


[ad_1]

Picture by Creator
Just lately we’ve all been having a brilliant onerous time catching up on the newest releases within the LLM area. In the previous few weeks, a number of open-source ChatGPT options have turn out to be standard.
And on this article we’ll study concerning the ChatGLM sequence and ChatGLM-6B, an open-source and light-weight ChatGPT different.
Let’s get going!
Researchers on the Tsinghua College in China have labored on creating the ChatGLM sequence of fashions which have comparable efficiency to different fashions resembling GPT-3 and BLOOM.
ChatGLM is a bilingual massive language mannequin educated on each Chinese language and English. At present, the next fashions can be found:
- ChatGLM-130B: an open-source LLM
- ChatGLM-100B: not open-sourced, however out there by way of invite-only entry
- ChatGLM-6B: a light-weight open-source different
Although these fashions could seem much like the Generative Pretrained Transformer (GPT) group of enormous language fashions, the Basic Language Mannequin (GLM) pretraining framework is what makes them completely different. We’ll study extra about this within the subsequent part.
In machine studying, you’d know GLMs as generalized linear fashions, however the GLM in ChatGLM stands for Basic Language Mannequin.
GLM Pretraining Framework
LLM pre coaching has been extensively studied and remains to be an space of energetic analysis. Let’s attempt to perceive the important thing variations between GLM pretraining and GPT-style fashions.
The GPT-3 household of fashions use decoder-only auto regressive language modeling. In GLM, alternatively, optimization of the target is formulated as an auto regressive clean infilling downside.
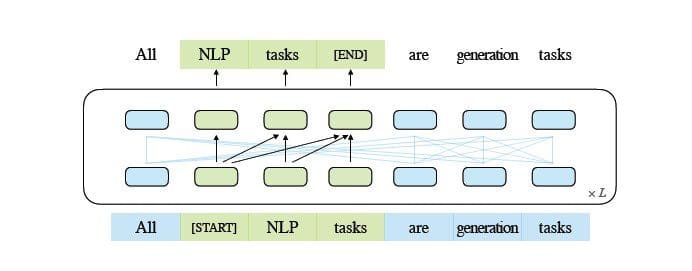
GLM | Image Source
In easy phrases, auto regressive clean infilling entails blanking out a steady span of textual content, after which sequentially reconstructing the textual content this blanking. Along with shorter masks, there’s a longer masks that randomly removes lengthy blanks of textual content from the top of sentences. That is finished in order that the mannequin performs fairly nicely in pure language understanding in addition to technology duties.
One other distinction is in the kind of consideration used. The GPT group of enormous language fashions use unidirectional consideration, whereas the GLM group of LLMs use bidirectional consideration. Utilizing bidirectional consideration over unmasked contexts can seize dependencies higher and may enhance efficiency on pure language understanding duties.
GELU Activation
In GLM, GELU (Gaussian Error Linear Models) activation is used as an alternative of the ReLU activation [1].
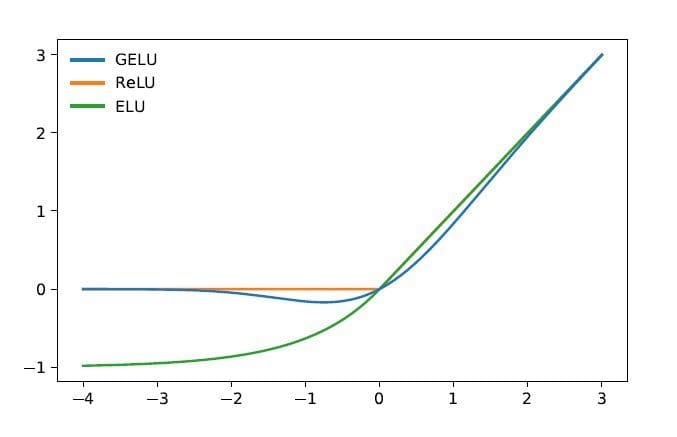
GELU, ReLU, and ELU Activations | Image Source
The GELU activation and has non-zero values for all inputs and has the next type [3]:
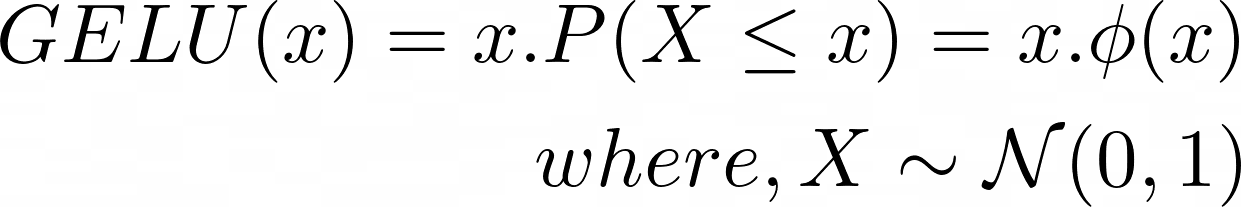
The GELU activation is discovered to enhance efficiency in as in comparison with ReLU activations, although computationally extra intensive than ReLU.
Within the GLM sequence of LLMs, ChatGLM-130B which is open-source and performs in addition to GPT-3’s Da-Vinci mannequin. As talked about, as of writing this text, there is a ChatGLM-100B model, which is restricted to invite-only entry.
ChatGLM-6B
The next particulars about ChatGLM-6B to make it extra accessible to finish customers:
- Has about 6.2 billion parameters.
- The mannequin is pre-trained on 1 trillion tokens—equally from English and Chinese language.
- Subsequently, methods resembling supervised fine-tuning and reinforcement studying with human suggestions are used.
Let’s wrap up our dialogue by going over ChatGLM’s benefits and limitations:
Benefits
From being a bilingual mannequin to an open-source mannequin which you could run domestically, ChatGLM-6B has the next benefits:
- Most mainstream massive language fashions are educated on massive corpora of English textual content, and enormous language fashions for different languages aren’t as widespread. The ChatGLM sequence of LLMs are bilingual and a fantastic alternative for Chinese language. The mannequin has good efficiency in each English and Chinese language.
- ChatGLM-6B is optimized for consumer gadgets. Finish customers usually have restricted computing sources on their gadgets, so it turns into nearly not possible to run LLMs domestically—with out entry to high-performance GPUs. With INT4 quantization, ChatGLM-6B can run with a modest reminiscence requirement of as little as 6GB.
- Performs nicely on quite a lot of duties together with summarization and single and multi-query chats.
- Regardless of the considerably smaller variety of parameters as in comparison with different mainstream LLMs, ChatGLM-6B helps context size of as much as 2048.
Limitations
Subsequent, let’s checklist a couple of limitations of ChatGLM-6B:
- Although ChatGLM is a bilingual mannequin, its efficiency in English is probably going suboptimal. This may be attributed to the directions utilized in coaching principally being in Chinese language.
- As a result of ChatGLM-6B has considerably fewer parameters as in comparison with different LLMs resembling BLOOM, GPT-3, and ChatGLM-130B, the efficiency could also be worse when the context is simply too lengthy. Consequently, ChatGLM-6B might give inaccurate info extra usually than fashions with a bigger variety of parameters.
- Small language fashions have restricted reminiscence capability. Due to this fact, in multi-turn chats, the efficiency of the mannequin might degrade barely.
- Bias, misinformation, and toxicity are limitations of all LLMs, and ChatGLM is inclined to those, too.
As a subsequent step, run ChatGLM-6B domestically or check out the demo on HuggingFace areas. If you happen to’d wish to delve deeper into the working of LLMs, here is an inventory of free courses on large language models.
[1] Z Du, Y Qian et al., GLM: General Language Model Pretraining with Autoregressive Blank Infilling, ACL 2022
[2] A Zheng, X Liu et al., GLM-130B – An Open Bilingual Pretrained Model, ICML 2023
[3] D Hendryks, Okay Gimpel, Gaussian Error Linear Units (GELUs), arXiv, 2016
[4] ChatGLM-6B: Demo on HuggingFace Spaces
[5] GitHub Repo
Bala Priya C is a technical author who enjoys creating long-form content material. Her areas of curiosity embrace math, programming, and knowledge science. She shares her studying with the developer group by authoring tutorials, how-to guides, and extra.
[ad_2]
Source link
