

[ad_1]
Transformer-based fashions have dominated the pure language processing (NLP) subject since their introduction in 2017. Tokens for phrases, morphemes, punctuation, and so on., are generated from the textual content enter by the transformer. Nevertheless, as a result of transformers have to concentrate to each token within the enter, their context home windows have to be greater to deal with long-form jobs like ebook summaries, and so on., the place the variety of tokens within the enter would possibly simply exceed 100 thousand. To deal with inputs of arbitrary size, a bunch of researchers from Carnegie Mellon College supplies a broad technique for enhancing mannequin efficiency by supplementing pretrained encoder-decoder converters with an exterior datastore.
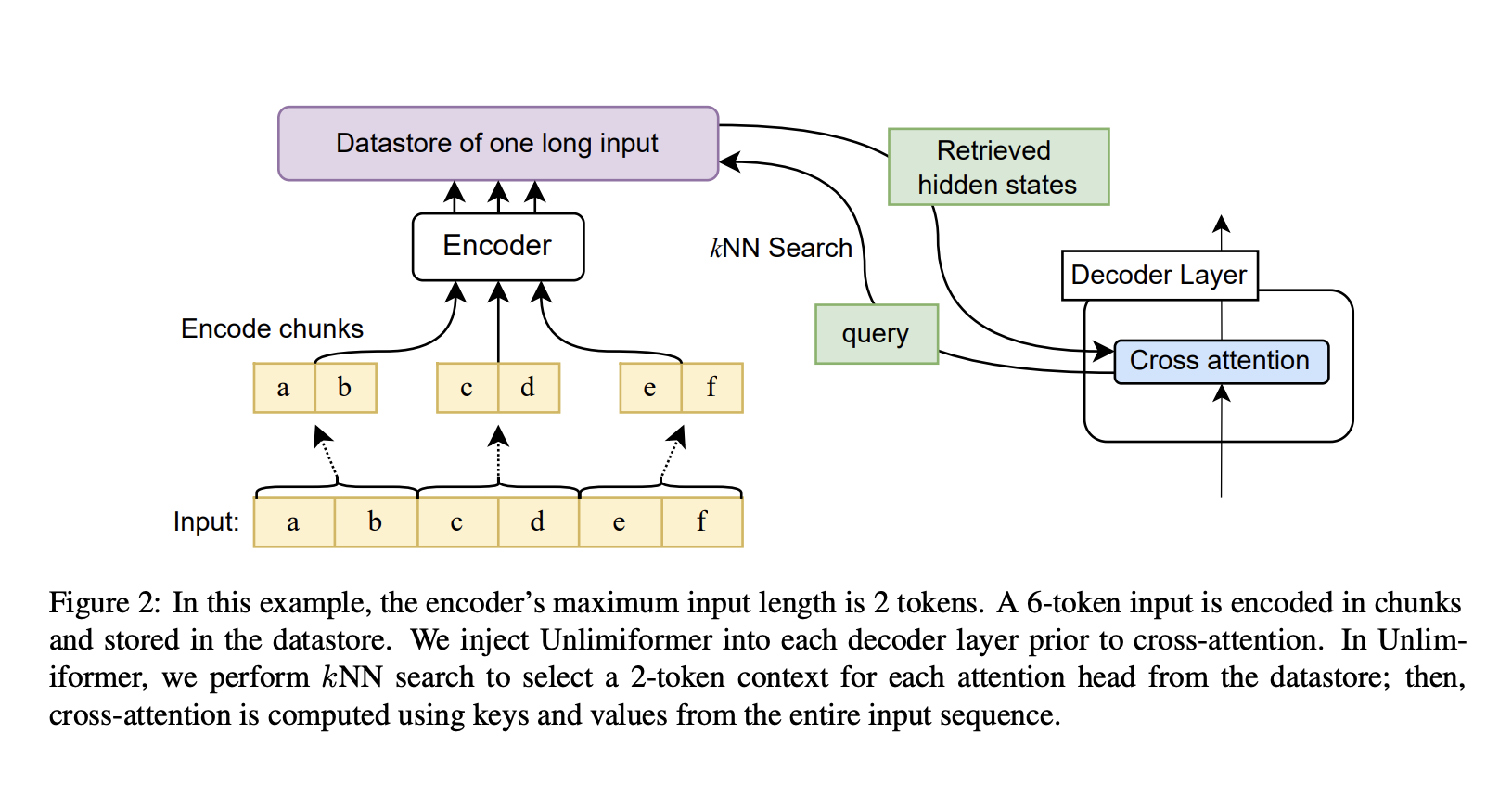
Unlimiformer is a brand new retrieval-based technique that expands the enter size tolerance of pretrained language fashions throughout testing. Any preexisting encoder-decoder transformer might be augmented with Unlimiformer to just accept limitless inputs. Unlimiformer builds a datastore over the hidden states of all enter tokens given a protracted enter sequence. Subsequent, the decoder makes use of its default cross consideration to entry the database and give attention to the highest ok enter tokens. The datastore helps sublinear searches and might be saved in GPU or CPU reminiscence. A educated mannequin can have its checkpoint enhanced by Unlimiformer with out extra coaching. Unlimiformer’s effectiveness might be additional enhanced by tuning.
The utmost size of an enter to a transformer is bounded by the dimensions of the encoder’s context window. Nevertheless, totally different info could also be significant throughout decoding phases, and totally different consideration facilities could give attention to a number of elements of the info. In consequence, a set context window could also be inefficient because it focuses on tokens that an consideration head must prioritize. At every decoding stage, Unlimiformer offers every head the choice of choosing its distinctive context window from your entire enter. To formalize this, we inject an Unlimiformer lookup into the decoder earlier than making use of cross-attention. This causes the mannequin to conduct a k-nearest neighbor (kNN) search in an exterior datastore, deciding on a set of tokens to give attention to for every decoder layer and a spotlight head.
To additional increase Unlimiformer’s effectiveness, researchers are actually specializing in coaching approaches. As a preliminary step, they take into account different coaching strategies that solely demand much less processing energy than the traditional fine-tuning regime. Additionally they examine the computationally expensive possibility of immediately coaching the Unlimiformer.
The research’s code and fashions can be found for obtain from GitHub.
Empirically, the workforce examined Unlimiformer on long-document and multi-document summarizing duties, displaying that it may summarize paperwork with as many as 350k tokens with out truncating the inputs. Current pretrained fashions had been additionally fine-tuned utilizing Unlimiformer, permitting them to deal with limitless inputs while not having any newly realized weights or alterations to the supply code. Including construction to the datastore or recovering embeddings in chunks, Unlimiformer could result in additional efficiency positive aspects in retrieval-augmented massive language fashions, which have proven encouraging outcomes on downstream sequence-to-sequence era duties. Incorporating construction into the datastore or retrieving embeddings in chunks are two methods the researchers imagine future work can increase pace. To additional improve the efficiency of retrieval-augmented LLMs on tough downstream duties, the data retrieval group has developed a wide selection of approaches for bettering retrieval. Because of this the researchers behind the HuggingFace Transformers library have launched a script that enables Unlimiformer to be injected into any mannequin with a single click on.
Take a look at the Paper and Github link. Don’t overlook to affix our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra. When you’ve got any questions concerning the above article or if we missed something, be happy to e mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Dhanshree Shenwai is a Laptop Science Engineer and has an excellent expertise in FinTech firms masking Monetary, Playing cards & Funds and Banking area with eager curiosity in purposes of AI. She is keen about exploring new applied sciences and developments in immediately’s evolving world making everybody’s life straightforward.
[ad_2]
Source link
