


[ad_1]

Picture by Editor
In our previous article, we coated quite a lot of approaches to constructing a textual content classification mannequin based mostly on what fashionable NLP presently has to supply.
With old-school TF-IDF approaches, pre-trained embedding fashions, and transformers of assorted sizes and shapes to select from, we wished to offer some sensible recommendation based mostly on our personal expertise. Which fashions are finest fitted to completely different conditions? What are some use instances you could find in your individual line of labor?
So as to add further taste, we need to present you a real-life instance of benchmarks for these completely different approaches and evaluate them utilizing a dataset we selected for this fast follow-up article.
As an example our concepts, we selected The Twitter Financial News, an English-language dataset containing an annotated corpus of finance-related tweets. It’s generally used to construct finance-related content material classification fashions that kind tweets into a lot of subjects.
It’s a medium-sized dataset, which is ideal for us for example how completely different fashions carry out. Additionally pretty various, the dimensions permits us to coach and consider fashions comparatively shortly.
What’s fascinating about this area is that monetary language is often crisp and laconic. There are many correct nouns describing manufacturers, phrases, and associated entities, and the fashions must be taught to differentiate them from frequent nouns with fully completely different meanings. Intuitively, fine-tuning pre-trained generic-language fashions on this area ought to enhance total efficiency and accuracy.
The dataset consists of round 21,000 objects. Not too small, it’s additionally not too massive, making it excellent for displaying off the benefits and downsides of every mannequin and method. Let’s come again to this as soon as we now have the outcomes.
And eventually, the dataset has 20 lessons. It’s no frequent classification activity, the place you must distinguish between a handful of sentiment lessons and emotional tones. There’s an imbalance too. With a 60x+ distinction between essentially the most and least frequent lessons, some approaches might be anticipated to underperform.
Let’s see how completely different fashions will carry out in our benchmarking check.
Primarily based on our earlier article, FastText, BERT, RoBERTa (with second-stage tuning), and GPT-3 are our selections for assessing their efficiency and effectivity. The dataset was cut up into coaching and check units with 16,500 and 4500 objects, respectively. After the fashions have been skilled on the previous, their efficiency and effectivity (inference time) have been measured on the latter.
To coach a FastText mannequin, we used the fastText library with the corresponding command line device. We ready the dataset by inserting labels into texts with the correct prefix, ran the fasttext supervised command to coach a classifier, and waited a pair minutes to supply the mannequin on a CPU-only machine. The subsequent command, fasttext predict, gave us predictions for the check set and mannequin efficiency.
As for transformers, we selected three barely completely different fashions to check: BERT (extra formal, best-base-uncased), RoBERTa-large, and an tailored model of the latter tuned for sentiment classification on a pair finance-related datasets (test it out on the HuggingFace website). The transformers library stood in for our experiments, although it entails writing some code to really run coaching and analysis procedures. A single machine with the A100 GPU dealt with coaching, which took 20–28 minutes till early stopping circumstances have been met for every mannequin. The skilled fashions have been saved in a MLFlow registry.
To coach a classifier based mostly on the GPT-3 mannequin, we referred to the official documentation on the OpenAI web site and used the corresponding command line device to submit knowledge for coaching, monitor its progress, and make predictions for the check set (extra formally, completions, a greater time period for generative fashions). For the reason that work itself occurred on OpenAI’s servers, we didn’t use any specific {hardware}. It solely took an everyday laptop computer to create a cloud-based mannequin. We skilled two GPT-3 variations, Ada and Babbage, to see if they might carry out in a different way. It takes 40–50 minutes to coach a classifier in our state of affairs.
As soon as coaching was full, we evaluated all of the fashions on the check set to construct classification metrics. We selected macro common F1 and weighted common F1 to check them, as that permit us estimate each precision and recall along with seeing if dataset imbalance influenced the metrics. The fashions have been in contrast on their inference pace in milliseconds per merchandise with a batch measurement of 1. For the RoBERTa mannequin, we additionally embody an ONNX-optimized model in addition to inference utilizing an A100 GPU accelerator. Measuring the typical response time from our tuned Babbage mannequin gave us the GPT-3 pace (be aware that OpenAI applies some price limiters, so the precise pace is likely to be decrease or increased relying in your phrases of use).
How did the coaching work out? We organized the leads to a pair tables to indicate you the top product and the impact we noticed.
Photograph by Writer
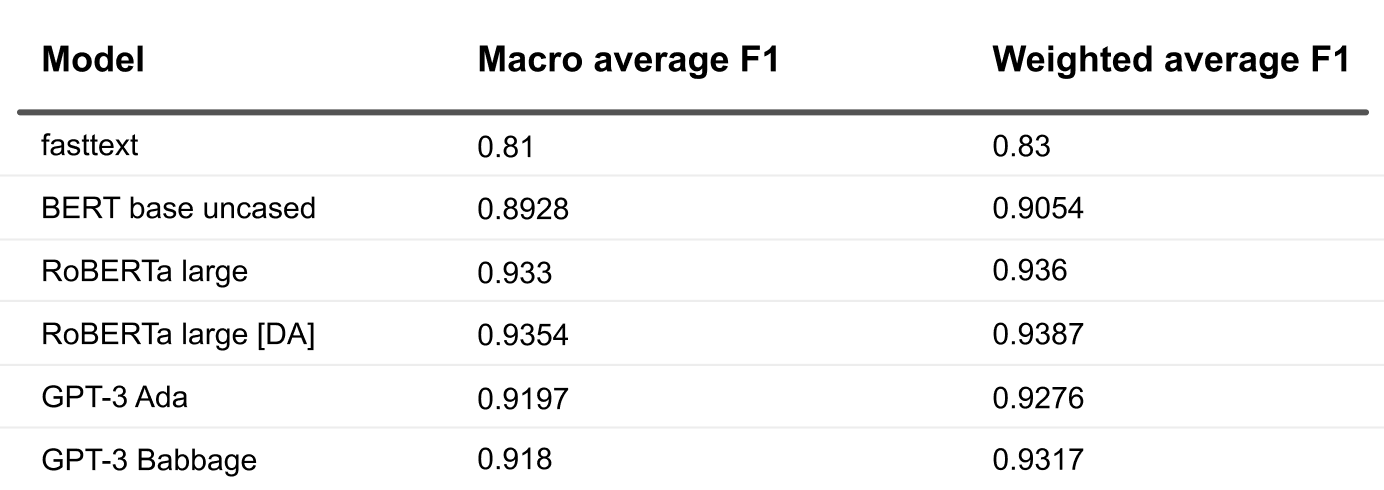
What caught our eye first is that fasttext lagged far behind. With that stated, it took minimal assets by way of computation, time, and coaching, and it gave us a low bar benchmark.
How concerning the transformers? As anticipated, RoBERTa delivered higher outcomes than BERT, which is simple to attribute to the dimensions benefit it had. It’s additionally typically higher with domain-specific classification duties. To be truthful, we particularly chosen a big RoBERTa structure for this comparability, and the bottom RoBERTa mannequin might need carried out equally to BERT regardless of variations within the underlying corpus and coaching methodology.
The tangible hole between the F1 metrics for BERT and RoBERTa might even have been brought on by the truth that we’re coping with a pretty big variety of lessons. The dataset has imbalances that bigger fashions are inclined to seize higher. However that’s simply our suspicion and proving it will require extra experimentation. You too can see that the domain-pretrained RoBERTa supplied a tiny accuracy enhance, although it’s insignificant. It’s laborious to say if the pre-trained domain-tuned mannequin was truly worthwhile for our experiment.
Subsequent comes GPT-3. We chosen the Ada and Babbage fashions for a good comparability with BERT and RoBERTa-large since they’ve glorious parameter sizes that develop progressively (from 165 million parameters in BERT and 355 million in RoBERTa-large to 2.7 billion in Ada and 6.7 billion in Babbage) and might present whether or not the mannequin measurement actually offers a proportional efficiency enhance. Surprisingly, Ada and Babbage each ship virtually the identical metrics, they usually truly lose to RoBERTa even with out domain-specific pre-training. However there’s a cause for that. Do not forget that GPT-3 API-accessible fashions truly give customers a generative inference interface, so that they attempt to predict a token that might classify every instance within the classification activity. RoBERTa and different fashions from transformers, however, have the final layers of their structure configured accurately for classification. Think about a correct logit or softmax on the finish that returns the chance of all of the lessons for any knowledge merchandise you go to it. Whereas the large GPT-3 can be ample to deal with classification for considered one of 20 lessons by producing the best token class, it’s overkill right here. Let’s simply not neglect that the GPT-3 mannequin is fine-tuned and accessed with simply three strains of code, in contrast to RoBERTa, which takes work to roll out in your structure.
Photograph by Writer
Let’s now lastly evaluate the fashions and their inference setups by way of their request execution pace. Since we’re not simply coaching them for efficiency and accuracy, we have to consider how briskly they return us their inference for brand spanking new knowledge. We clocked the net synchronous requests to the fashions and tried to know the perfect area of interest for every.
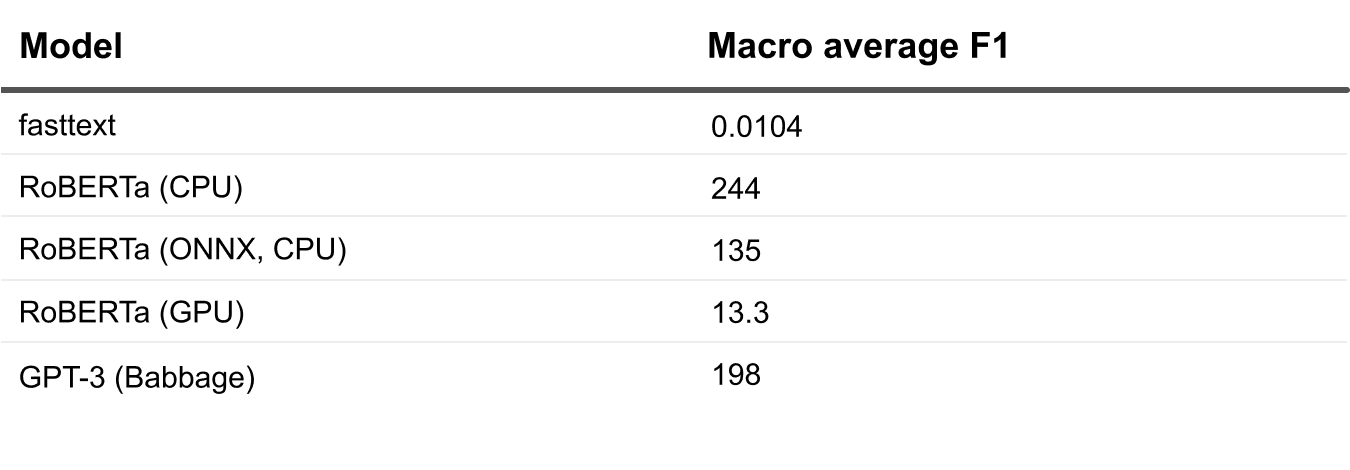
The winner right here is fasttext. Its accuracy, nonetheless, forces us to maintain shifting down the checklist.
Between the RoBERTa and GPT-3 setups, we will see that GPT-3 is comparatively quick regardless of being the most important, particularly on condition that its response time contains two-sided community communication to their API endpoint. The precise inference right here is small. That’s clearly good, particularly since this can be a fairly easy resolution to arrange, fine-tune, and implement mannequin requires. Whereas it may be costly, particularly in case you plan on sending a number of knowledge often, the cost-benefit determination is as much as you.
The GPU-hosted model is the winner among the many RoBERTa setups. The GPUs add an enormous efficiency enhance to inference computations, although internet hosting your mannequin server on GPU machines may value the challenge out of your price range. Rolling out a GPU-based mannequin server will also be difficult, particularly in case you haven’t completed it earlier than.
You additionally must do not forget that regardless of these benchmarks are all being quick by way of returning the outcomes of your mannequin requests, you shouldn’t neglect to do some planning and break down how you intend to make use of the fashions in your challenge. Actual-time inference or asynchronous batch requests? Accessed over the web or inside your native community? Do you’ve got overhead for your corporation logic operations on high of the mannequin response? All that may add way more time overhead to every request over the precise mannequin inference calculation itself.
What have we realized? We tried to show a real-life instance of the stability between the issue of working numerous fashions, their ensuing accuracy metrics, and their response pace when they’re prepared for use. Clearly, determining what to make use of when and the way given your challenge is a problem. However we hope to depart you with some steering?—?there’s no silver bullet on the subject of GPT fashions. All of us should depend our cash as nicely, particularly on the subject of machine studying.
Right here at Toloka, we’re working laborious on a platform that can allow customers to coach, deploy, and use a transformer like RoBERTa with the identical three API calls as GPT-3 API.
In our subsequent article, we’ll run a pair extra experiments on find out how to mitigate the consequences of disbalanced datasets and upsample or downsample lessons for stability. Our suspicion is that the GPT-3 generative method will carry out higher than RoBERTa-large. We’ll additionally focus on how these outcomes may change if we tackle a a lot smaller dataset, and we level out precisely when and the place GPT-3+ fashions will outperform all of the others in classification duties. Keep tuned and take a look at extra of our work over on the Toloka ML staff’s weblog.
Aleksandr Makarov is a senior product supervisor in Toloka.ai main the product growth of Toloka.ai ML platform, a former healthtech entrepreneur and co-founder of Droice Labs
[ad_2]
Source link
