

[ad_1]
Cybersecurity defenders should dynamically adapt their methods and techniques as expertise develops and the extent of complexity in a system surges. As machine studying (ML) and synthetic intelligence (AI) analysis has superior over the previous ten years, so have the use circumstances for these applied sciences in numerous cybersecurity-related domains. A couple of functionalities in most current safety functions are backed by robust machine-learning algorithms educated on substantial datasets. One such occasion is the early 2010s integration of ML algorithms in e-mail safety gateways.
In relation to the real-world situation, creating autonomous cyber system protection methods and motion suggestions is slightly a tough enterprise. It’s because offering choice help for such cyber system protection mechanisms requires each the incorporation of dynamics between attackers and defenders and the dynamical characterization of uncertainty within the system state. Furthermore, cyber defenders typically face quite a lot of useful resource limitations, together with these associated to price, labor, and time. Even with AI, creating a system able to proactive protection stays an ideological objective.
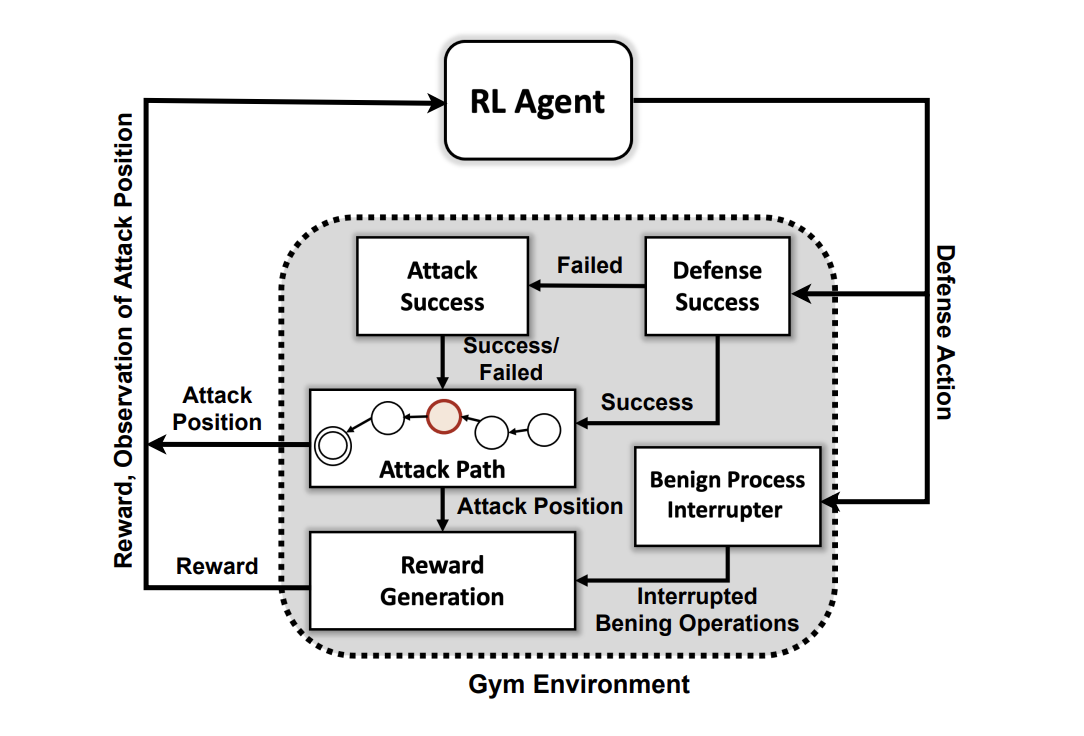
In an effort to supply an answer to this drawback assertion, researchers from the Division of Vitality’s Pacific Northwest Nationwide Laboratory (PNNL) have created a novel AI system based mostly on deep reinforcement studying (DRL) that’s able to responding to attackers in a simulated surroundings and might cease 95% of cyberattacks earlier than they escalate. The researchers created a customized simulation surroundings demonstrating a multi-stage digital battle between attackers and defenders in a community. Then, they educated 4 DRL neural networks utilizing reinforcement studying rules, reminiscent of maximizing rewards based mostly on avoiding compromises and lowering community disruption. The workforce’s work has additionally been introduced on the Affiliation for the Development of Synthetic Intelligence in Washington, DC, the place it obtained a substantial amount of reward.
The workforce’s philosophy in creating such a system was first to indicate that efficiently coaching such a DRL structure is feasible. Earlier than diving into subtle constructions, they needed to reveal helpful analysis metrics. The very first thing the researchers did was create an summary simulation surroundings utilizing the Open AI Gymnasium toolkit. The subsequent stage was to make use of this surroundings to develop attacker entities that displayed talent and persistence ranges based mostly on a subset of 15 approaches and 7 techniques from the MITRE ATT&CK framework. The attackers’ goal is to undergo the seven assault chain steps— from the preliminary entry and reconnaissance section to different assault phases till they attain their final objective, which is the influence and exfiltration section.
It’s very important to do not forget that the workforce had no intention of creating a mannequin for blocking an enemy earlier than they might launch an assault contained in the surroundings. Somewhat, they assume that the system has already been compromised. The researchers then used reinforcement studying to coach 4 neural networks. The researchers acknowledged that it’s conceivable to coach such a mannequin with out using reinforcement studying, however it might take a very long time to develop mechanism. However, deep reinforcement studying makes very environment friendly use of this huge search area by imitating some features of human conduct.
Researchers’ efforts to reveal that AI techniques might be efficiently educated on a simulated assault surroundings have proven that an AI mannequin is able to defensive reactions to assaults in real-time. To carefully assess the efficiency of 4 model-free DRL algorithms towards precise, multi-stage assault sequences, the researchers ran a number of experiments. Their analysis confirmed that DRL algorithms is perhaps educated below multi-stage assault profiles with various talent and persistence ranges, producing efficient protection ends in simulated environments.
Take a look at the Paper and Reference Article. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t overlook to hitch our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
Khushboo Gupta is a consulting intern at MarktechPost. She is presently pursuing her B.Tech from the Indian Institute of Know-how(IIT), Goa. She is passionate in regards to the fields of Machine Studying, Pure Language Processing and Internet Improvement. She enjoys studying extra in regards to the technical subject by taking part in a number of challenges.
[ad_2]
Source link
