


[ad_1]
Picture by Creator
Anomaly Detection is a vital process that you may meet otherwise you’ll meet sooner or later finally if you’re coping with knowledge. It’s very utilized in lots of fields, like manufacturing, finance and cybersecurity.
Getting began with this subject for the primary time could be difficult by your self with no information that orients you step-by-step. In my first expertise as an information scientist, I keep in mind that I struggled rather a lot to have the ability to grasp this self-discipline.
Initially, Anomaly Detection includes the identification of uncommon observations with values that deviate drastically from the remainder of the info factors. These anomalies, usually referred to as outliers, are a minority, whereas many of the objects belong to the conventional class. Which means that we’re coping with an imbalanced dataset.
One other problem is that more often than not there isn’t any labelled knowledge when working within the business and it’s difficult to interpret the predictions with none goal. This implies that you may’t use analysis metrics usually used for classification fashions and it’s essential undertake different strategies to interpret and belief the output of your mannequin. Let’s get began!
Anomaly detection refers back to the downside of discovering patterns in knowledge that don’t conform to anticipated habits. These nonconforming patterns are also known as anomalies, outliers, discordant observations, exceptions, aberrations, surprises, peculiarities, or contaminants in numerous utility domains. Credit score Anomaly Detection: A Survey
This can be a good definition of anomaly detection in just a few phrases. Anomalies are sometimes related to errors obtained throughout knowledge assortment and, then, they end to be eradicated. However there are additionally instances when there are new objects with a very completely different variability in comparison with the remainder of the info and there’s a want for applicable approaches to acknowledge the sort of commentary. The identification of those observations could be very helpful for making choices in corporations working in lots of sectors, similar to finance and manufacturing.
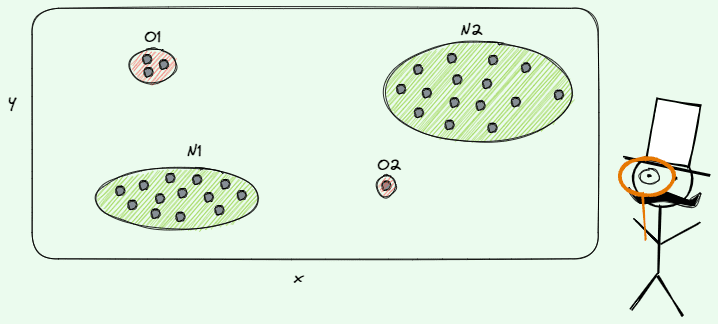
There are three predominant varieties of anomalies: level anomalies, contextual anomalies and collective anomalies.
Instance of level anomaly. Illustration by Creator.
As you could deduce, level anomalies represent the only case. It occurs when a single commentary is anomalous in comparison with the remainder of the info, so it’s recognized as an outlier/anomaly. For instance, let’s suppose that we need to make bank card fraud detection within the transactions of shoppers in a financial institution. In that case, some extent anomaly could be thought of a fraudulent exercise of a shopper.

Instance of contextual anomaly. Credit score EPA. Modified by Creator.
One other case of anomaly could be a contextual anomaly. You possibly can meet the sort of anomaly solely in a selected context. An instance could be the summer time warmth waves in the USA. You possibly can discover that there’s a large spike in 1930, which represents an excessive occasion that occurred in the USA, referred to as Mud Bowl. It’s referred to as that method as a result of it was a interval of mud storms that broken the south-central United States.
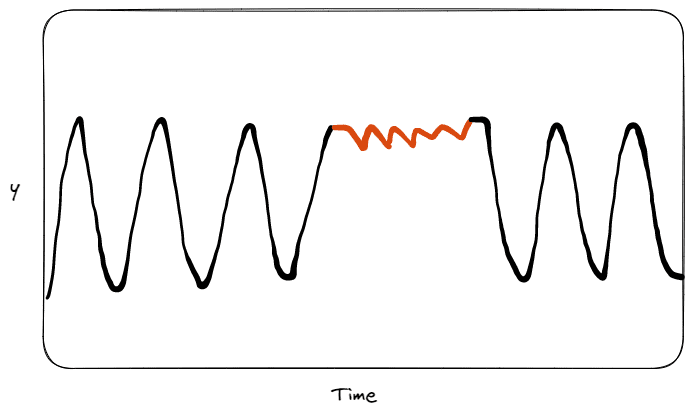
Instance of collective anomaly. Illustration by Creator.
The third and final kind of anomaly is the collective anomaly. Probably the most intuitive instance is to consider the absence of precipitations we’re having this yr from months in Italy. If we evaluate the info within the final 50 years, there haven’t ever been related behaviours. The only knowledge cases in an anomalous collective will not be recognized as outliers by themselves, however all these knowledge factors collectively point out a collective anomaly. On this context, a single day with out precipitation is just not anomalous by itself, whereas a whole lot of days with out precipitation could be thought of anomalous in comparison with the info of earlier years.
There are a number of approaches that may be utilized to anomaly detection:
- Isolation Forest is an unsupervised and non-parametric method launched by Fey Tony Liu in 2012. Just like the random forest, it’s an ensemble studying methodology that trains resolution bushes in a parallel method. However otherwise from different ensemble strategies, it’s specialised in isolating the anomalies from the remainder of the objects. The assumptions behind this strategy represent the explanation for the effectiveness of this strategy: (1) the anomalies are a part of a minority class in comparison with the conventional knowledge that are extra quite a few; (2) the anomalies are usually discovered fastly with the shortest common path.
- Native Outlier Issue is a density-based clustering algorithm proposed by Markus M. Breuningin 2000, that detects anomalies by calculating the native density deviation of a selected merchandise with respect to its neighbours. It assumes that the density round an anomaly ought to be considerably completely different from the density round its neighbours. Furthermore, the outliers ought to have decrease density.
- Autoencoder is an unsupervised mannequin composed of two neural networks, an encoder and a decoder. Throughout coaching, solely regular knowledge is handed to the mannequin. On this method, it learns the compressed illustration of regular knowledge, which is meant to be completely different from the illustration of outliers. There’s additionally the belief that anomalous knowledge shouldn’t be reconstructed properly by the mannequin because it’s utterly completely different from regular knowledge and, then, it ought to have the next reconstruction error.
In an unsupervised setting, there are not any analysis metrics that may make it easier to to grasp the speed of right optimistic predictions (precision) or the speed of the particular positives (recall).
With none chance of evaluating the efficiency of the mannequin, it’s extra necessary than ever to supply an evidence of mannequin predictions. This may be achieved by utilizing interpretability approaches, like SHAP and LIME.
There are two doable interpretations: international and native. The intention of world interpretability is to supply explanations of the mannequin as an entire, whereas the native interpretability goals at explaining the mannequin prediction of a single occasion.
I hope you discovered helpful this quick overview of anomaly detection strategies. As you’ve gotten observed, it’s a difficult downside to resolve and the acceptable method modifications relying on the context. I additionally ought to spotlight that it’s necessary to make some explorative evaluation earlier than making use of any anomaly detection mannequin, like PCA to visualise the info in a decrease dimensional area and boxplots. If you wish to go deeper, examine the assets under. Thanks for studying! Have a pleasant day!
Assets
Eugenia Anello is presently a analysis fellow on the Division of Info Engineering of the College of Padova, Italy. Her analysis challenge is targeted on Continuous Studying mixed with Anomaly Detection.
[ad_2]
Source link
