


[ad_1]
By Ankit, Bhaskar & Malhar
Over the previous few years, there was outstanding progress within the subject of Pure Language Processing, due to the emergence of huge language fashions. Language fashions are utilized in machine translation techniques to discover ways to map strings from one language to a different. Among the many household of language fashions, the Generative Pre-trained Transformer (GPT) based mostly Mannequin has garnered probably the most consideration in latest instances. Initially, the language fashions have been rule-based techniques that closely relied on human enter to perform. Nonetheless, the evolution of deep studying strategies has positively impacted the complexity, scale and accuracy of the duties dealt with by these fashions.
In our previous blog, we offered a complete rationalization of the assorted points of the GPT3 mannequin, evaluated options supplied by Open AI’s GPT-3 API and in addition explored the mannequin’s utilization and limitations. On this weblog, we are going to shift our focus to the GPT Mannequin and its foundational elements. We may also take a look at evolution – ranging from GPT-1 to the not too long ago launched GPT-4 and dive into the important thing enhancements performed in every technology that made the fashions potent over time.
GPT (Generative Pre-trained Transformers) is a deep learning-based Giant Language Mannequin (LLM), using a decoder-only structure constructed on transformers. Its objective is to course of textual content knowledge and generate textual content output that resembles human language.
Because the identify suggests, there are three pillars of the mannequin particularly:
- Generative
- Pre-trained
- Transformers
Let’s discover the mannequin via these elements:
Generative: This characteristic emphasizes the mannequin’s potential to generate textual content by comprehending and responding to a given textual content pattern. Previous to GPT fashions, textual content output was generated by rearranging or extracting phrases from the enter itself. The generative functionality of GPT fashions gave them an edge over current fashions, enabling the manufacturing of extra coherent and human-like textual content.
This generative functionality is derived from the modeling goal used throughout coaching.
GPT fashions are skilled utilizing autoregressive language modeling, the place the fashions are fed with an enter sequence of phrases, and the mannequin tries to seek out probably the most appropriate subsequent phrase by using chance distributions to foretell probably the most possible phrase or phrase.
Pre-Skilled: “Pre-trained” refers to an ML mannequin that has undergone coaching on a big dataset of examples earlier than being deployed for a particular process. Within the case of GPT, the mannequin is skilled on an intensive corpus of textual content knowledge utilizing an unsupervised studying method. This enables the mannequin to study patterns and relationships throughout the knowledge with out specific steerage.
In easier phrases, coaching the mannequin with huge quantities of knowledge in an unsupervised method helps it perceive the final options and construction of a language. As soon as realized, the mannequin can leverage this understanding for particular duties similar to query answering and summarization.
Transformers: A sort of neural community structure that’s designed to deal with textual content sequences of various lengths. The idea of transformers gained prominence after the groundbreaking paper titled “Consideration Is All You Want” was revealed in 2017.
GPT makes use of decoder-only structure.The first element of a transformer is its “self-attention mechanism,” which permits the mannequin to seize the connection between every phrase and different phrases throughout the identical sentence.
Instance:
- A canine is sitting on the financial institution of the River Ganga.
- I’ll withdraw some cash from the financial institution.
Self-attention evaluates every phrase in relation to different phrases within the sentence. Within the first instance when “financial institution” is evaluated within the context of “River”, the mannequin learns that it refers to a river financial institution. Equally, within the second instance, evaluating “financial institution” with respect to the phrase “cash” suggests a monetary financial institution.
Now, let’s take a more in-depth take a look at the assorted variations of GPT Fashions, with a concentrate on the enhancements and additions launched in every subsequent mannequin.
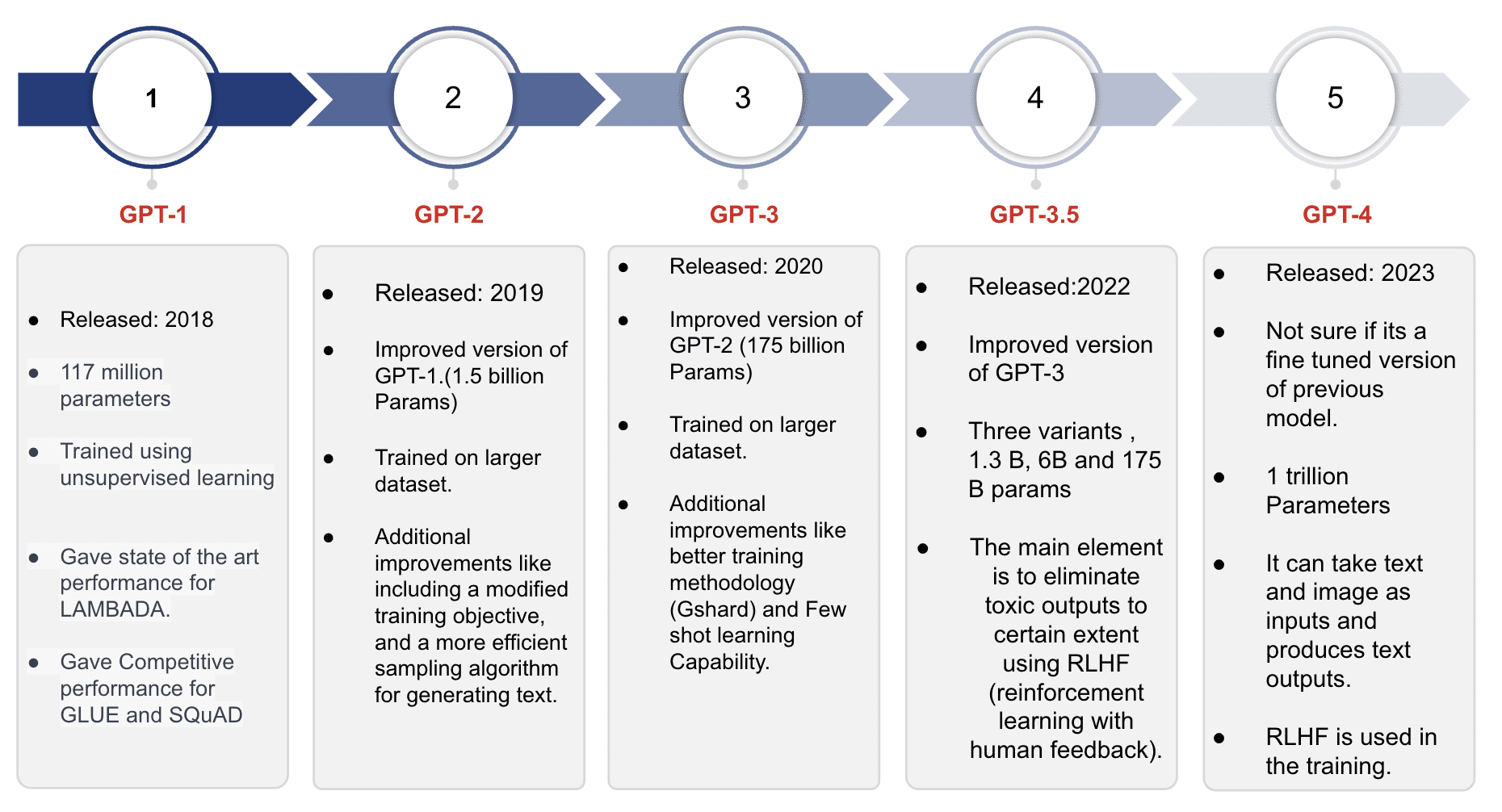
*Slide 3 in GPT Models
GPT-1
It’s the first mannequin of the GPT collection and was skilled on round 40GB of textual content knowledge. The mannequin achieved state-of-the-art outcomes for modeling duties like LAMBADA and demonstrated aggressive efficiency for duties like GLUE and SQuAD. With a most context size of 512 tokens (round 380 phrases), the mannequin may retain data for comparatively quick sentences or paperwork per request. The mannequin’s spectacular textual content technology capabilities and robust efficiency on customary duties offered the impetus for the event of the next mannequin within the collection.
GPT-2
Derived from the GPT-1 Mannequin, the GPT-2 Mannequin retains the identical architectural options. Nonetheless, it undergoes coaching on a fair bigger corpus of textual content knowledge in comparison with GPT-1. Notably, GPT-2 can accommodate double the enter dimension, enabling it to course of extra in depth textual content samples. With practically 1.5 billion parameters, GPT-2 displays a major enhance in capability and potential for language modeling.
Listed here are some main enhancements in GPT-2 over GPT 1:
- Modified Goal Coaching is a method utilized through the pre-training part to reinforce language fashions. Historically, fashions predict the following phrase within the sequence solely based mostly on earlier phrases, resulting in doubtlessly incoherent or irrelevant predictions. MO coaching addresses this limitation by incorporating further context, similar to Components of Speech (Noun, Verb, and many others.) and Topic-Object Identification. By leveraging this supplementary data, the mannequin generates outputs which are extra coherent and informative.
- Layer normalization is one other approach employed to enhance coaching and efficiency. It entails normalizing the activations of every layer throughout the neural community, reasonably than normalizing the community’s inputs or outputs as a complete. This normalization mitigates the difficulty of Inner Covariate Shift, which refers back to the change within the distribution of community activations attributable to alterations in community parameters.
- GPT 2 can also be powered by superior sampling algorithms as in comparison with GPT 1. Key enhancements embrace:
- High – p sampling: Solely tokens with cumulative chance mass exceeding a sure threshold are thought-about throughout sampling. This avoids sampling from low-probability tokens, leading to extra various and coherent textual content technology.
- Temperature scaling of the logits (i.e., the uncooked output of the neural community earlier than Softmax), controls the extent of randomness within the generated textual content. Decrease temperatures yield extra conservative and predictable textual content, whereas increased temperatures produce extra artistic and sudden textual content.
- Unconditional sampling (random sampling) choice, which permits customers to discover the mannequin’s generative capabilities and might produce ingenious outcomes.
GPT-3
| Coaching Information supply | Coaching Information Measurement |
| Frequent Crawl, BookCorpus, Wikipedia, Books, Articles, and extra | over 570 GB of textual content knowledge |
The GPT-3 Mannequin is an evolution of the GPT-2 Mannequin, surpassing it in a number of points. It was skilled on a considerably bigger corpus of textual content knowledge and featured a most of 175 billion parameters.
Together with its elevated dimension, GPT-3 launched a number of noteworthy enhancements:
- GShard (Large-Sharded mannequin parallelism): permits the mannequin to be break up throughout a number of accelerators. This facilitates parallel coaching and inference, significantly for giant language fashions with billions of parameters.
- Zero-shot studying capabilities facilitates GPT-3 to exhibit the power to carry out duties for which it hadn’t been explicitly skilled. This implies it may generate textual content in response to novel prompts by leveraging its normal understanding of language and the given process.
- Few-shot studying capabilities powers GPT-3 to shortly adapt to new duties and domains with minimal coaching. It demonstrates a formidable potential to study from a small variety of examples.
- Multilingual assist: GPT-3 is proficient in producing textual content in ~30 languages, together with English, Chinese language, French, German, and Arabic. This broad multilingual assist makes it a extremely versatile language mannequin for various functions.
- Improved sampling: GPT-3 makes use of an improved sampling algorithm that features the power to regulate the randomness in generated textual content, much like GPT-2. Moreover, it introduces the choice of “prompted” sampling, enabling textual content technology based mostly on user-specified prompts or context.
GPT-3.5
| Coaching Information supply | Coaching Information Measurement |
| Frequent Crawl, BookCorpus, Wikipedia, Books, Articles, and extra | > 570 GB |
Much like its predecessors, the GPT-3.5 collection fashions have been derived from the GPT-3 fashions. Nonetheless, the distinguishing characteristic of GPT-3.5 fashions lies of their adherence to particular insurance policies based mostly on human values, integrated utilizing a method referred to as Reinforcement Studying with Human Suggestions (RLHF). The first goal was to align the fashions extra carefully with the person’s intentions, mitigate toxicity, and prioritize truthfulness of their generated output. This evolution signifies a aware effort to reinforce the moral and accountable utilization of language fashions as a way to present a safer and extra dependable person expertise.
Enhancements over GPT-3:
OpenAI used Reinforcement Studying from human suggestions to fine-tune GPT-3 and allow it to comply with a broad set of directions. The RLHF approach entails coaching the mannequin utilizing reinforcement studying ideas, whereby the mannequin receives rewards or penalties based mostly on the standard and alignment of its generated outputs with human evaluators. By integrating this suggestions into the coaching course of, the mannequin good points the power to study from errors and improve its efficiency, finally producing textual content outputs which are extra pure and charming.
GPT 4
GPT-4 represents the most recent mannequin within the GPT collection introducing multimodal capabilities that enable it to course of each textual content and picture inputs whereas producing textual content outputs. It accommodates numerous picture codecs, together with paperwork with textual content, pictures, diagrams, graphs, schematics, and screenshots.
Whereas OpenAI has not disclosed technical particulars similar to mannequin dimension, structure, coaching methodology, or mannequin weights for GPT-4, some estimates counsel that it includes practically 1 trillion parameters. The bottom mannequin of GPT-4 follows a coaching goal much like earlier GPT fashions, aiming to foretell the following phrase given a sequence of phrases. The coaching course of concerned utilizing an enormous corpus of publicly out there web knowledge and licensed knowledge.
GPT-4 has showcased superior efficiency in comparison with GPT-3.5 in OpenAI’s inner adversarial factuality evaluations and public benchmarks like TruthfulQA. The RLHF strategies utilized in GPT-3.5 have been additionally integrated into GPT-4. OpenAI actively seeks to reinforce GPT-4 based mostly on suggestions obtained from ChatGPT and different sources.
Scores of GPT-1,GPT-2 and GPT-3 in customary NLP Modeling duties LAMBDA, GLUE and SQuAD.
| Mannequin | GLUE | LAMBADA | SQuAD F1 | SQuAD Precise Match |
| GPT-1 | 68.4 | 48.4 | 82.0 | 74.6 |
| GPT-2 | 84.6 | 60.1 | 89.5 | 83.0 |
| GPT-3 | 93.2 | 69.6 | 92.4 | 88.8 |
| GPT-3.5 | 93.5 | 79.3 | 92.4 | 88.8 |
| GPT-4 | 94.2 | 82.4 | 93.6 | 90.4 |
All numbers are in Percentages. || supply – BARD
This desk demonstrates the constant enchancment in outcomes, which could be attributed to the aforementioned enhancements.
GPT-3.5 and GPT-4 are examined on the newer benchmarks checks and customary examinations.
The newer GPT fashions, (3.5 and 4) are examined on the duties that require reasoning and area data. The fashions have been examined on quite a few examinations that are recognized to be difficult. One such examination for which GPT-3 (ada, babbage, curie, davinci), GPT-3.5 , ChatGPT and GPT-4 are in contrast is the MBE Examination. From the graph we will see steady enchancment in rating, with GPT-4 even beating the typical scholar rating.
Determine 1 illustrates the comparability of share of marks obtained in MBE* by totally different GPT fashions:
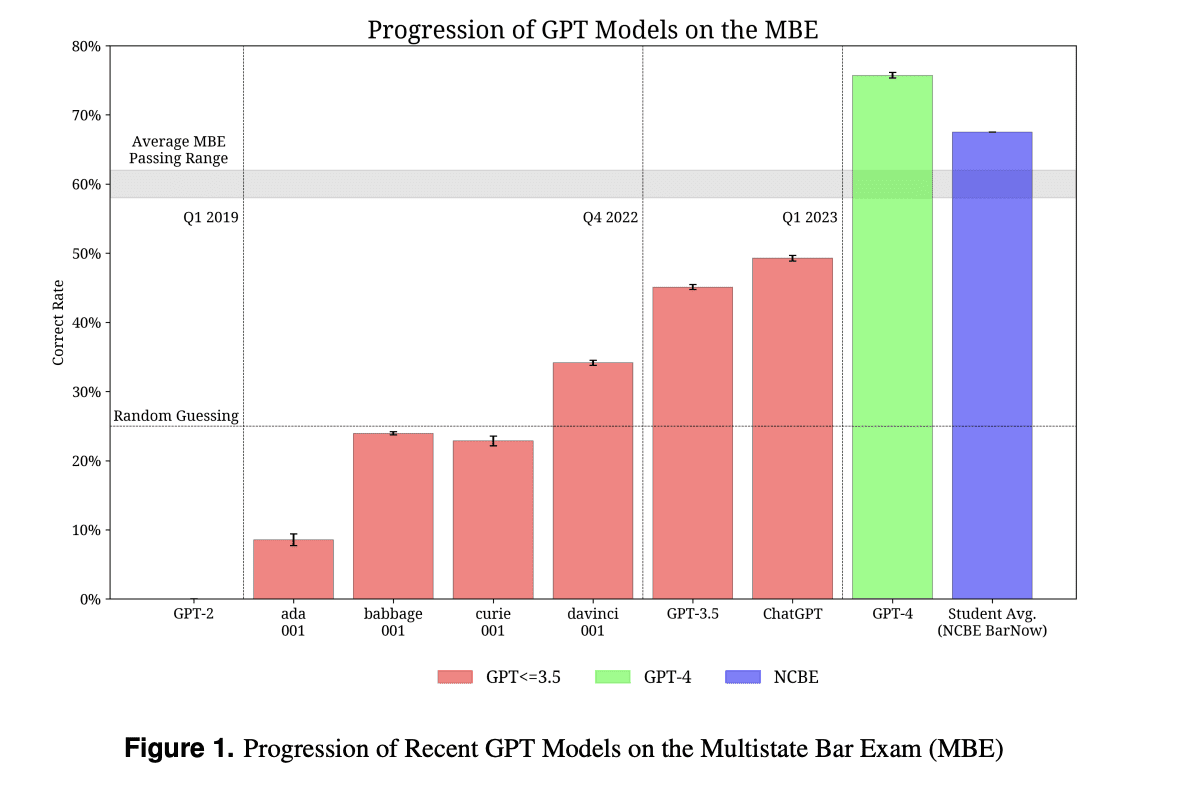
*The Multistate Bar Examination (MBE) is a difficult battery of checks designed to judge an applicant’s authorized data and expertise, and is a precondition to apply regulation within the US.
The beneath graphs additionally highlights the progress of the fashions and once more beating the typical college students scores for various streams of authorized topic areas.
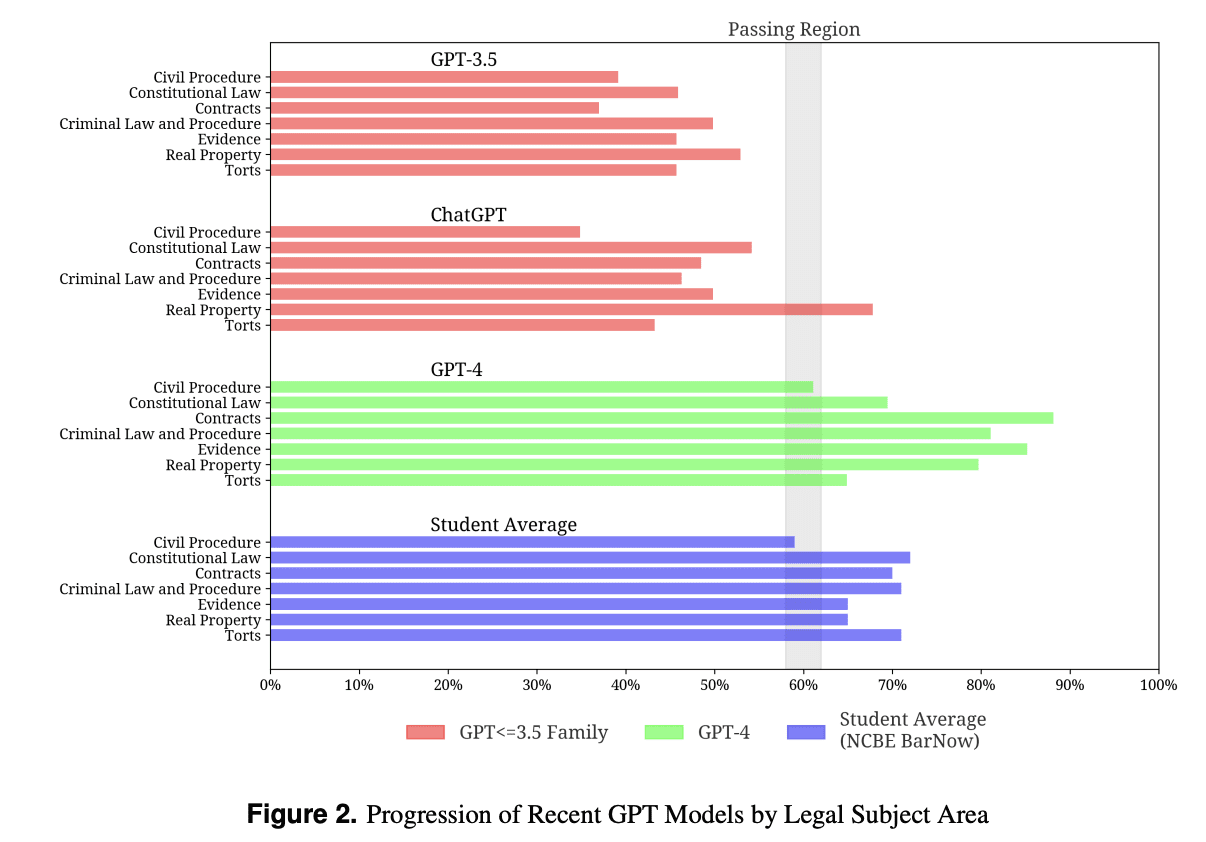
Supply: Data Science Association
Conclusion
The above outcomes validate the facility of those new fashions with mannequin efficiency being in contrast towards the human scores is an enormous indicator of the identical. In a brief span of about 5 years because the introduction of GPT-1 the mannequin dimension has grown round ~8,500 instances.
Within the subsequent weblog, we are going to discover specialised variations of GPT fashions in higher element, together with their creation course of, capabilities, and potential functions. A comparative evaluation of fashions can be performed to realize precious insights into their strengths and limitations.
Index
| GPT-1 | GPT-2 | GPT-3 (175B) | GPT-3.5 | GPT-4 | |
| GLUE | 65.4 | 77.7 | 92.8 | ||
| LAMBADA | 25.4% | 63.24% (ZS) | 76.2% (ZS) | ||
| SQuAD F1 Rating | 60.3% | 72.1% | 93 % | ||
| SQuAD Precise Match – EM Rating | 56.0% | 62.4% | 87.1% |
Observe: ZS: Zero Shot ,Supply: ChatGPT, BARD
With the rise of Transformer-based Giant Language Fashions (LLMs), the sector of pure language processing is present process speedy evolution. Among the many numerous language fashions constructed on this structure, the GPT fashions have emerged distinctive when it comes to output and efficiency. OpenAI, the group behind GPT, has persistently enhanced the mannequin on a number of fronts because the launch of the primary mannequin.
Over the course of 5 years, the scale of the mannequin has scaled considerably, increasing roughly 8,500 instances from GPT-1 to GPT-4. This outstanding progress could be attributed to steady enhancements in areas similar to coaching knowledge dimension, knowledge high quality, knowledge sources, coaching strategies, and the variety of parameters. These elements have performed a pivotal position in enabling the fashions to ship excellent efficiency throughout a variety of duties.
- Ankit Mehra is a Senior Information Scientist at Sigmoid. He focuses on analytics and ML-based knowledge options.
- Malhar Yadav is an Affiliate Information Scientist at Sigmoid and a coding and ML fanatic.
- Bhaskar Ammu is a Senior Lead Information Scientist at Sigmoid. He focuses on designing knowledge science options for shoppers, constructing database architectures, and managing initiatives and groups.
[ad_2]
Source link
