

[ad_1]
Proteins, the vitality of the cell, are concerned in numerous purposes, together with materials and coverings. They’re made up of an amino acid chain that folds right into a sure form. A major variety of novel protein sequences have been discovered not too long ago because of the improvement of low-cost sequencing know-how. Correct and efficient in silico protein operate annotation strategies are required to shut the present sequence-function hole since useful annotation of a novel protein sequence remains to be costly and time-consuming.
Many data-driven approaches depend on studying representations of the protein buildings as a result of many protein capabilities are managed by how they’re folded. These representations can then be utilized to duties like protein design, construction classification, mannequin high quality evaluation, and performance prediction.
The variety of printed protein buildings is orders of magnitude lower than the variety of datasets in different machine-learning software fields because of the problem of experimental protein construction identification. As an example, the Protein Knowledge Financial institution has 182K experimentally confirmed buildings, in comparison with 47M protein sequences in Pfam and 10M annotated photos in ImageNet. A number of research have used the abundance of unlabeled protein sequence information to develop a correct illustration of current proteins to shut this representational hole. Many researchers have used self-supervised studying to pretrain protein encoders on tens of millions of sequences.
Latest developments in correct deep learning-based protein construction prediction strategies have made it possible to successfully and confidently predict the buildings of many protein sequences. Nonetheless, these strategies don’t particularly seize or use the details about protein construction that’s recognized to find out how proteins operate. Many structure-based protein encoders have been proposed to make use of structural info higher. Sadly, the interactions between edges, that are essential in simulating protein construction, have but to be explicitly addressed in these fashions. Furthermore, because of the dearth of experimentally established protein buildings, comparatively little work has been finished up till not too long ago to create pretraining strategies that make the most of unlabeled 3D buildings.
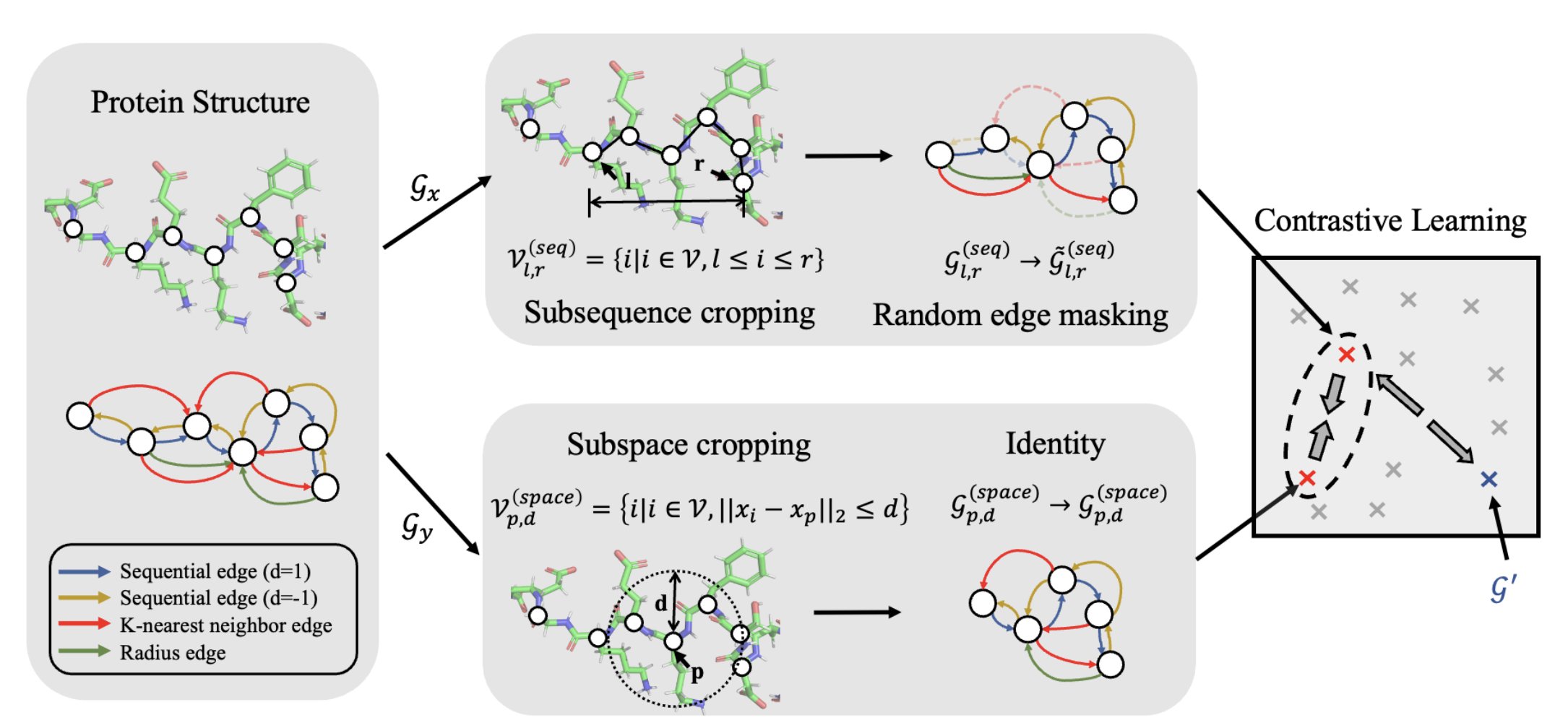
Impressed by this development, they create a protein encoder that may be utilized to a spread of property prediction purposes and is pretrained on probably the most possible protein buildings. They counsel a simple but environment friendly structure-based encoder termed the GeomEtry-Conscious Relational Graph Neural Community, which conducts relational message passing on protein residue graphs after encoding spatial info by together with numerous structural or sequential edges. They counsel a sparse edge message passing approach to enhance the protein construction encoder, which is the primary effort to implement edge-level message passing on GNNs for protein construction encoding. Their concept was impressed by the design of the triangle consideration in Evoformer.
In addition they present a geometrical pretraining strategy primarily based on the well-known contrastive studying framework to be taught the protein construction encoder. They counsel revolutionary augmentation capabilities that improve the similarity between acquired representations of substructures from the identical protein whereas lowering that between these from completely different proteins to search out physiologically linked protein substructures that co-occur in proteins. They concurrently counsel a set of straightforward baselines primarily based on self-prediction.
They established a robust basis for pretraining protein construction representations by evaluating their pretraining strategies in opposition to a number of downstream property prediction duties. These pretraining issues embody the masked prediction of varied geometric or physicochemical properties, reminiscent of residue varieties, Euclidean distances, and dihedral angles. Quite a few exams utilizing a wide range of benchmarks, reminiscent of Enzyme Fee quantity prediction, Gene Ontology time period prediction, fold’classification, and response classification, present that GearNet enhanced with edge message passing can persistently outperform current protein encoders on the vast majority of duties in a supervised atmosphere.
Furthermore, utilizing the urged pretraining technique, their mannequin skilled on fewer than 1,000,000 samples obtains outcomes equal to and even higher than these of probably the most superior sequence-based encoders pretrained on datasets of 1,000,000 or billion. The codebase is publicly accessible on Github. It’s written in PyTorch and Torch Drug.
Try the Paper and Github Link. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t neglect to hitch our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
Aneesh Tickoo is a consulting intern at MarktechPost. He’s presently pursuing his undergraduate diploma in Knowledge Science and Synthetic Intelligence from the Indian Institute of Expertise(IIT), Bhilai. He spends most of his time engaged on tasks aimed toward harnessing the facility of machine studying. His analysis curiosity is picture processing and is keen about constructing options round it. He loves to attach with folks and collaborate on fascinating tasks.
[ad_2]
Source link
