


[ad_1]
The examine investigates how text-based fashions like LLMs understand and interpret visible info in exploring the intersection of language fashions and visible understanding. The analysis ventures into uncharted territory, probing the extent to which fashions designed for textual content processing can encapsulate and depict visible ideas, a difficult space contemplating the inherent non-visual nature of those fashions.
The core problem addressed by the analysis is assessing the capabilities of LLMs, predominantly skilled on textual knowledge, of their comprehension and illustration of the visible world. Earlier, language fashions don’t course of visible knowledge in picture type. The examine goals to discover the boundaries and competencies of LLMs in producing and recognizing visible ideas, delving into how nicely text-based fashions can navigate the area of visible notion.
Present strategies primarily see LLMs like GPT-4 as powerhouses of textual content technology. Nevertheless, their proficiency in visible idea technology stays an enigma. Previous research have hinted at LLMs’ potential to understand perceptual ideas similar to form and coloration, embedding these facets of their inside representations. These inside representations align, to some extent, with these discovered by devoted imaginative and prescient fashions, suggesting a latent potential for visible understanding inside text-based fashions.
The researchers from MIT CSAIL launched an strategy to evaluate the visible capabilities of LLMs. They adopted a way the place LLMs had been tasked with producing code to visually render photos primarily based on textual descriptions of varied visible ideas. This modern approach successfully circumvents the limitation of LLMs in straight creating pixel-based photos, leveraging their textual processing prowess to delve into visible illustration.
The methodology was complete and multi-faceted. LLMs had been prompted to create executable code from textual descriptions encompassing a variety of visible ideas. This generated code was then used to render photos depicting these ideas, translating textual content to visible illustration. The researchers rigorously examined the LLMs throughout a spectrum of complexities, from primary shapes to advanced scenes, assessing their picture technology and recognition capabilities. The analysis spanned varied visible facets, together with the scenes’ complexity, the idea depiction’s accuracy, and the fashions’ skill to acknowledge these visible representations.
The examine revealed intriguing outcomes about LLMs’ visible understanding capabilities. These fashions demonstrated a outstanding aptitude for producing detailed and complicated graphic scenes. Nevertheless, their efficiency might have been extra uniform throughout all duties. Whereas adept at establishing advanced scenes, LLMs confronted challenges capturing intricate particulars like texture and exact shapes. An fascinating side of the examine was the usage of iterative text-based suggestions, which considerably enhanced the fashions’ capabilities in visible technology. This iterative course of pointed in the direction of an adaptive studying functionality inside LLMs, the place they might refine and enhance visible representations primarily based on steady textual enter.
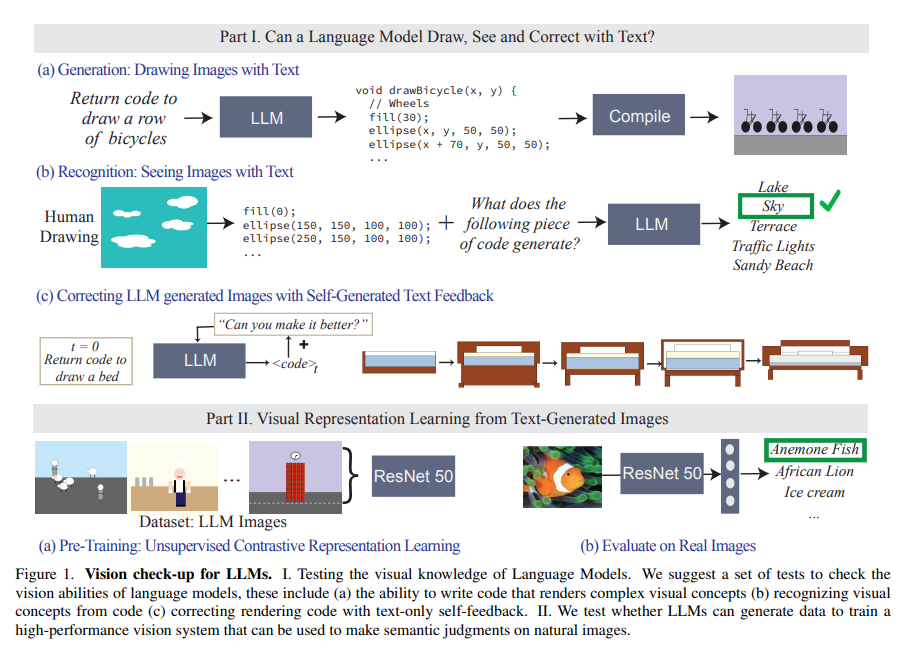
The insights gained from the examine could be summarized as the next:
- LLMs, primarily designed for textual content processing, exhibit a major potential for visible idea understanding.
- The examine breaks new floor in demonstrating how text-based fashions could be tailored to carry out duties historically reserved for imaginative and prescient fashions.
- Textual content-based iterative suggestions emerged as a strong software for enhancing LLMs’ visible technology and recognition capabilities.
- The analysis opens up new prospects for using language fashions in vision-related duties, suggesting the potential of coaching imaginative and prescient methods utilizing purely text-based fashions.
Take a look at the Paper and Project. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter. Be part of our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Hey, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m presently pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m enthusiastic about know-how and wish to create new merchandise that make a distinction.
[ad_2]
Source link
