

[ad_1]
Giant Language Fashions (LLMs) have emerged as sport changers within the pure language processing area. They’re changing into a key a part of our each day lives. Essentially the most well-known instance of an LLM is ChatGPT, and it’s secure to imagine nearly all people is aware of about it at this level, and most of us use it each day.
LLMs are characterised by their big measurement and capability to be taught from huge quantities of textual content information. This permits them to generate coherent and contextually related human-like textual content. These fashions are constructed based mostly on deep studying architectures, similar to GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers), which makes use of consideration mechanisms to seize long-range dependencies in a language.
By leveraging pre-training on large-scale datasets and fine-tuning on particular duties, LLMs have proven exceptional efficiency in numerous language-related duties, together with textual content technology, sentiment evaluation, machine translation, and question-answering. As LLMs proceed to enhance, they maintain immense potential to revolutionize pure language understanding and technology, bridging the hole between machines and human-like language processing.
Then again, some individuals thought LLMs weren’t utilizing their full potential as they’re restricted to textual content enter solely. They’ve been engaged on extending the potential of LLMs past language. A number of the research have efficiently built-in LLMs with numerous enter alerts, similar to pictures, movies, speech, and audio, to construct highly effective multi-modal chatbots.
Although, there’s nonetheless a protracted technique to go right here as most of those fashions lack the understanding of the relationships between visible objects and different modalities. Whereas visually-enhanced LLMs can generate high-quality descriptions, they achieve this in a black-box method with out explicitly referring to the visible context.
Establishing an express and informative correspondence between textual content and different modalities in multi-modal LLMs can improve consumer expertise and allow a brand new set of functions for these fashions. Allow us to meet with BuboGPT, which tackles this limitation.
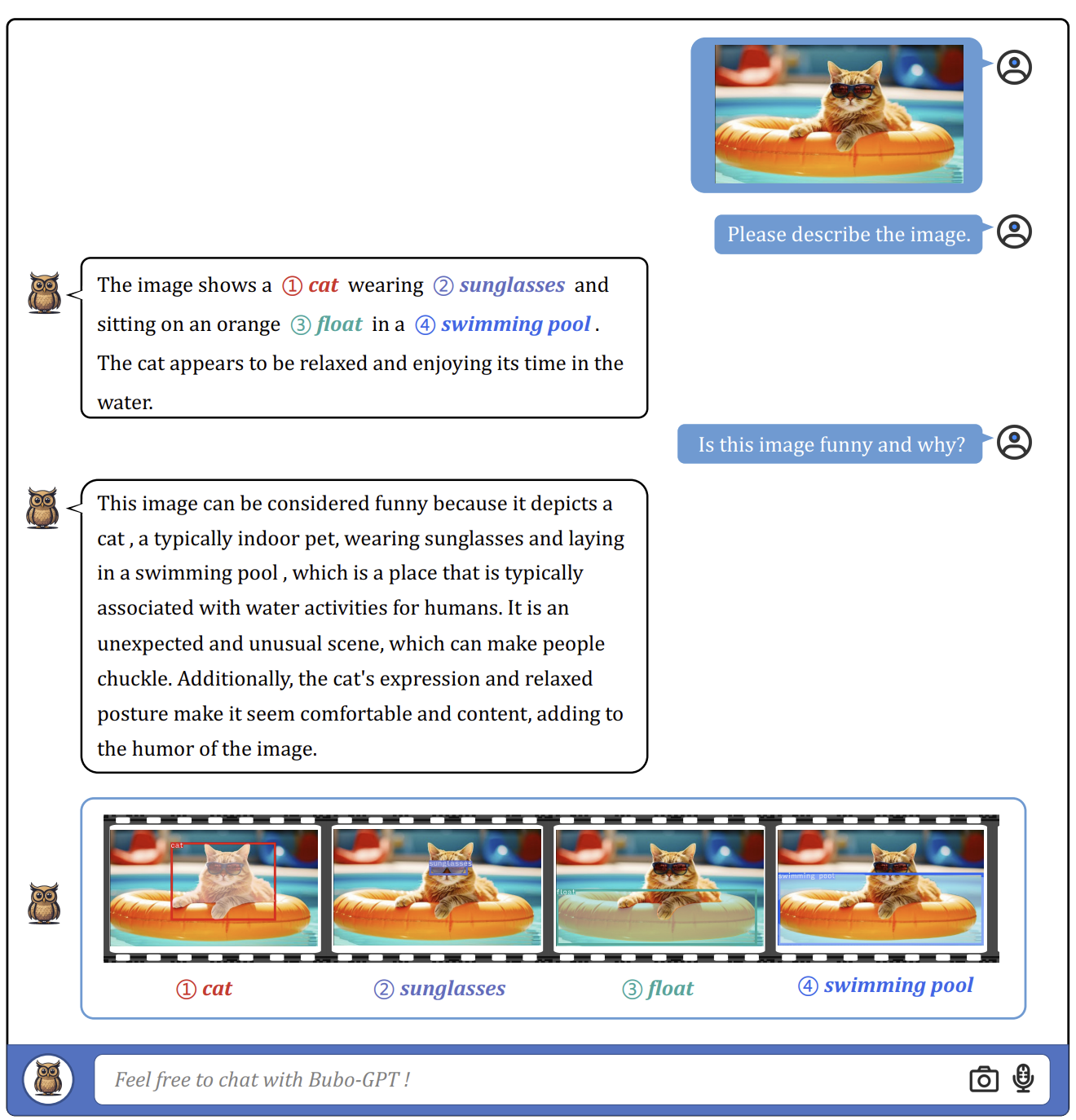
BuboGPT is the primary try to include visible grounding into LLMs by connecting visible objects with different modalities. BuboGPT allows joint multi-modal understanding and chatting for textual content, imaginative and prescient, and audio by studying a shared illustration area that aligns effectively with pre-trained LLMs.
Visible grounding is just not a straightforward job to attain, in order that performs an important half in BuboGPT’s pipeline. To attain this, BuboGPT builds a pipeline based mostly on a self-attention mechanism. This mechanism establishes fine-grained relations between visible objects and modalities.
The pipeline contains three modules: a tagging module, a grounding module, and an entity-matching module. The tagging module generates related textual content tags/labels for the enter picture, the grounding module localizes semantic masks or containers for every tag, and the entity-matching module makes use of LLM reasoning to retrieve matched entities from the tags and picture descriptions. By connecting visible objects and different modalities via language, BuboGPT enhances the understanding of multi-modal inputs.
To allow a multi-modal understanding of arbitrary mixtures of inputs, BuboGPT employs a two-stage coaching scheme just like Mini-GPT4. Within the first stage, it makes use of ImageBind because the audio encoder, BLIP-2 because the imaginative and prescient encoder, and Vicuna because the LLM to be taught a Q-former that aligns imaginative and prescient or audio options with language. Within the second stage, it performs multi-modal instruct tuning on a high-quality instruction-following dataset.
The development of this dataset is essential for the LLM to acknowledge offered modalities and whether or not the inputs are well-matched. Subsequently, BuboGPT builds a novel high-quality dataset with subsets for imaginative and prescient instruction, audio instruction, sound localization with constructive image-audio pairs, and image-audio captioning with destructive pairs for semantic reasoning. By introducing destructive image-audio pairs, BuboGPT learns higher multi-modal alignment and displays stronger joint understanding capabilities.
Take a look at the Paper, Github, and Project. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t neglect to affix our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
Ekrem Çetinkaya obtained his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin College, Istanbul, Türkiye. He wrote his M.Sc. thesis about picture denoising utilizing deep convolutional networks. He obtained his Ph.D. diploma in 2023 from the College of Klagenfurt, Austria, together with his dissertation titled “Video Coding Enhancements for HTTP Adaptive Streaming Utilizing Machine Studying.” His analysis pursuits embrace deep studying, laptop imaginative and prescient, video encoding, and multimedia networking.
[ad_2]
Source link
