

[ad_1]
By Sinequa
What can we need to obtain?
We need to classify texts into predefined classes which is a quite common activity in NLP. For a few years, the classical method for easy paperwork was to generate options utilizing TF-IDF and mix it with logistic regression. Previously we used to depend on this stack at Sinequa for textual classification, and, spoiler alert, with the mannequin offered right here we now have overwhelmed our baseline from 5% to 30% for very noisy and lengthy paperwork datasets. This former method had two most important points: the characteristic sparsity that we tackled by way of compression methods and the word-matching situation that we tamed leveraging Sinequa’s highly effective linguistic capacities (primarily by way of our homegrown tokenizer).
In a while, the pandora field of language fashions (pre-trained on humongous corpora in an unsupervised trend and fine-tuned on downstream supervised duties) was opened and TF-IDF primarily based methods weren’t cutting-edge anymore. Such language fashions could possibly be word2vec mixed with LSTMs or CNNs, ELMo, and most significantly the Transformer (in 2017: https://arxiv.org/pdf/1706.03762.pdf).
BERT is a Transformer primarily based language mannequin that has gained lots of momentum within the final couple of years because it beat all NLP baselines by far and got here as a pure option to construct our textual content classification.
What’s the problem then?
Transformer primarily based language fashions akin to BERT are actually good at understanding the semantic context (the place bag-of-words methods fail) as a result of they have been designed particularly for that function. As defined within the introduction, BERT outperforms all NLP baselines, however as we are saying within the scientific neighborhood, “no free lunch”. This in depth semantic comprehension of a mannequin like BERT gives comes with a giant caveat: it can’t take care of very lengthy textual content sequences. Mainly, this limitation is 512 tokens (a token being a phrase or a subword of the textual content) which characterize kind of two or three Wikipedia paragraphs and we clearly don’t need to contemplate solely such a small sub-part of a textual content to categorise it.
As an instance this, let’s contemplate the duty of classifying complete product critiques into constructive or unfavorable critiques. The primary sentences or paragraphs could solely comprise an outline of the product and it could possible require to go additional down the assessment to know whether or not the reviewer truly likes the product or not. If our mannequin doesn’t embody the entire content material, it won’t be potential to make the correct prediction. Subsequently, one requirement for our mannequin is to seize the context of a doc whereas managing appropriately long-time dependencies between the sentences in the beginning and the top of the doc.
Technically talking, the core limitation is the reminiscence footprint that grows quadratically with the variety of tokens together with using pre-trained fashions that include a set dimension decided by Google (& al.). That is anticipated since every token is “attentive” [https://arxiv.org/pdf/1706.03762.pdf] to each different token and due to this fact requires a [N x N] consideration matrix, with [N] the variety of tokens. For instance, BERT accepts a most of 512 tokens which hardly qualifies as lengthy textual content. And going past 512 tokens quickly reaches the boundaries of even trendy GPUs.
One other downside that arises utilizing Transformers in a manufacturing atmosphere is the very gradual inference because of the dimension of the fashions (110M parameters for BERT base) and, once more, the quadratic value. So, our purpose shouldn’t be solely to seek out an structure that matches into reminiscence throughout the coaching however to seek out one which additionally responds fairly quick throughout inference.
The final problem we handle right here is to construct a mannequin primarily based on varied characteristic varieties: lengthy textual content in fact, but additionally further textual metadata (akin to title, summary …) and classes (location, authors …).
So, the best way to take care of actually lengthy paperwork?
The principle thought is to separate the doc into shorter sequences and feed these sequences right into a BERT mannequin. We get hold of the CLS embedding for every sequence and merge the embeddings. There are a few prospects to carry out the merge, we experimented with:
- Convolutional Neural Networks (CNN)
- Lengthy Brief-Time period Reminiscence Networks (LSTM)
- Transformers (to combination Transformers, sure 🙂 )
Our experiments on totally different normal textual content classification corpora confirmed that utilizing further Transformer layers to merge the produced embeddings works finest with out introducing a big computational value.
Need the formal description, proper?
We contemplate a textual content classification activity with L labels. For a doc D, its tokens given by the WordPiece tokenization will be written X =( x₁, …, xₙ) with N the whole variety of token in D. Let Okay be the maximal sequence size (as much as 512 for BERT). Let I be the variety of sequences of Okay tokens or much less in D, it’s given by I=⌊ N/Okay ⌋.
Observe that if the final sequence within the doc has a dimension decrease to Okay it will likely be padded with 0 till the Kᵗʰ index. Then if sⁱ with i∈ {1, .., I}, is the i-th sequence with Okay parts in D, we now have:
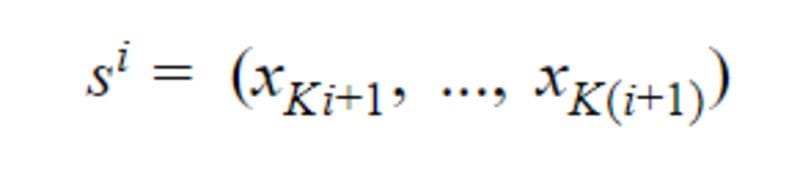
We will word that
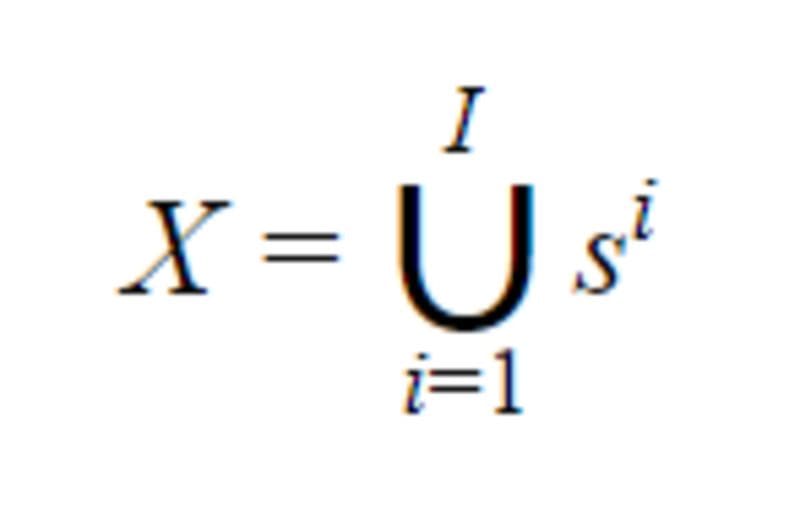
BERT returns the CLS embedding but additionally an embedding per token.
Let outline the embeddings per token returned by BERT for the i-th sequence of the doc akin to:
the place CLS is the embedding of the particular token inserted in entrance of every textual content sequence fed to BERT, it’s usually thought-about as an embedding summarizing the complete sequence.
To mix the sequences, we solely use CLSᵢ and don’t use y. We use t transformers T₁, …,Tₜ to acquire the ultimate vector to feed to the final dense layer of the community:
the place ∘ is the perform composition operation.
Given the final dense layer weights W ∈ ℝᴸˣᴴ the place H is the hidden dimension of the transformer and bias b ∈ ℝᴸ
The possibilities P ∈ ℝᴸ are given by:
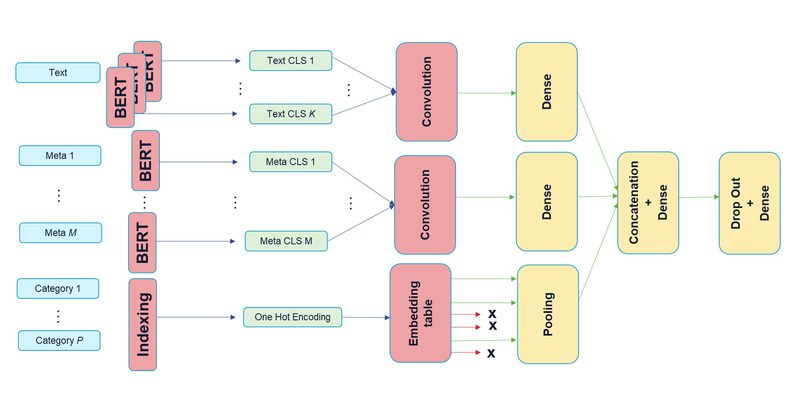
Lastly, making use of argmax on the vector P returns the expected label. For a abstract of the above structure, you’ll be able to take a look at determine 1.
The structure above allows us to leverage BERT for the textual content classification activity bypassing the utmost sequence size limitation of transformers whereas on the similar time protecting the context over a number of sequences. Let’s see the best way to mix it with different sorts of options.
Learn how to take care of metadata?
Oftentimes, a doc comes with extra than simply its content material. There will be metadata that we divide into two teams, textual metadata, and categorical metadata.
Textual Metadata
By textual metadata, we imply quick textual content that has (after tokenization) a comparatively small variety of tokens. That is required to suit completely into our language mannequin. A typical instance of such metadata can be titles or abstracts.
Given a doc with M metadata annotation. Let
be the CLS embeddings produced by BERT for every metadata. The identical method as above is used to get the likelihood vector as:
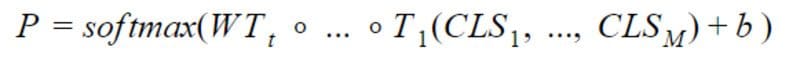
Categorical Metadata
Categorical metadata could be a numerical or textual worth that represents a class. Numerical values will be the variety of pages whereas textual values will be the writer identify or a geo-location.
A standard method to take care of such options is to implement the Wide and Deep architecture. Our experiments confirmed that outcomes yielded by the deep a part of this community have been sufficiently good and the huge half was not required.
We encode the explicit metadata in a single cross-category vector utilizing one-hot encoding. This encoding is then handed into an embedding layer that learns a vector illustration for every distinct class. The final step is to use a pooling layer on the ensuing embedding matrix.
We thought-about max, common and min pooling and located that utilizing common pooling labored finest for our take a look at corpora.
How does the entire structure look?
Hope you caught round till now, the next determine will hopefully make issues loads clearer.
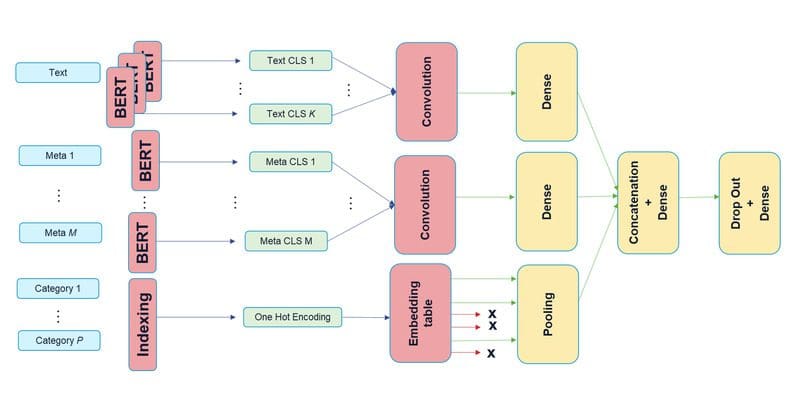
Determine 1
There are three sub-models, one for textual content, one other for textual metadata, and the final one for categorical metadata. The output of the three sub-models is merely concatenated right into a single vector earlier than passing it by way of a dropout layer and eventually into the final dense layer with a softmax activation for the classification.
You in all probability have observed that there are a number of BERT cases depicted within the structure, not just for the textual content enter but additionally for the textual metadata. As BERT comes with many parameters to coach, we determined to not embody a separate BERT mannequin per sub-model, however as an alternative share the weights of a single mannequin in between the sub-models. Sharing weights definitely reduces the RAM utilized by the mannequin (enabling coaching with bigger batch-size, so accelerating coaching in a way) but it surely doesn’t change the inference-time since there’ll nonetheless be as many BERT executions regardless of whether or not their weights are shared or not.
What about inference time?
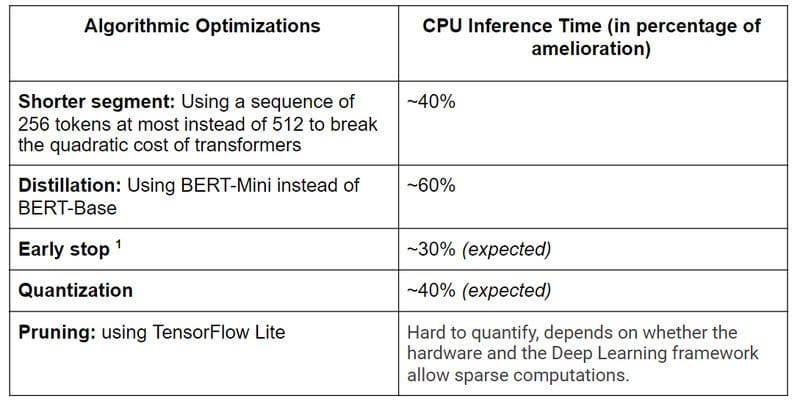
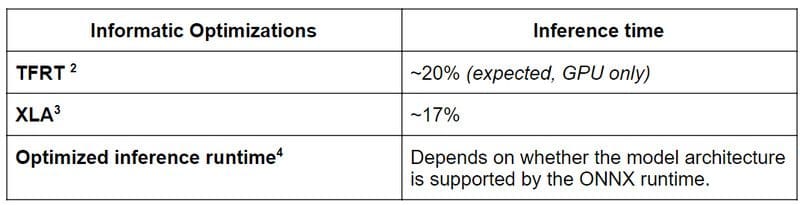
By now, you need to have guessed that together with that many invocations of the BERT mannequin don’t come totally free. And it’s true that it’s computationally costly to run inference of such a mannequin. Nevertheless, there are a few tips to enhance inference instances. Within the following, we deal with CPU inference as this is essential in manufacturing environments.
A few notes for the performed experiments:
- We contemplate a simplified mannequin solely containing a textual content characteristic.
- We restricted the tokens that we used per doc to 25,600 tokens which correspond roughly to round 130,000 characters if the doc accommodates English textual content.
- We carry out the experiments with paperwork which have the above described most size. In follow, paperwork have various sizes and as we use dynamic dimension tensors in our mannequin, inference instances are significantly sooner for brief paperwork. As a rule of thumb, when utilizing a doc that’s half as lengthy reduces the inference time by 50 %.
References
- https://arxiv.org/abs/2006.04152, https://arxiv.org/pdf/2001.08950.pdf
- https://blog.tensorflow.org/2020/04/tfrt-new-tensorflow-runtime.html
- https://www.tensorflow.org/xla?hl=fr
- https://medium.com/microsoftazure/accelerate-your-nlp-pipelines-using-hugging-face-transformers-and-onnx-runtime-2443578f4333
What else is there to do?
Linear Transformers
Constructing a Transformer-like structure that doesn’t include the quadratic complexity in time and reminiscence is at the moment a really energetic area of analysis. There are a few candidates which are positively price making an attempt as soon as pre-trained fashions can be launched:
A preliminary take a look at with the very promising Longformer mannequin couldn’t be executed efficiently. We tried to coach a LongFormer mannequin utilizing the TensorFlow implementation of Hugging Face. Nevertheless, it seems that the implementation shouldn’t be but memory-optimized because it was not potential to coach it even on a big GPU with 48 GB of reminiscence.
Inference time is the cornerstone of any ML venture that should run in manufacturing, so we do plan to make use of such “linear transformers” sooner or later along with pruning and quantization.
Are we finished but?
Sure, thanks for sticking with us till the top. When you have questions or remarks about our mannequin, be happy to remark. We’d love to listen to from you.
Original. Reposted with permission.
[ad_2]
Source link
