances, Salesforce Analysis made groundbreaking achievements by introducing XGen-7B, a collection of 7B LLMs skilled on 8K sequence size for 1.5 trillion tokens. The collection of fashions embody XGen-7B-4K-Base (with assist for 4K sequence size), XGen-7B-8K-Base (with assist for 8K sequence size), and XGen-7B-8k-Inst which has been fine-tuned on public-domain educational information (launched just for analysis functions). The putting attribute of those LLMs is that on customary NLP benchmarks, XGen achieves comparable or higher outcomes when in comparison with different state-of-the-art LLMs of comparable measurement like MPT, Falcon, LLaMA, and so on.
The XGen-7b fashions employed on this examine had been skilled utilizing Salesforce’s proprietary library JaxFormer, which allows environment friendly coaching of LLMs using information and mannequin parallelism particularly optimized for TPU-v4 {hardware}. The coaching course of adopted the rules of LLaMA, augmented with two further investigations. The primary exploration targeted on understanding “loss spikes,” the place the loss out of the blue and briefly will increase throughout coaching with out a clear underlying trigger. Though the basis trigger of those spikes stays unknown, the researchers recognized elements similar to “sequential over parallel circuits,” “swish-GLU over GeLU,” and “RMS-Norm over Layer-norm” as potential contributors to coaching instability. The second side addressed was sequence size. Since coaching with longer sequences incurs considerably greater computational prices because of the quadratic complexity of self-attention, a staged coaching method was adopted. The coaching initially encompassed 800B tokens with a sequence size of 2k tokens, adopted by 400B tokens with 4k size, and at last, 300B tokens with 8k size.
To evaluate the capabilities of the XGen-7b 8k mannequin in comprehending longer contexts, the researchers performed evaluations utilizing three major duties: long-form dialogue era, textual content summarization, and question-answering. The researchers used the instruction-tuned mannequin for his or her evaluations pertaining to the issue of the duties at hand. Relating to long-form dialogue era, the researchers utilized three duties for evaluation: AMI assembly summarization, ForeverDreaming, and TVMegaSite screenplay summarization. Throughout all metrics, the XGen-7B-inst mannequin achieved the very best scores in comparison with a number of different instruction-tuned fashions, demonstrating its superior efficiency.
For long-form question-answering, the researchers generated questions utilizing ChatGPT based mostly on Wikipedia paperwork protecting various matters like Physics, Engineering, Historical past, and Leisure, together with their corresponding summaries. The LLM-generated solutions, which had been 256 tokens lengthy, had been evaluated utilizing GPT-4 based mostly on their construction, group, and relevance to the query and supply doc. On this state of affairs, the XGen-7B-8k-Inst mannequin outperformed the baseline fashions, that are restricted to 2k tokens, showcasing its superior efficiency. When it comes to textual content summarization, the researchers employed two datasets from totally different domains, particularly assembly conversations and authorities experiences, to judge the XGen-7b mannequin. The outcomes revealed that the XGen-7b mannequin considerably outperformed different baseline fashions in these duties, indicating its superior efficiency in textual content summarization as properly.
The evaluations demonstrated that the XGen-7b mannequin excelled in understanding longer contexts throughout numerous duties, together with long-form dialogue era, question-answering, and textual content summarization. Its efficiency surpassed that of different instruction-tuned and baseline fashions, showcasing its effectiveness in comprehending and producing coherent responses in in depth textual content contexts. However, regardless of its efficacy, the researchers acknowledge a limitation of the XGen mannequin, as it’s not exempt from biases and has the potential to generate poisonous responses, a attribute it shares with many different AI fashions. Salesforce Analysis has additionally open-sourced its code to permit the group to discover its work.
Test Out the SF Blog and Github Link. Don’t overlook to hitch our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra. When you have any questions relating to the above article or if we missed something, be happy to electronic mail us at Asif@marktechpost.com
Featured Instruments:
🚀 Check Out 100’s AI Tools in AI Tools Club
Khushboo Gupta is a consulting intern at MarktechPost. She is at the moment pursuing her B.Tech from the Indian Institute of Know-how(IIT), Goa. She is passionate in regards to the fields of Machine Studying, Pure Language Processing and Internet Improvement. She enjoys studying extra in regards to the technical discipline by taking part in a number of challenges.
[ad_2]
Source link
