

[ad_1]
Pretrained language fashions (PLMs) have considerably improved on many downstream NLP duties as a result of finetuning. Whereas present PLMs can embrace a whole bunch of thousands and thousands of parameters, the normal paradigm of full task-specific finetuning (FT) is difficult to increase to quite a few duties. The necessity to study fewer parameters per job than crucial for complete finetuning has led to a surge in analysis on “parameter-efficient” strategies for mannequin tuning.
For parameter-efficient switch studying with PLMs, immediate tuning (PT) has not too long ago emerged as a possible choice. PT works by appending tunable steady immediate vectors to the enter earlier than coaching. The PLM settings are locked in place, and PT learns solely a restricted variety of immediate vectors for every job. But, there may be nonetheless a big hole between instantaneous tuning and full finetuning regardless of their outstanding efficiency. This methodology can also be extremely delicate to the initiation, necessitating longer coaching occasions than finetuning procedures usually.
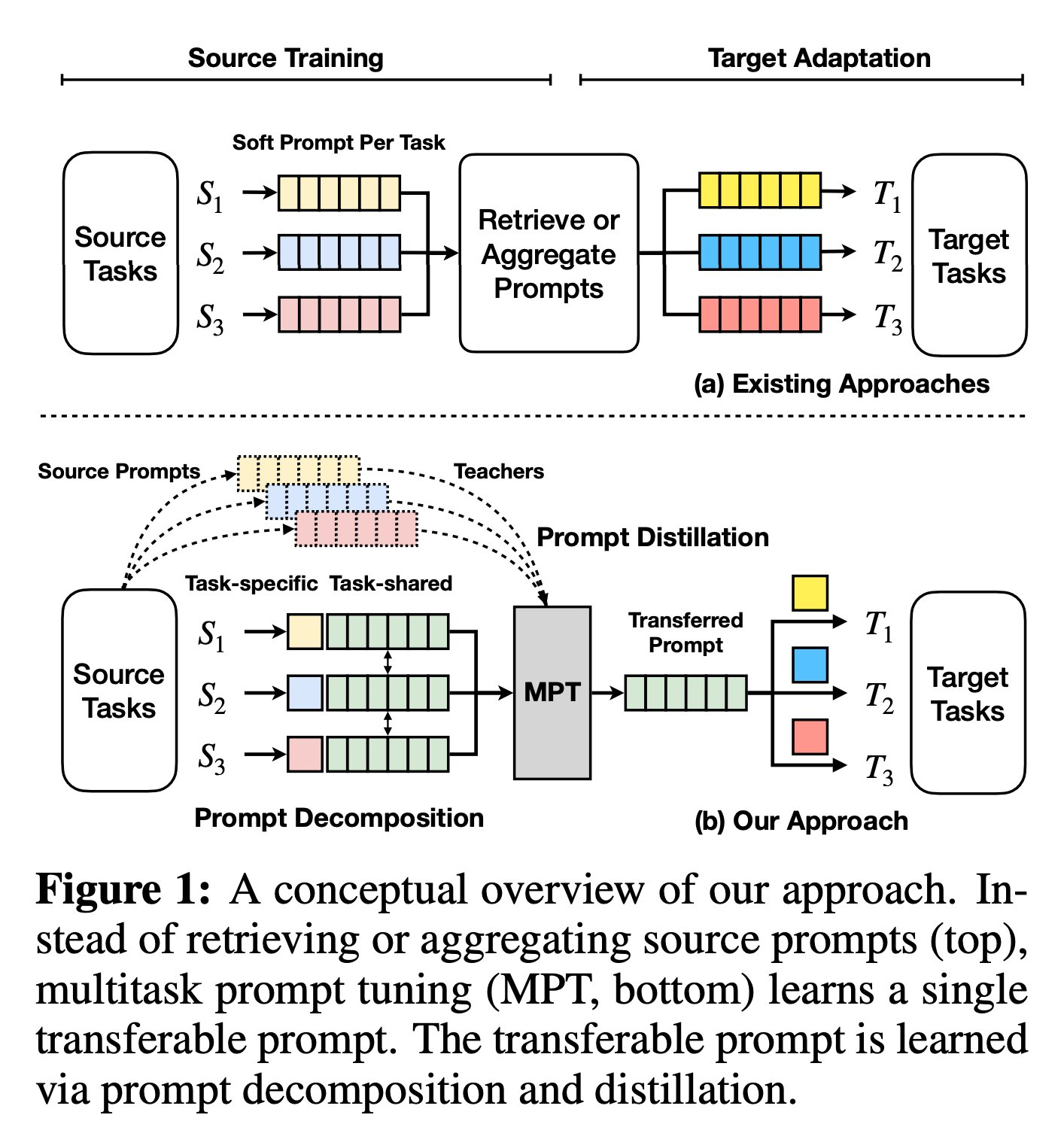
Current research have proposed to repair these issues by reusing immediate vectors from different jobs. These methods start by coaching mushy prompts on numerous supply duties. They then use these pretrained prompts as a place to begin for finetuning the immediate on a goal job utilizing a (probably discovered) similarity measure.
Researchers from the Ohio State College, MIT-IBM Watson AI Lab, and Massachusetts Institute of Expertise additional develop this line of analysis by introducing multitask immediate tuning (MPT), which makes use of multitask information to study a single immediate that could be effectively transmitted to focus on actions.
Whereas the concept behind studying a shared immediate house is easy, in apply, it may be fairly tough to grasp. It is because it wants to accumulate information of the similarities between numerous supply duties whereas concurrently lowering their interference. As a substitute of merely sharing the immediate matrix throughout all duties, the researchers discover that decomposing the mushy immediate of every supply job right into a multiplication of a shared matrix and a low-rank task-specific matrix is extra profitable. Decomposition is taught by distilling info from light prompts acquired by means of constant immediate tuning. They execute low-rank multiplicative modifications to the widespread immediate matrix to modify between jobs.
Complete exams on 23 NLP datasets for numerous duties present that the urged methodology outperforms state-of-the-art immediate switch strategies. By tuning a lot fewer task-specific immediate parameters than probably the most aggressive multitask immediate switch baseline, MPT with T5-Base achieves a 16.3% enchancment over the vanilla immediate tuning baseline on the SuperGLUE benchmark. Sure efficiency metrics present that MPT outperforms full finetuning, regardless of utilizing solely 0.035 p.c configurable parameters per job. With 4-32 labels per goal job, the staff additionally discover that MPT is kind of profitable for few-shot studying.
Try the Paper. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t overlook to hitch our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
Tanushree Shenwai is a consulting intern at MarktechPost. She is presently pursuing her B.Tech from the Indian Institute of Expertise(IIT), Bhubaneswar. She is a Knowledge Science fanatic and has a eager curiosity within the scope of utility of synthetic intelligence in numerous fields. She is enthusiastic about exploring the brand new developments in applied sciences and their real-life utility.
[ad_2]
Source link
