


[ad_1]

Picture by Creator
Time period frequency Inverse doc frequency (TFIDF) is a statistical system to transform textual content paperwork into vectors based mostly on the relevancy of the phrase. It’s based mostly on the bag of the phrases mannequin to create a matrix containing the details about much less related and most related phrases within the doc.
TF-IDF is especially helpful in NLP duties, subject modeling, and machine studying duties. It helps algorithms to make use of the significance of the phrases to foretell outcomes.
Time period Frequency (TF)
It’s the ratio of the prevalence of the phrase (w) in doc (d) per the entire variety of phrases within the paperwork. With this straightforward formulation, we’re measuring the frequency of a phrase within the doc.
For instance, if the sentence has 6 phrases and comprises two “the”, the TF ratio of this phrase could be (2/6).
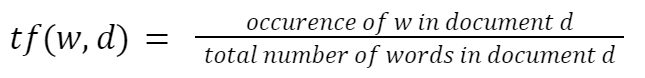
Inverse Doc Frequency (IDF)
IDF calculates the significance of a phrase in a corpus D. Essentially the most incessantly used phrases like “of, we, are” have little to no significance. It’s calculated by dividing the entire variety of paperwork within the corpus by the variety of paperwork containing the phrase.
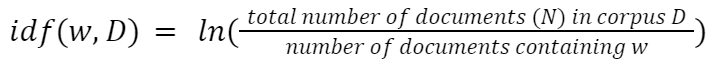
Time period Frequency Inverse Doc Frequency (TFIDF)
TF-IDF is the product of time period frequency and inverse doc frequency. It offers extra significance to the phrase that’s uncommon within the corpus and customary in a doc.
TF-IDF Matrix instance from Vaibhav Jayaswal’s weblog:
There are two paperwork in a corpus: Textual content A and Textual content B. We’ll use them to create a TF-IDF matrix.
- Textual content A: Jupiter is the most important planet
- Textual content B: Mars is the fourth planet from the solar
The desk under exhibits the values of TF for A and B, IDF, and TFIDF for A and B.
| Phrases | TF ( A ) | TF ( B ) | IDF | TFIDF ( A ) | TFIDF ( B ) |
| jupiter | 1/5 | 0 | In (2/1)=0.69 | 0.138 | 0 |
| is | 1/5 | 1/8 | In (2/2)=0 | 0 | 0 |
| the | 1/5 | 2/8 | In (2/2)=0 | 0 | 0 |
| largest | 1/5 | 0 | In (2/1)=0.69 | 0.138 | 0 |
| planet | 1/5 | 1/8 | In (2/2)=0 | 0.138 | 0 |
| mars | 0 | 1/8 | In (2/1)=0.69 | 0 | 0.086 |
| fourth | 0 | 1/8 | In (2/1)=0.69 | 0 | 0.086 |
| from | 0 | 1/8 | In (2/1)=0.69 | 0 | 0.086 |
| solar | 0 | 1/8 | In (2/1)=0.69 | 0 | 0.086 |
On this tutorial, we’re going to use TfidfVectorizer from scikit-learn to transform the textual content and look at the TF-IDF matrix.
Within the code under, we’ve a small corpus of 4 paperwork. First, we are going to create a vectorizer object utilizing `TfidfVectorizer()` and match and remodel the textual content information into vectors. After that, we are going to use vectorizers to extract the names of the phrases.
from sklearn.feature_extraction.textual content import TfidfVectorizer
corpus = [
'KDnuggets Collection of data science Projects',
'3 Free Statistics Courses for data science',
'Parallel Processing Large File in Python',
'15 Python Coding Interview Questions You Must Know For data science',
]
vectorizer = TfidfVectorizer()
# TD-IDF Matrix
X = vectorizer.fit_transform(corpus)
# extracting function names
tfidf_tokens = vectorizer.get_feature_names_out()
We’ll now use TF-IDF tokens and vectors to create a pandas dataframe.
- Convert the vectors to arrays and add it to the information argument.
- 4 indexes are created manually.
- tfidf_tokens names are added to columns
import pandas as pd
end result = pd.DataFrame(
information=X.toarray(),
index=["Doc1", "Doc2", "Doc3", "Doc4"],
columns=tfidf_tokens
)
end result
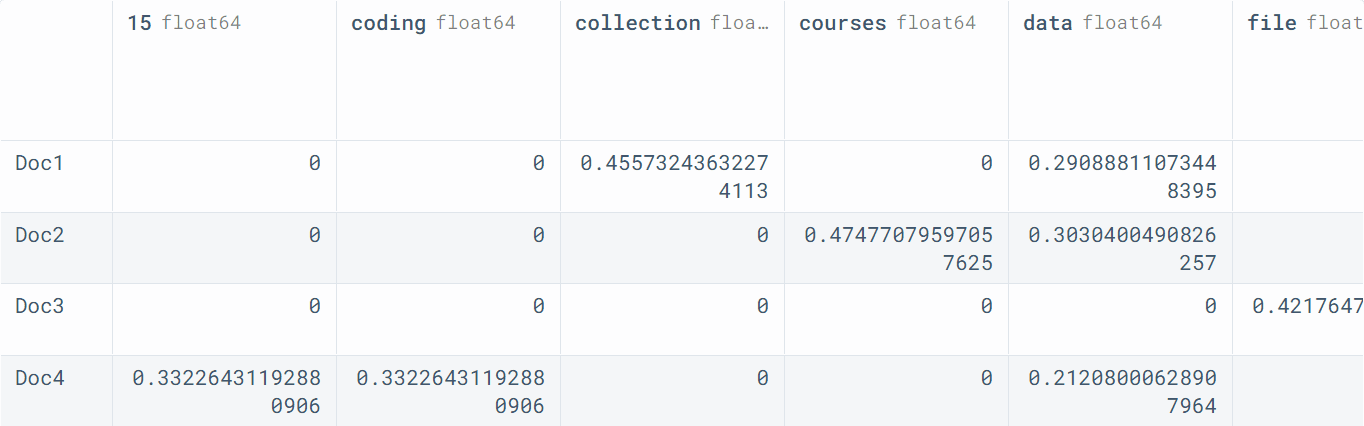
The pandas information body exhibits columns because the phrases and rows because the paperwork.
Within the dataframe under, each phrase has an essential worth based mostly on the TF-IDF system.
Let’s go one step additional and use the TF-IDF to transform textual content into vectors after which use it to coach a textual content classification mannequin. For coaching the mannequin, we shall be utilizing Spotify App Reviews information from Kaggle.
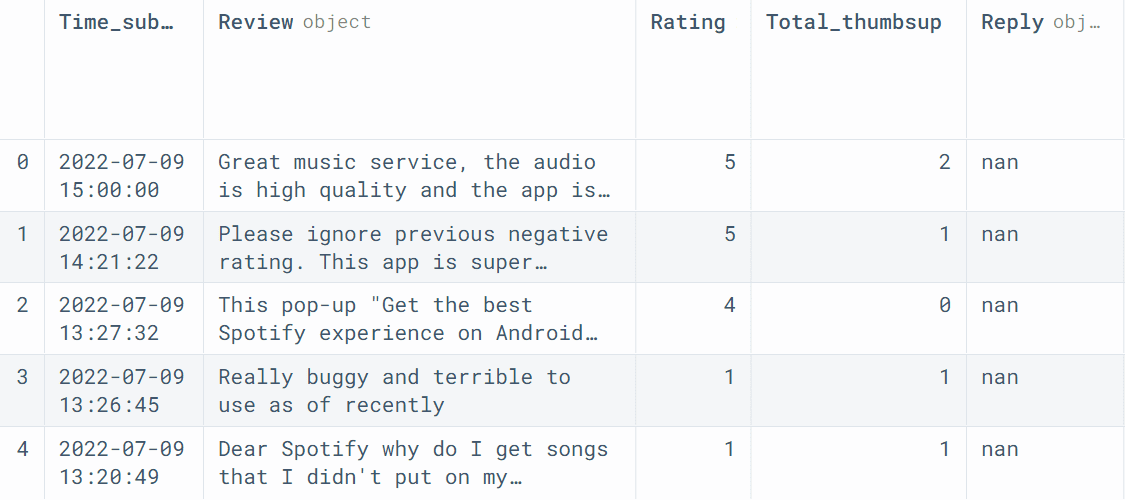
We’ll use read_csv to load the information and look at the primary 5 rows.
import pandas as pd
spotify = pd.read_csv("critiques.csv")
spotify.head()
We shall be solely utilizing Evaluation and Score columns for coaching the fashions.
We’ll remodel the Evaluation column to vectors and set Score because the goal. After that, we are going to break up the dataset for coaching and testing.
from sklearn.feature_extraction.textual content import TfidfVectorizer
from sklearn.model_selection import train_test_split
# Remodel options
X = spotify.Evaluation
X_tfidf = vectorizer.fit_transform(X)
# create goal
y = spotify.Score
# break up the dataset for coaching and testing
X_train, X_test, y_train, y_test = train_test_split(
X_tfidf, y, test_size=0.33, random_state=42
)
We gained’t be going deep into function engineering, textual content processing, or hyperparameter optimization. We’ll choose a easy mannequin (SGDClassifier) and practice it on X_train and y_train.
For mannequin validation, we are going to predict the values utilizing X_test and print classification report.
from sklearn.linear_model import SGDClassifier from sklearn.metrics import classification_report # Coaching classifier mannequin clf = SGDClassifier() clf.match(X_train, y_train) # mannequin validation y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred))
As we are able to observe, we bought a 0.69 F1 rating by coaching it on the default configuration. We are able to enhance mannequin efficiency by cross-validation, hyper-parameter optimization, textual content cleansing and processing, and have engineering.
precision recall f1-score help
1 0.57 0.90 0.69 5817
2 0.25 0.03 0.05 2274
3 0.28 0.06 0.10 2293
4 0.41 0.19 0.26 2556
5 0.73 0.91 0.81 7387
accuracy 0.62 20327
macro avg 0.45 0.42 0.38 20327
weighted avg 0.54 0.62 0.54 20327
“Thanks for studying the tutorial. I hope I made a distinction in making you perceive the basics of TF-IDF. In case you have any additional questions simply kind under or attain out on LinkedIn.”
Abid Ali Awan (@1abidaliawan) is an authorized information scientist skilled who loves constructing machine studying fashions. Presently, he’s specializing in content material creation and writing technical blogs on machine studying and information science applied sciences. Abid holds a Grasp’s diploma in Expertise Administration and a bachelor’s diploma in Telecommunication Engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college kids scuffling with psychological sickness.
[ad_2]
Source link
