

[ad_1]
Deciphering Buyer Voices with AI
Delving into Machine Studying, Matter Modeling, and Sentiment Evaluation to Uncover Precious Buyer Views

My associate and I normally expertise a superb postal service. More often than not letters arrive to our house un-opened and delivered in a well timed style. That’s why when our put up didn’t arrive for just a few weeks we thought it was fairly unusual. After some diligent net looking, we found the most probably trigger to this service disruption was strikes. As an information scientist this complete episode obtained me considering…
Is there a option to leverage on-line knowledge to trace some of these incidents?
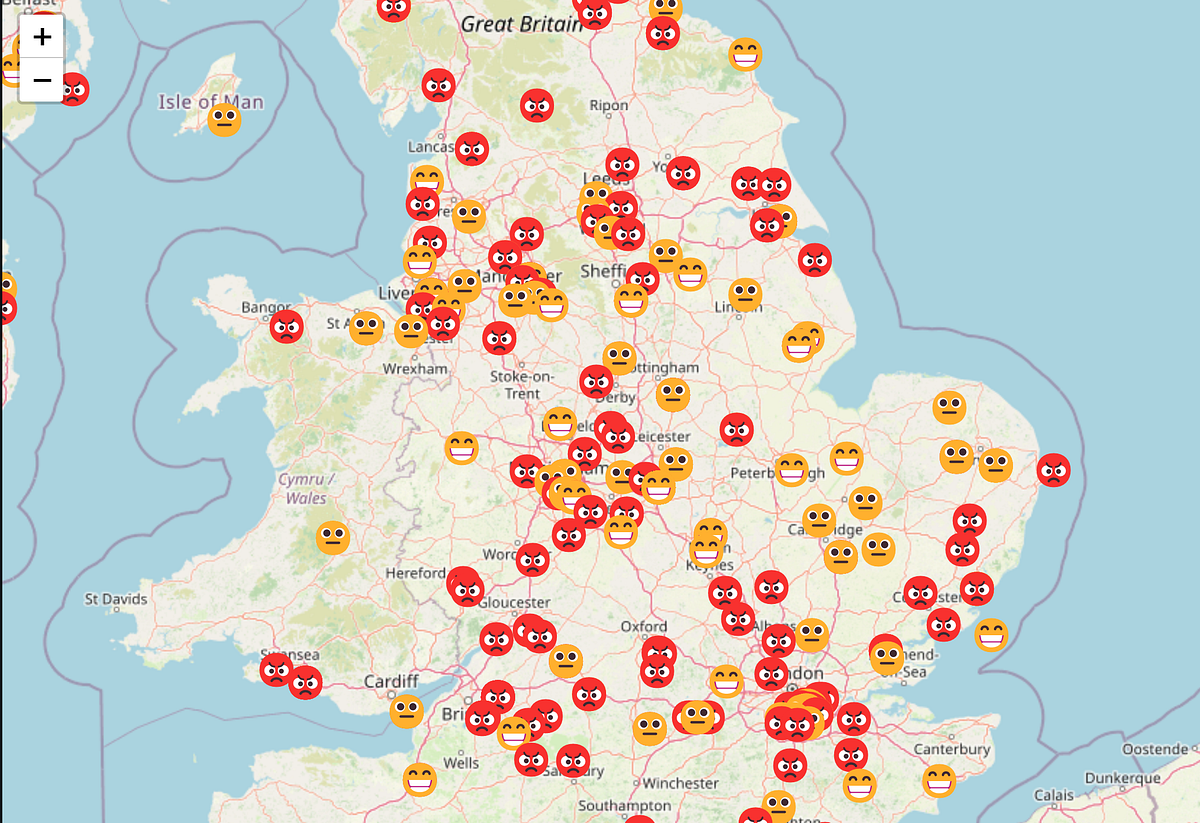
The reply to this query is sure, and I’ve already constructed a prototype which is on the market so that you can play with. I like to recommend doing so earlier than studying on because it offers you a really feel for issues earlier than stepping into the technical particulars.
🌏 Explore the m(app) — That is finest opened on a pc, though it’ll work on a cell phone.
I’ll spend the rest of this write up strolling you thru how I went about answering this query. That is just about an finish to finish machine studying venture exploring elements of software program engineering, social media knowledge mining, matter modelling, transformers, customized loss capabilities, switch studying, and knowledge visualisation. If that sounds fascinating to you in any respect seize a snack or a drink and get snug as a result of this is likely to be fairly an extended one however hopefully definitely worth the learn.
Disclaimer: This text is an unbiased evaluation of tweets containing the #royalmail hashtag and isn’t affiliated with, endorsed, or sponsored by Royal Mail Group Ltd. The opinions and findings expressed inside this text are solely these of the creator and don’t symbolize the views or official positions of Royal Mail Group Ltd or any of its subsidiaries.
When searching for to grasp what individuals suppose, Twitter is all the time an excellent start line. A lot of what individuals put up on Twitter is public and simply accessible via their API. It’s the sort of no holds barred verbal area you’d look forward to finding loads of insights on customer support. I obtained curious and carried out a fast twitter search myself beginning merely with ‘#royalmail’. And voila! a tonne of tweets.
With my knowledge supply recognized, the subsequent factor I did was to determine how I might “mine” points raised from these tweets. Matter modelling got here to thoughts instantly as one thing to strive. I figured that utilizing some sort of clustering on the tweets might reveal some latent matters. I’ll spend the rest of the write up going into some technical particulars. This gained’t be a step-by-step, however moderately a peek over my shoulder and a window into my thought course of in placing this venture collectively.
Improvement setting: I do the vast majority of my ML initiatives in python so my most well-liked IDE is Jupyter labs. I discover it helpful to have the ability to shortly toggle between Jupyter notebooks, python scripts, and the terminal.
File construction: This can be a moderately complicated venture, if I do say so myself. There are a number of processes to think about right here and due to this fact it’s not one thing that would simply be executed from the security of a Jupyter pocket book. Itemizing out all of those we’ve; knowledge extraction, knowledge processing, matter modeling, machine studying, and knowledge visualisation. To assist create some order I normally begin by establishing an acceptable file construction. You possibly can, and possibly ought to leverage bash scripting to do that.
│ README.md
│ setup.py
│ __init__.py
│
├───knowledge
│ ├───01_raw
│ │ tweets_details2023-03-15_20-43-36.csv
│ │
│ ├───02_intermediate
│ ├───03_feature_bank
│ ├───04_model_output
│ └───05_Reports
├───data_processing
│ collect_tweets.py
│ preprocess_tweets_lite.py
│ preprocess_tweets_rm.py
│ __init__.py
│
├───machine_learning
│ customer_trainer.py
│ makemodel.py
│ preprocess_ml.py
│ train_models.py
│ __init__.py
│
├───notebooks
│ HDBSCAN_UMAP_notebook.ipynb
│ Twitter Mannequin Evaluation Pocket book .ipynb
│
└───topic_modeling
bert_umap_topic.py
tfidf.py
twitter_roberta_umap_topic.py
__init__.py
Modularisation: I broke every course of down into modules making it straightforward to re-use, adapt and tweak issues for various use circumstances. Modules additionally assist hold your code ‘clear’. With out the modular strategy I might have ended up with a Jupyter pocket book or python script 1000’s of strains lengthy, very unappealing and troublesome to de-bug.
Model management: With complicated initiatives, you don’t want to lose your progress, overwrite one thing essential, or mess up past restore. GitHub is basically the right answer for this because it makes it exhausting to mess up badly. I get began by making a distant repo and cloning it to my native machine permitting me to sleep straightforward understanding all my exhausting work is backed up. GitHub desk prime permits me to fastidiously observe any adjustments earlier than committing them again to the distant repository.
Packages: I leveraged a tonne of open supply packages, I’ll checklist the important thing ones under and supply hyperlinks.
- Transformers: API for hugging face giant language mannequin.
- Pytorch: Framework for constructing and customising transformers.
- Streamlit: For constructing net purposes.
- Scikit Learn: Framework for machine studying.
- UMAP: Open supply implementation of the UMAP algorithm.
- HDBSCAN: Open supply implementation of the HDSCAN algorithm.
- Folium: For geographic knowledge visualisation.
- CUDA: Parallel computing platform for leveraging the facility of your GPU.
- Seaborn: A library for knowledge visualisation in python.
- Pandas: A library for dealing with structured knowledge.
- Numpy: A library for performing numeric operations in python.
Surroundings administration: Getting access to a wealth of libraries on the web is implausible, however your setting can shortly run away with you. To handle this complexity I prefer to implement upon myself a clear setting coverage at any time when I begin a brand new venture. It’s strictly one setting per venture. I select to make use of Anaconda as my selection of setting supervisor due to the pliability it provides me.
observe: for the needs of this venture I did create separate environments and GitHub repositories for the streamlet net software and the subject modeling.
I used the Twitter API to extract round 30k publicly accessible tweets looking #royalmail. I need to stress right here that solely knowledge that’s publicly accessible could be extracted with the Twitter API assuaging a number of the knowledge privateness issues one could have.
Twitter knowledge is extremely messy and notoriously troublesome to work with for any pure language processing (nlp) duties. It’s social media knowledge loaded with emoji’s, grammatical inconsistencies, particular characters, expletives, URLS, and each different hurdle that comes with free kind textual content. I wrote my very own customized scripts to wash the information for this explicit venture. It was primarily eliminating URLs and annoying cease phrases. I’ve given a snippet for the “lite” model, however I did additionally use a extra heavy responsibility model throughout clustering.
Please observe that that is inside Twitters phrases of service. They permit evaluation, aggregation of publicly accessible knowledge by way of their API. The information is permitted for each non-commercial and commercial use.
The subject modelling strategy I used attracts inspiration from BERT topic¹. I had initially tried Latent Dirichlet Allocation , however struggled to get something coherent. BERT matter was an amazing reference level, however I had observed that it hadn’t explicitly been designed to extract matters from messy Twitter knowledge. Following lots of the similar logical steps as BERT matter, I tailored the strategy just a little bit for the duty.
At a excessive degree BERT matter makes use of the BERT mannequin to generate embeddings, performs dimensionality discount and clustering to disclose latent matters in paperwork.
My strategy leveraged the twitter-xlm-roberta-base² mannequin to generate embeddings. This transformer has been pretrained on twitter knowledge and captures all of the messy nuances, emojis and all. Embeddings, are merely a option to symbolize sentences in numeric kind such that each syntactical and semantical info is preserved. Embeddings are learnt by transformers via self-attention. The superb factor about all of the latest innovation within the giant language mannequin house is that one can leverage state-of-the-art fashions to generate embeddings for one’s personal functions.
I used the UMAP algorithm to venture the tweet embeddings right into a two dimensional house and HDBSCAN to establish clusters. Treating every cluster as a doc, I generated TF-IDF scores to extract a listing of key phrases that roughly ‘outline’ every cluster forming my preliminary matters.
TF-IDF is a useful option to measure a phrase’s significance in a cluster, contemplating how usually it seems in that particular cluster and the way uncommon it’s in a bigger group of clusters. It helps establish phrases which might be distinctive and significant in every cluster.
A few of these dimensionality reductions could be exhausting to make sense of at first. I discovered these assets helpful for serving to me become familiar with the algorithms.
Understanding UMAP — A superb useful resource that helps you visualise and perceive the impression of adjusting hyperparameters.
HDBSCAN Documentation — Essentially the most coherent clarification of HDBSCAN I might discover was offered within the documentation itself.
Lastly, I examined the coherence of the matters generated by scoring the cosine similarity between the matters and the tweets themselves. This sounds moderately formulaic on paper, however I can guarantee you this was no straight ahead process. Unsupervised machine studying of this nature is simply trial and error. It took me dozens of iterations and handbook effort to seek out the proper parameters to get coherent matters out of those tweets. So moderately than going into the specifics of all of the hyperparameters I used, I’ll simply speak in regards to the 4 crucial ones that had been actually a make or break for this strategy.
Distance metrics: for matter modelling the space metric is basically the distinction between forming coherent matters and simply producing a random checklist of phrases. For each UMAP and HDBSCAN I selected cosine distance. The selection right here was a no brainer contemplating my goal, to mannequin matters. Matters are semantically comparable teams of textual content, and the easiest way to measure semantic similarity is cosine distance.
Variety of phrases: after producing the clusters I wished to grasp the “contents” of these clusters via TF-IDF. The important thing metric of selection right here is what number of phrases to return for every cluster. This might vary from one to the variety of distinctive phrases in the entire corpus of textual content. Too many phrases, and your matters turn into incoherent, too few and you find yourself with poor protection of your cluster. Choosing this was a matter of trial and error, after a number of iterations I landed on 4 phrases per matter.
Scoring: Matter modelling isn’t an actual science, so some handbook intervention is required to ensure matters made sense. I might do that for just a few hundred or perhaps a few thousand tweets, however tens of 1000’s? That’s not virtually possible. So I used a numeric “hack” by scoring the cosine similarity between the TFIDF matters generated and the tweets themselves. Once more this was a number of trial and error however after a number of iterations I discovered an acceptable minimize off for cosine similarity to be round 0.9. This left me with round 3k from the unique 30k that had been pretty nicely categorised. Most significantly, it was a big sufficient pattern measurement to do some supervised machine studying.
Matters in 2nd: UMAP offers a handy option to visualise the matters. What we will see is that there’s a mass of matters within the centre which have been clustered along with some smaller area of interest matters on the sting. It truly jogs my memory a little bit of a galaxy. After performing some detective work (handbook trawling via spreadsheets) I discovered this to make sense. The mass of matters within the centre are primarily round customer support, usually complaints. What I assumed was significantly fascinating was the mannequin’s potential to really isolate very area of interest areas. These included politics, economics, employment, and philately (which isn’t some minor movie star, however the assortment of stamps!). In fact, matters returned by TFIDF had been no the place close to this coherent, however I used to be in a position to establish 6 nicely categorised matters from the evaluation. My closing 6 matters had been customer support, politics, royal reply, jobs, monetary information, and philately.
Listing of 4 phrases matters generated by TF-IDF on the clusters and taking the 0.9+ cosine similarity to tweets.
- apprenticeship, jinglejobs, job, label: Jobs
- largest, boss, revolt, yr: Politics
- delivery, reply, royalletters, royalreply: Royal Reply
- accumulating, pack, philatelist, philately: Philately
- declares, plc, place, brief: Monetary Information
- definitive, philatelist, philately, presentation: Philately
- driving, infoapply, job, workplace: Jobs
- driving, job, sm1jobs, suttonjobs: Jobs
- ftse, rmg, share, inventory: Monetary Information
- germany, royal, royalletter, royalreply: Royal Reply
- gradjobs, graduatescheme, jobsearch, pay attention: Jobs
- labour, libdems, tory, uk: Politics
- letter, mail, service, strike: Buyer Service
- luxembourg, royal, royalletter, royalreply: Royal Reply
- new, revenue, shareholder, world: Monetary Information
- plc, place, diminished, wace: Monetary Information


The subject modelling was fiddly and positively not one thing you need to depend on constantly for producing insights. So far as I’m involved it must be an train that you simply conduct as soon as each few months or so (relying on the constancy of your knowledge), simply in case something new comes up.
Having carried out the arduous process of matter modelling, I had some labels and a good sized knowledge set of slightly below 3k observations for coaching a mannequin. Leveraging a pretrained transformer means not having to coach from scratch, not having to construct my very own structure and harnessing the facility of the mannequin’s present information.
Information Splitting
I proceeded with the usual Practice, Validation, and Check splits with 80% of the observations being allotted to coach. See script under:
Implementing focal loss with a customized coach
Mannequin coaching turned out to be much less straight ahead than I had anticipated, and this wasn’t due to the {hardware} necessities however moderately the information itself. What I used to be coping with was a extremely imbalanced multiclass classification downside. Customer support observations had been a minimum of ten occasions as distinguished within the knowledge set than the subsequent most distinguished class. This triggered the mannequin efficiency to be overwhelmed by the customer support class resulting in low recall and precision for the much less distinguished lessons.
I began with one thing easy initially making use of class weights and cross entropy loss, however this didn’t do the trick. After a fast google search I found that the loss operate focal loss has been used efficiently to unravel class imbalance. Focal loss reshapes the cross entropy loss to “down-weight” the loss assigned to nicely categorised examples³.
The unique paper on focal loss focussed on laptop imaginative and prescient duties the place photos had shallow depth of subject. The picture under is an instance of shallow depth of subject, the foreground is distinguished however the background very low res. Any such excessive imbalance between foreground and background is analogous to the imbalance I needed to take care of to categorise the tweets.
Under I’ve laid out my implementation of focal loss inside a customized coach object.
observe that the category weights (alpha) are exhausting coded. You will want to regulate these if you wish to use this for you personal functions.
Mannequin Coaching
After a little bit of customisation I used to be in a position to match a mannequin (and in underneath 7 minutes because of my GPU and CUDA). Focal loss vs. time provides us some proof that the mannequin was near converging.

Mannequin Efficiency
The mannequin was assessed on the take a look at knowledge set which included 525 randomly chosen labelled examples. The efficiency seems spectacular, with pretty excessive precision and recall throughout all lessons. I might caveat that take a look at efficiency might be optimistic because of the small pattern measurement and there’s prone to be extra variance within the nature of those tweets outdoors of our pattern. Nevertheless, we’re coping with a comparatively slender area (#royalmail) so variance is prone to be narrower than it might be for one thing extra common goal.


To successfully visualize the wealth of data I gathered, I made a decision to create a sentiment map. By using my skilled mannequin, I generated matters for tweets posted between January and March 2023. Moreover, I employed the pretrained twitter-roberta-base-sentiment mannequin from Cardiff NLP to evaluate the sentiment of every tweet. To construct the ultimate net software, I used Streamlit.
The present app serves as a fundamental prototype, however it may be expanded to uncover extra profound insights. I’ll briefly focus on just a few potential extensions under:
- Temporal Filtering: Incorporate a date vary filter, permitting customers to discover tweets inside particular time durations. This may help establish developments and adjustments in sentiment over time.
- Interactive Visualizations: Implement interactive charts and visualizations that allow customers to discover relationships between sentiment, matters, and different components within the dataset.
- Actual-time Information: Join the app to stay Twitter knowledge, enabling real-time evaluation and visualization of sentiment and matters as they emerge.
- Superior Filtering: Present extra superior filtering choices, akin to filtering by person, hashtag, or key phrase, to permit for extra focused evaluation of particular conversations and developments.
By extending the app with these options, you may present customers with a extra highly effective and insightful device for exploring and understanding sentiment and matters in tweets.
Thanks for studying!
[1]Grootendorst, M. (2022). BERTopic: Neural matter modeling with a class-based TF-IDF process. Paperswithcode.com. https://paperswithcode.com/paper/bertopic-neural-topic-modeling-with-a-class
[2]Barbieri, F., Anke, L. E., & Camacho-Collados, J. (2022). XLM-T: Multilingual Language Fashions in Twitter for Sentiment Evaluation and Past. Paperswithcode.com. https://arxiv.org/abs/2104.12250
[3]Lin, T.-Y., Goyal, P., Girshick, R., He, Ok. and Greenback, P. (2018). Focal Loss for Dense Object Detection. Fb AI Analysis (FAIR). [online] Accessible at: https://arxiv.org/pdf/1708.02002.pdf [Accessed 21 Mar. 2023].
[ad_2]
Source link
