


[ad_1]
Neural networks study by numbers, so every phrase will likely be mapped to vectors to symbolize a specific phrase. The embedding layer could be regarded as a lookup desk that shops phrase embeddings and retrieves them utilizing indices.
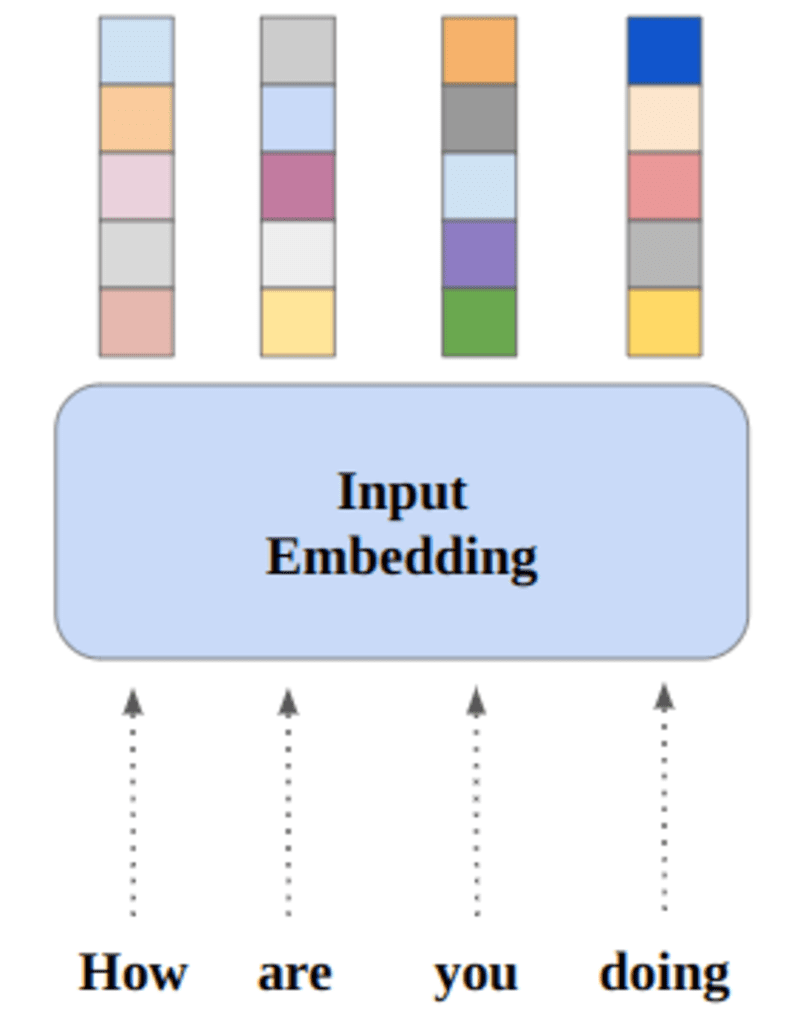
Phrases which have the identical that means will likely be shut when it comes to euclidian distance/cosine similarity. for instance, within the under phrase illustration, “Saturday”,” Sunday”, and” Monday” is related to the identical idea, so we are able to see that the phrases are ensuing related.

The figuring out the place of the phrase, Why do we have to decide the place of phrase? as a result of, the transformer encoder has no recurrence like recurrent neural networks,we should add some details about the positions into the enter embeddings. That is performed utilizing positional encoding. The authors of the paper used the next capabilities to mannequin the place of a phrase.
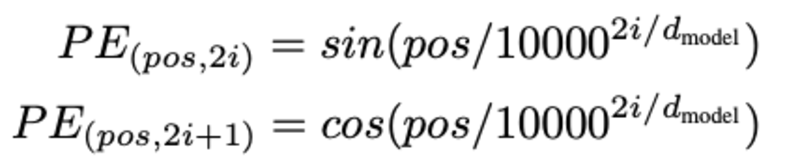
We are going to attempt to clarify positional Encoding.
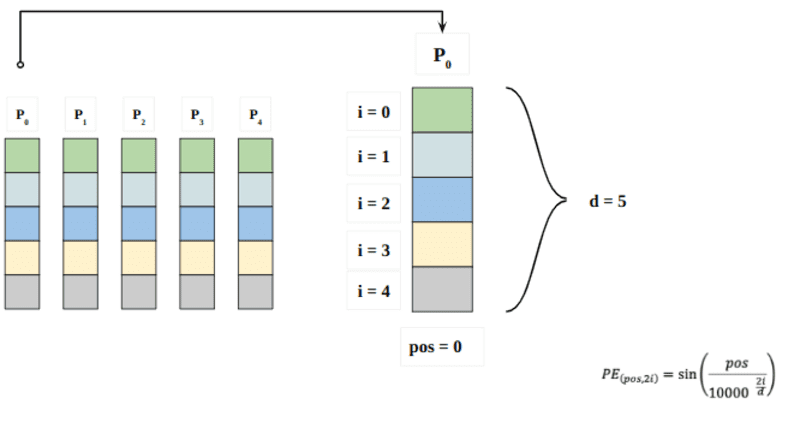
Right here “pos” refers back to the place of the “phrase” within the sequence. P0 refers back to the place embedding of the primary phrase; “d” means the scale of the phrase/token embedding. On this instance d=5. Lastly, “i” refers to every of the 5 particular person dimensions of the embedding (i.e. 0, 1,2,3,4)
if “i” differ within the equation above, you’re going to get a bunch of curves with various frequencies. Studying off the place embedding values in opposition to totally different frequencies, giving totally different values at totally different embedding dimensions for P0 and P4.
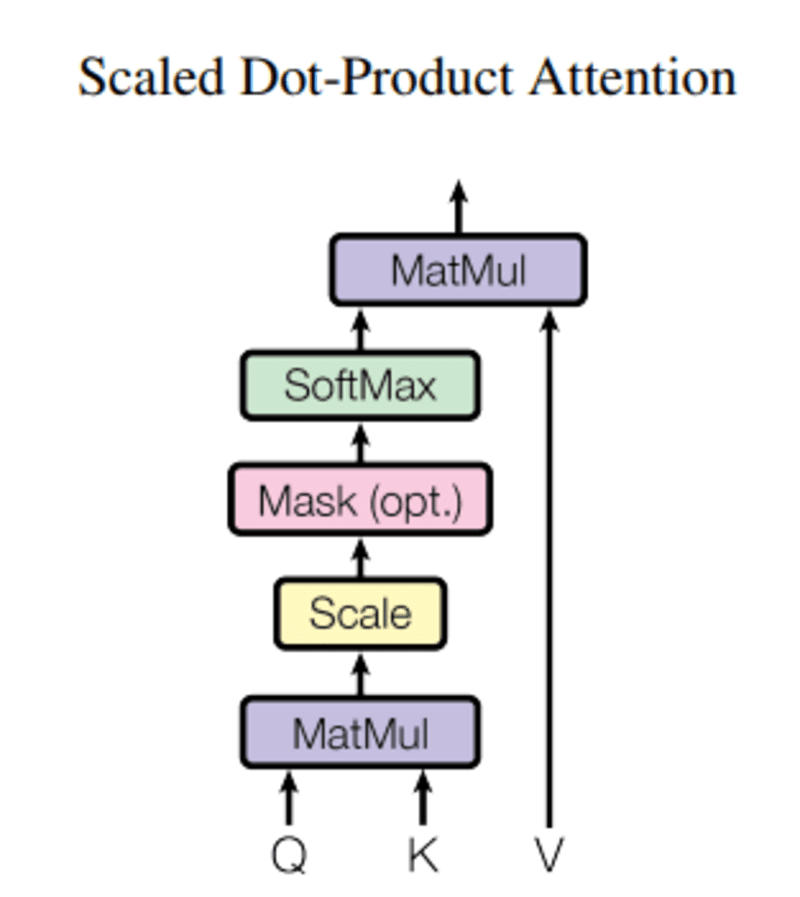
On this question, Q represents a vector phrase, the keys Ok are all different phrases within the sentence, and worth V represents the vector of the phrase.
The aim of consideration is to calculate the significance of the important thing time period in comparison with the question time period associated to the identical particular person/factor or idea.
In our case, V is the same as Q.
The eye mechanism offers us the significance of the phrase in a sentence.
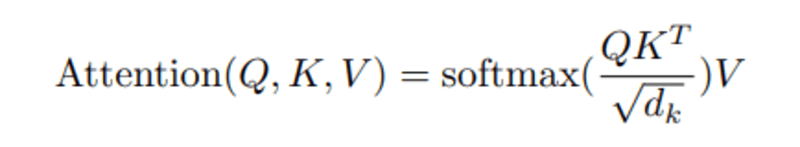
Once we compute the normalized dot product between the question and the keys, we get a tensor that represents the relative significance of one another phrase for the question.
When computing the dot product between Q and Ok.T, we attempt to estimate how the vectors (i.e phrases between question and keys) are aligned and return a weight for every phrase within the sentence.
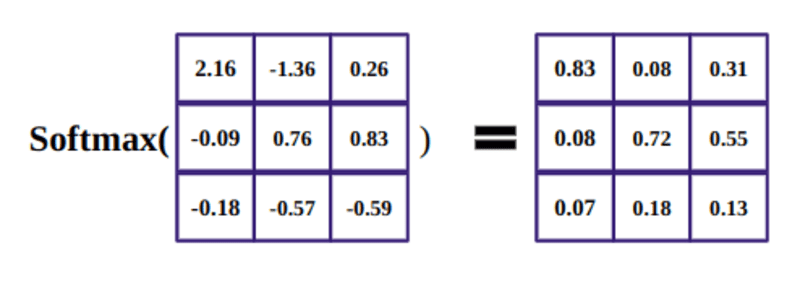
Then, we normalize the outcome squared of d_k and The softmax perform regularizes the phrases and rescales them between 0 and 1.
Lastly, we multiply the outcome( i.e weights) by the worth (i.e all phrases) to scale back the significance of non-relevant phrases and focus solely on a very powerful phrases.
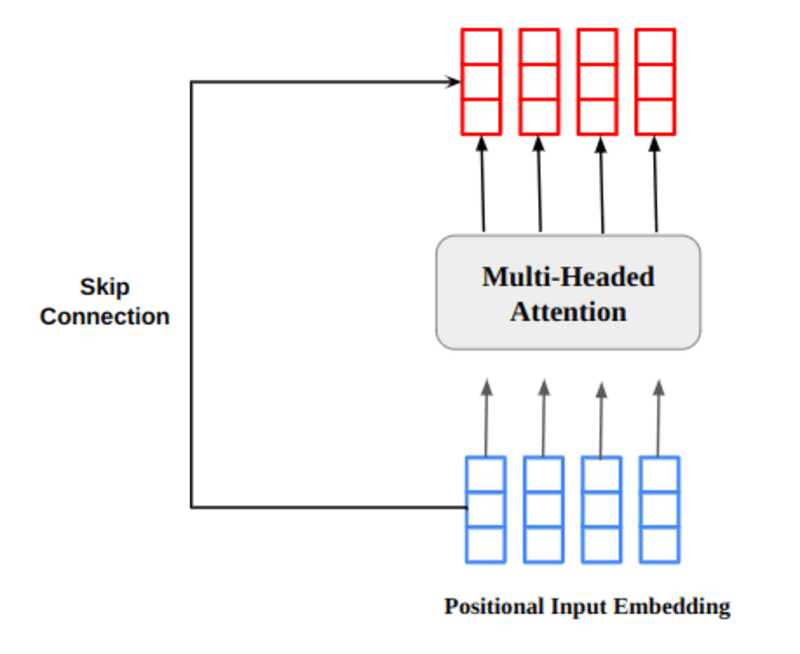
The multi-headed consideration output vector is added to the unique positional enter embedding. That is referred to as a residual connection/skip connection. The output of the residual connection goes by layer normalization. The normalized residual output is handed by a pointwise feed-forward community for additional processing.
The masks is a matrix that’s the identical measurement as the eye scores full of values of 0’s and unfavourable infinities.

The rationale for the masks is that after you are taking the softmax of the masked scores, the unfavourable infinities get zero, leaving zero consideration scores for future tokens.
This tells the mannequin to place no deal with these phrases.
The aim of the softmax perform is to seize actual numbers(optimistic and unfavourable) and switch them into optimistic numbers which sum to 1.
Ravikumar Naduvin is busy in constructing and understanding NLP duties utilizing PyTorch.
Original. Reposted with permission.
[ad_2]
Source link
