

[ad_1]
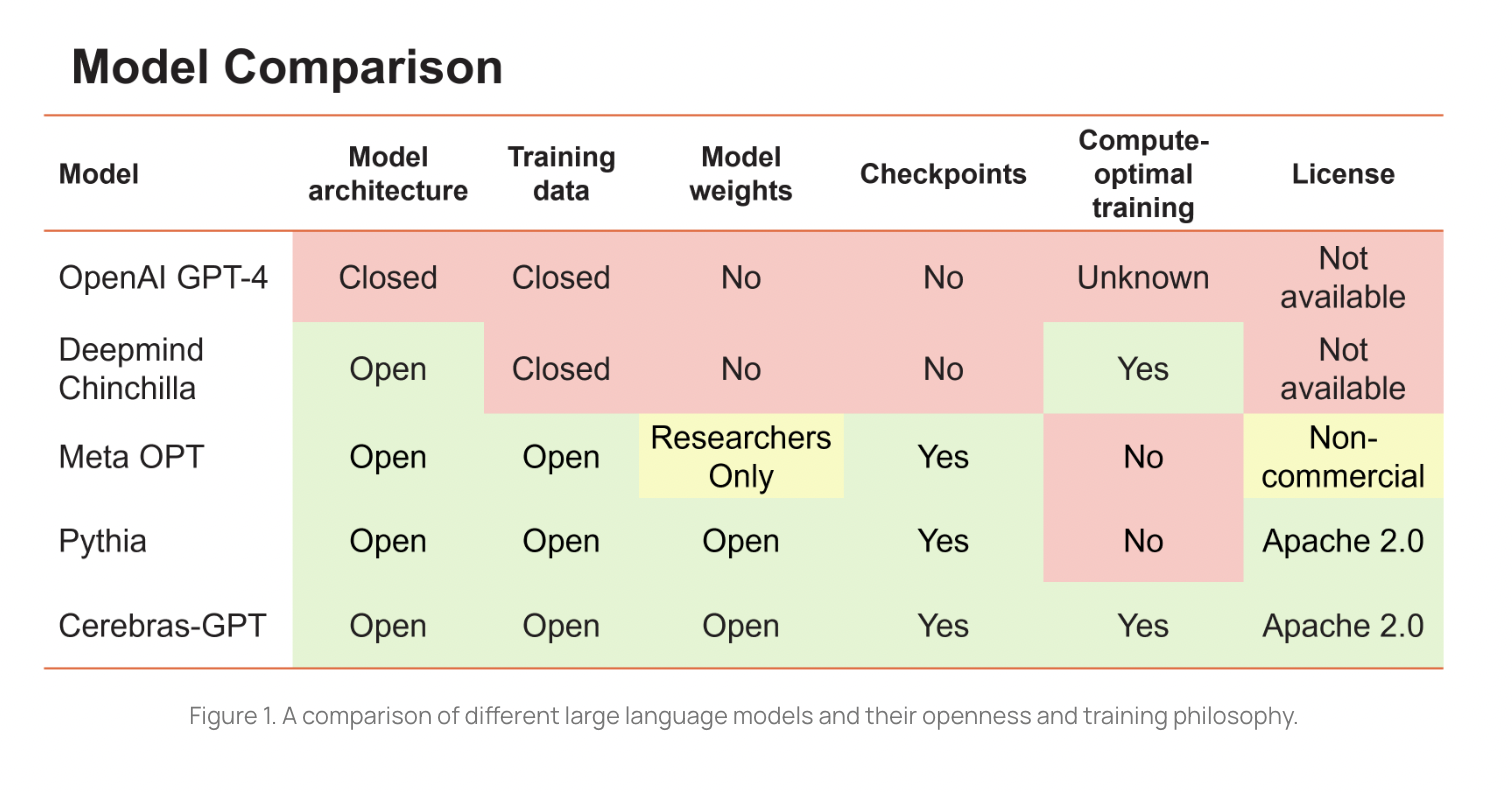
Rising entry boundaries are hindering AI’s potential to revolutionize world commerce. OpenAI’s GPT4 is the latest massive language mannequin to be disclosed. Nonetheless, the mannequin’s structure, coaching information, {hardware}, and hyperparameters are stored secret. Massive fashions are more and more being constructed by companies, with entry to the ensuing fashions restricted to APIs and locked datasets.
Researchers really feel it’s essential to have entry to open, replicable, and royalty-free state-of-the-art fashions for each analysis and business functions for LLMs to be a freely out there know-how. To this aim, scientists have developed a set of transformer fashions, dubbed Cerebras-GPT, utilizing cutting-edge strategies and publicly out there datasets. The Chinchilla components was used to coach these fashions, making them the primary GPT fashions publicly out there beneath the Apache 2.0 license.
Cerebras Techniques Inc., a producer of AI chips, lately revealed that it has educated and launched seven GPT-based massive language fashions for generative AI. Cerebras has introduced that it’s going to present the fashions and their related weights and coaching recipe beneath the open-source Apache 2.0 license. Notable about these new LLMs is that they’re the primary to be educated on the Cerebras Andromeda AI supercluster’s CS-2 techniques, that are pushed by the Cerebras WSE-2 chip and are optimized to execute AI software program. This implies they’re pioneering LLMs which have been educated with out GPU-based applied sciences.
On the subject of big linguistic representations, there are two competing philosophies. Fashions like OpenAI’s GPT-4 and DeepMind’s Chinchilla, which have been educated on proprietary information, belong to the primary class. Sadly, such fashions’ supply code and realized weights are stored secret. The second class comprises open-source fashions that have to be educated in a compute-optimal method, resembling Meta’s OPT and Eleuther’s Pythia.
Cerebras-GPT was created as a companion to Pythia; it shares the identical public Pile dataset and goals to assemble a training-efficient scaling regulation and household of fashions throughout a variety of mannequin sizes. Every of the seven fashions that make up Cerebras-GPT is educated with 20 tokens per parameter and has a measurement of both 111M, 256M, 590M, 1.3B, 2.7B, 6.7B, or 13B. Cerebras-GPT minimizes loss-per-unit-of-computing throughout all mannequin sizes by choosing essentially the most acceptable coaching tokens.
To hold on this line of inquiry, Cerebras-GPT makes use of the publicly out there Pile dataset to develop a scaling regulation. This scaling regulation provides a computationally quick technique for coaching LLMs of arbitrary measurement utilizing Pile. Researchers plan to additional the progress of massive language fashions by publicizing the findings to offer a useful useful resource for the neighborhood.
Cerebras-GPT was examined on varied language-based duties, together with sentence completion and question-and-answer classes, to find out how effectively it carried out. Even when the fashions are competent at comprehending pure language, that proficiency might not carry over to the specialised duties within the pipeline. As proven in Determine 4, Cerebras-GPT maintains state-of-the-art coaching effectivity for many frequent downstream duties. Scaling for downstream pure language duties has but to be reported within the literature, regardless that earlier scaling legal guidelines have demonstrated rising within the pre-training loss.

Cerebras GPT was educated on 16 CS-2 techniques utilizing conventional information parallelism. Cerebras CS-2 gadgets have sufficient reminiscence to function even the biggest fashions on a single machine with out splitting the mannequin, making this viable. Researchers constructed the Cerebras Wafer-Scale Cluster to facilitate easy scaling particularly for the CS-2. Utilizing weight streaming, a HW/SW co-designed execution approach, mannequin measurement, and cluster measurement may be scaled independently with out the necessity for mannequin parallelism. Growing the cluster measurement is as simple as modifying a configuration file with this design.
The Andromeda cluster, a 16x Cerebras Wafer-Scale Cluster, was used to coach all Cerebras-GPT fashions. The cluster made it doable to run all trials quick, eliminating the requirement for time-consuming steps like distributed techniques engineering and mannequin parallel tuning usually required on GPU clusters. Most significantly, it freed up teachers to focus on ML design slightly than distributed system structure. The Cerebras AI Mannequin Studio offers entry to the Cerebras Wafer-Scale Cluster within the cloud as a result of researchers take into account the capability to simply practice massive fashions as a major enabler for the overall neighborhood.
As a result of so few firms have the sources to coach genuinely large-scale fashions in-house, the discharge is important, in accordance with Cerebras co-founder and Chief Software program Architect Sean Lie. Typically requiring tons of or hundreds of GPUs, “releasing seven absolutely educated GPT fashions into the open-source neighborhood illustrates precisely how environment friendly clusters of Cerebras CS-2 techniques may be,” he acknowledged.
A full suite of GPT fashions educated utilizing cutting-edge effectivity strategies, the enterprise claims, has by no means earlier than been made publicly out there. It was acknowledged that in comparison with different LLMs, they require much less time to coach, are cheaper, and devour much less power.
The corporate stated that the Cerebras LLMs are appropriate for tutorial and enterprise functions due to their open-source nature. Additionally they have a number of benefits, resembling their coaching weights producing a particularly correct pre-trained mannequin that may be tuned for various duties with comparatively little further information, making it doable for anybody to create a strong, generative AI software with little in the way in which of programming information.
Conventional LLM coaching on GPUs necessitates a sophisticated mashup of pipeline, mannequin, and information parallelism strategies; this launch reveals {that a} “easy, data-parallel solely strategy to coaching” may be simply as efficient. Cerebras, alternatively, demonstrates how this can be achieved with a less complicated, data-parallel-only mannequin that doesn’t necessitate any modifications to the unique code or mannequin to scale to very massive datasets.
Coaching state-of-the-art language fashions is extremely troublesome because it requires lots of sources, together with a big computing finances, advanced distributed computing strategies, and intensive ML information. Thus, just some establishments develop in-house LLMs (massive language fashions). Even up to now few months, there was a notable shift towards not open-sourcing the outcomes by these with the mandatory sources and expertise. Researchers at Cerebras are dedicated to selling open entry to state-of-the-art fashions. In gentle of this, the Cerebras-GPT mannequin household, consisting of seven fashions with wherever from 111 million to 13 billion parameters, has now been launched to the open-source neighborhood. The Chinchilla-trained fashions obtain the utmost accuracy inside a specified computational finances. In comparison with publicly out there fashions, Cerebras-GPT trains extra shortly, prices much less, and makes use of much less power general.
Try the Cerebras Blog. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t overlook to affix our 17k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
Dhanshree Shenwai is a Pc Science Engineer and has expertise in FinTech firms protecting Monetary, Playing cards & Funds and Banking area with eager curiosity in functions of AI. She is keen about exploring new applied sciences and developments in right this moment’s evolving world making everybody’s life simple.
[ad_2]
Source link
