

[ad_1]

Picture by israel palacio on Unsplash
The article is in continuation of the story How to build a Web App to Transcribe and Summarize audio with Python. Within the earlier submit, I’ve proven methods to construct an app that transcribes and summarizes the content material of your favorite Spotify Podcast. The abstract of a textual content will be helpful for listeners to resolve if the episode is fascinating or not earlier than listening to it.
However there are different doable options that may be extracted from audio. The matters. Matter modelling is among the many pure language processing that allows the automated extraction of matters from various kinds of sources, similar to opinions of lodges, job gives, and social media posts.
On this submit, we’re going to construct an app that collects the matters from a podcast episode with Python and analyzes the significance of every matter extracted with good knowledge visualizations. In the long run, we’ll deploy the net app to Heroku free of charge.
Necessities
- Create a GitHub repository, that will probably be wanted to deploy the net software into manufacturing to Heroku!
- Clone the repository in your native PC with
git clone <name-repository>.git. In my case, I’ll use VS code, which is an IDE actually environment friendly to work with python scripts, consists of Git help and integrates the terminal. Copy the next instructions on the terminal:
git init
git commit -m "first commit"
git department -M grasp
git distant add origin https://github.com//.git
git push -u origin grasp
- Create a digital surroundings in Python.
This tutorial is cut up into two most important components. Within the first half, we create our easy internet software to extract the matters from the podcast. The remaining half focuses on the deployment of the app, which is a vital step for sharing your app with the world anytime. Let’s get began!
1. Extract Episode’s URL from Pay attention Notes
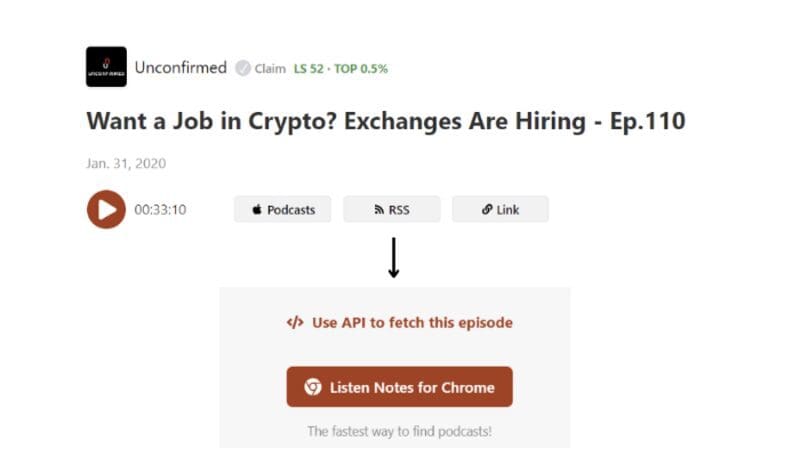
We’re going to uncover the matters from an episode of Unconfirmed, referred to as Need a Job in Crypto? Exchanges are hiring — Ep. 110. Yow will discover the hyperlink to the episode here. As chances are you’ll know from the information in tv and newspaper, blockchain business is exploding and there may be the esigence to maintain up to date within the opening of jobs in that discipline. Absolutely, they’ll want knowledge engineers and knowledge scientists to handle knowledge and extract values from these enormous quantities of knowledge.
Pay attention Notes is a podcast search engine and database on-line, permitting us to get entry to podcast audio by means of their APIs. We have to outline the operate to extract the episode’s URL from the net web page. First, that you must create an account to retrieve the info and subscribe to free plan to make use of the Pay attention Notes API.
Then, you click on the episode you have an interest in and choose the choice “Use API to fetch this episode” on the proper of the web page. When you pressed it, you may change the default coding language to Python and click on the requests choice to make use of that python package deal. After, you copy the code and adapt it right into a operate.
import streamlit as st
import requests
import zipfile
import json
from time import sleep
import yaml
def retrieve_url_podcast(parameters,episode_id):
url_episodes_endpoint="https://listen-api.listennotes.com/api/v2/episodes"
headers = {
'X-ListenAPI-Key': parameters["api_key_listennotes"],
}
url = f"{url_episodes_endpoint}/{episode_id}"
response = requests.request('GET', url, headers=headers)
print(response.json())
knowledge = response.json()
audio_url = knowledge['audio']
return audio_url
It takes the credentials from a separate file, secrets and techniques.yaml, which consists of a set of key-value pairs just like the dictionaries:
api_key:{your-api-key-assemblyai}
api_key_listennotes:{your-api-key-listennotes}
2. Retrieve Transcription and Subjects from Audio
To extract the matters, we first must ship a submit request to AssemblyAI’s transcript endpoint by giving in enter the audio URL retrieved within the earlier step. After we will receive the transcription and the matters of our podcast by sending a GET request to AssemblyAI.
## ship transcription request
def send_transc_request(headers, audio_url):
transcript_endpoint = "https://api.assemblyai.com/v2/transcript"
transcript_request = {
"audio_url": audio_url,
"iab_categories": True,
}
transcript_response = requests.submit(
transcript_endpoint, json=transcript_request, headers=headers
)
transcript_id = transcript_response.json()["id"]
return transcript_id
##retrieve transcription and matters
def obtain_polling_response(headers, transcript_id):
polling_endpoint = (
f"https://api.assemblyai.com/v2/transcript/{transcript_id}"
)
polling_response = requests.get(polling_endpoint, headers=headers)
i = 0
whereas polling_response.json()["status"] != "accomplished":
sleep(5)
polling_response = requests.get(
polling_endpoint, headers=headers
)
return polling_response
The outcomes will probably be saved into two totally different recordsdata:
def save_files(polling_response):
with open("transcript.txt", 'w') as f:
f.write(polling_response.json()['text'])
f.shut()
with open('only_topics.json', 'w') as f:
matters = polling_response.json()['iab_categories_result']
json.dump(matters, f, indent=4)
def save_zip():
list_files = ['transcript.txt','only_topics.json','barplot.html']
with zipfile.ZipFile('remaining.zip', 'w') as zipF:
for file in list_files:
zipF.write(file, compress_type=zipfile.ZIP_DEFLATED)
zipF.shut()
Beneath I present an instance of transcription:
Hello everybody. Welcome to Unconfirmed, the podcast that reveals how the advertising names and crypto are reacting to the week's prime headlines and will get the insights you on what they see on the horizon. I am your host, Laura Shin. Crypto, aka Kelman Legislation, is a New York legislation agency run by a number of the first attorneys to enter crypto in 2013 with experience in litigation, dispute decision and anti cash laundering. E mail them at data at kelman legislation. ....
Now, I present the output of the matters extracted from the podcast’s episode:
{
"standing": "success",
"outcomes": [
{
"text": "Hi everyone. Welcome to Unconfirmed, the podcast that reveals how the marketing names and crypto are reacting to the week's top headlines and gets the insights you on what they see on the horizon. I'm your host, Laura Shin. Crypto, aka Kelman Law, is a New York law firm run by some of the first lawyers to enter crypto in 2013 with expertise in litigation, dispute resolution and anti money laundering. Email them at info at kelman law.",
"labels": [
{
"relevance": 0.015229620970785618,
"label": "PersonalFinance>PersonalInvesting"
},
{
"relevance": 0.007826927118003368,
"label": "BusinessAndFinance>Industries>FinancialIndustry"
},
{
"relevance": 0.007203377783298492,
"label": "BusinessAndFinance>Business>BusinessBanking&Finance>AngelInvestment"
},
{
"relevance": 0.006419596262276173,
"label": "PersonalFinance>PersonalInvesting>HedgeFunds"
},
{
"relevance": 0.0057992455549538136,
"label": "Hobbies&Interests>ContentProduction"
},
{
"relevance": 0.005361487623304129,
"label": "BusinessAndFinance>Economy>Currencies"
},
{
"relevance": 0.004509655758738518,
"label": "BusinessAndFinance>Industries>LegalServicesIndustry"
},
{
"relevance": 0.004465851932764053,
"label": "Technology&Computing>Computing>Internet>InternetForBeginners"
},
{
"relevance": 0.0021628723479807377,
"label": "BusinessAndFinance>Economy>Commodities"
},
{
"relevance": 0.0017050291644409299,
"label": "PersonalFinance>PersonalInvesting>StocksAndBonds"
}
],
"timestamp": {
"begin": 4090,
"finish": 26670
}
},...],
"abstract": {
"Careers>JobSearch": 1.0,
"BusinessAndFinance>Enterprise>BusinessBanking&Finance>VentureCapital": 0.9733043313026428,
"BusinessAndFinance>Enterprise>Startups": 0.9268804788589478,
"BusinessAndFinance>Financial system>JobMarket": 0.7761372327804565,
"BusinessAndFinance>Enterprise>BusinessBanking&Finance>AngelInvestment": 0.6847236156463623,
"PersonalFinance>PersonalInvesting>StocksAndBonds": 0.6514145135879517,
"BusinessAndFinance>Enterprise>BusinessBanking&Finance>PrivateEquity": 0.3943130075931549,
"BusinessAndFinance>Industries>FinancialIndustry": 0.3717447817325592,
"PersonalFinance>PersonalInvesting": 0.3703657388687134,
"BusinessAndFinance>Industries": 0.29375147819519043,
"BusinessAndFinance>Financial system>Currencies": 0.27661699056625366,
"BusinessAndFinance": 0.1965470314025879,
"Hobbies&Pursuits>ContentProduction": 0.1607944369316101,
"BusinessAndFinance>Financial system>FinancialRegulation": 0.1570006012916565,
"Expertise&Computing": 0.13974210619926453,
"Expertise&Computing>Computing>ComputerSoftwareAndApplications>SharewareAndFreeware": 0.13566900789737701,
"BusinessAndFinance>Industries>TechnologyIndustry": 0.13414880633354187,
"BusinessAndFinance>Industries>InformationServicesIndustry": 0.12478621304035187,
"BusinessAndFinance>Financial system>FinancialReform": 0.12252965569496155,
"BusinessAndFinance>Enterprise>BusinessBanking&Finance>MergersAndAcquisitions": 0.11304120719432831
}
}
We’ve got obtained a JSON file, containing all of the matters detected by AssemblyAI. Basically, we transcribed the podcast into textual content, which is cut up up into totally different sentences and their corresponding relevance. For every sentence, we’ve a listing of matters. On the finish of this large dictionary, there’s a abstract of matters which have been extracted from all of the sentences.
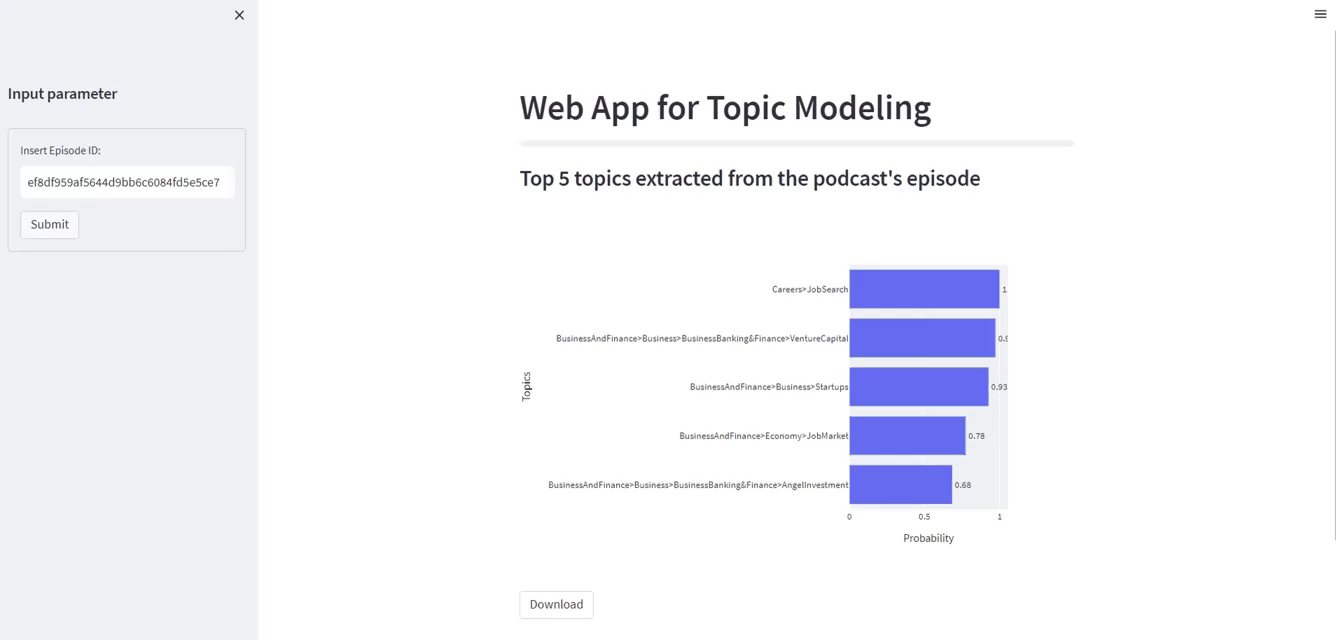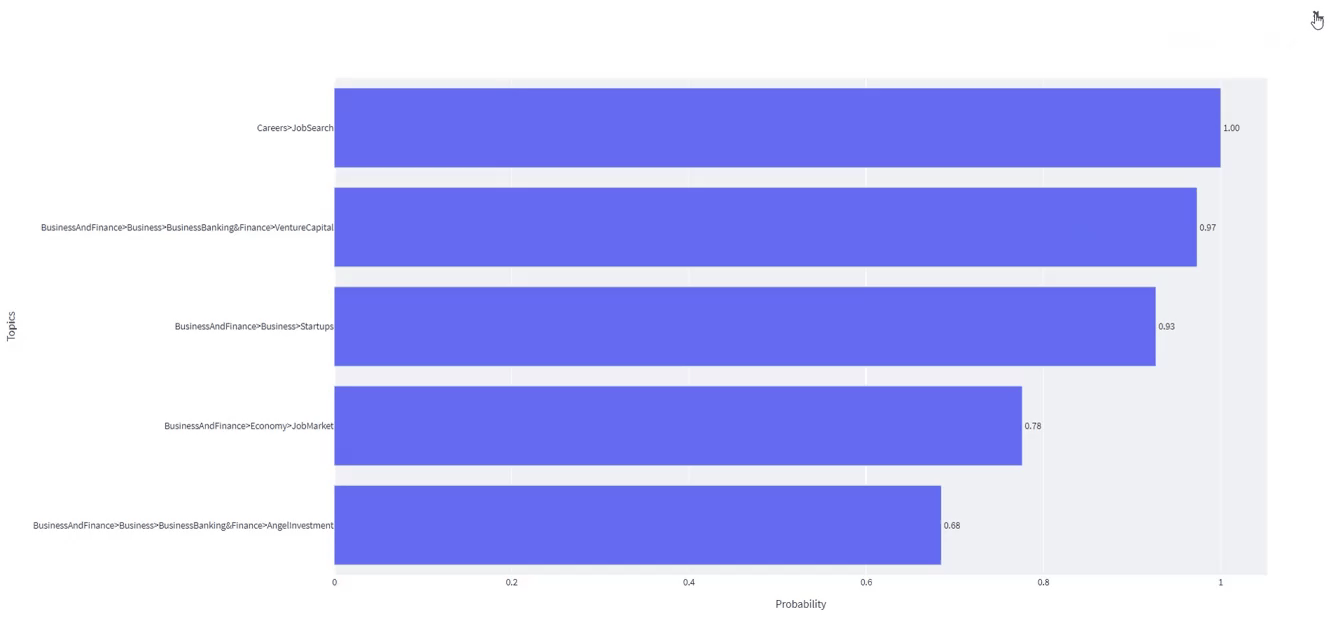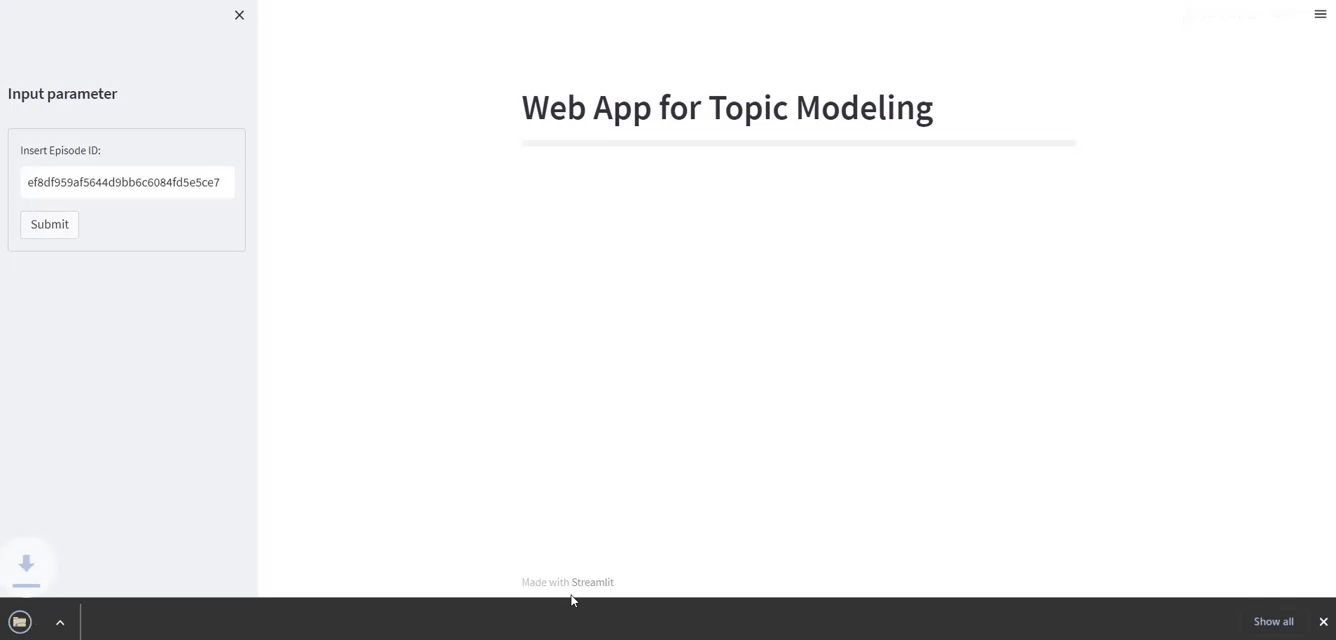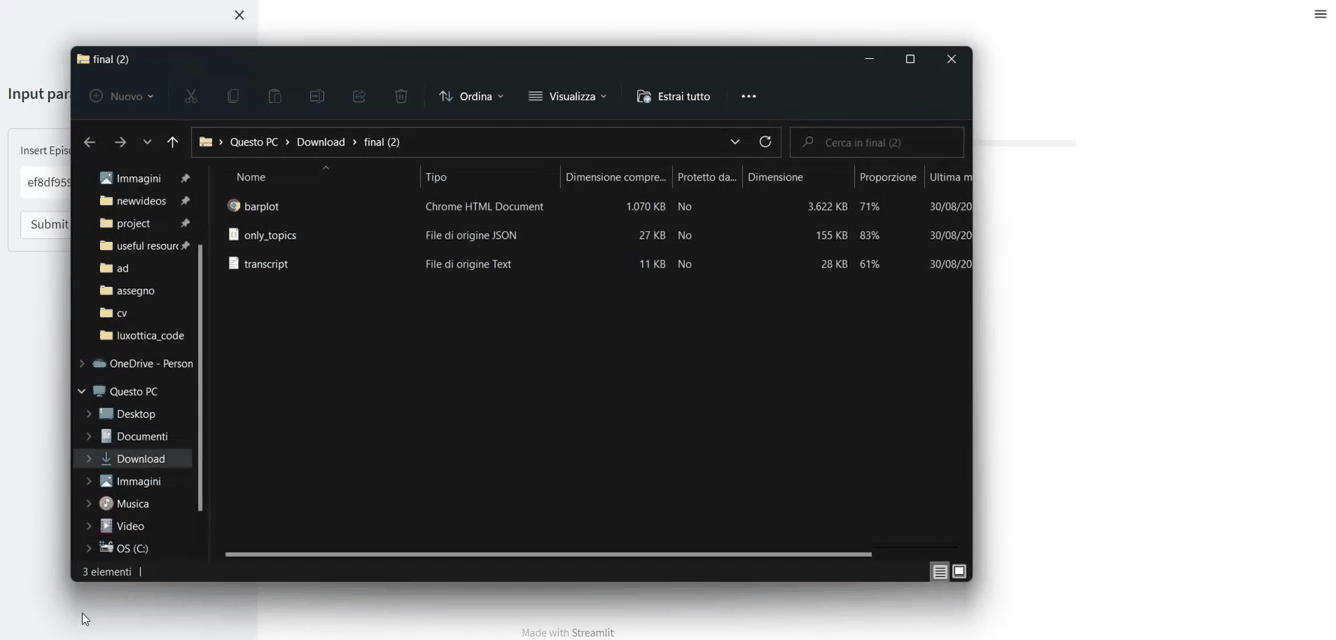
It’s value noticing that Careers and JobSearch represent essentially the most related matter. Within the prime 5 labels, we additionally discover Enterprise and Finance, Startups, Financial system, Enterprise and Banking, Enterprise Capital, and different comparable matters.
3. Construct a Net Utility with Streamlit
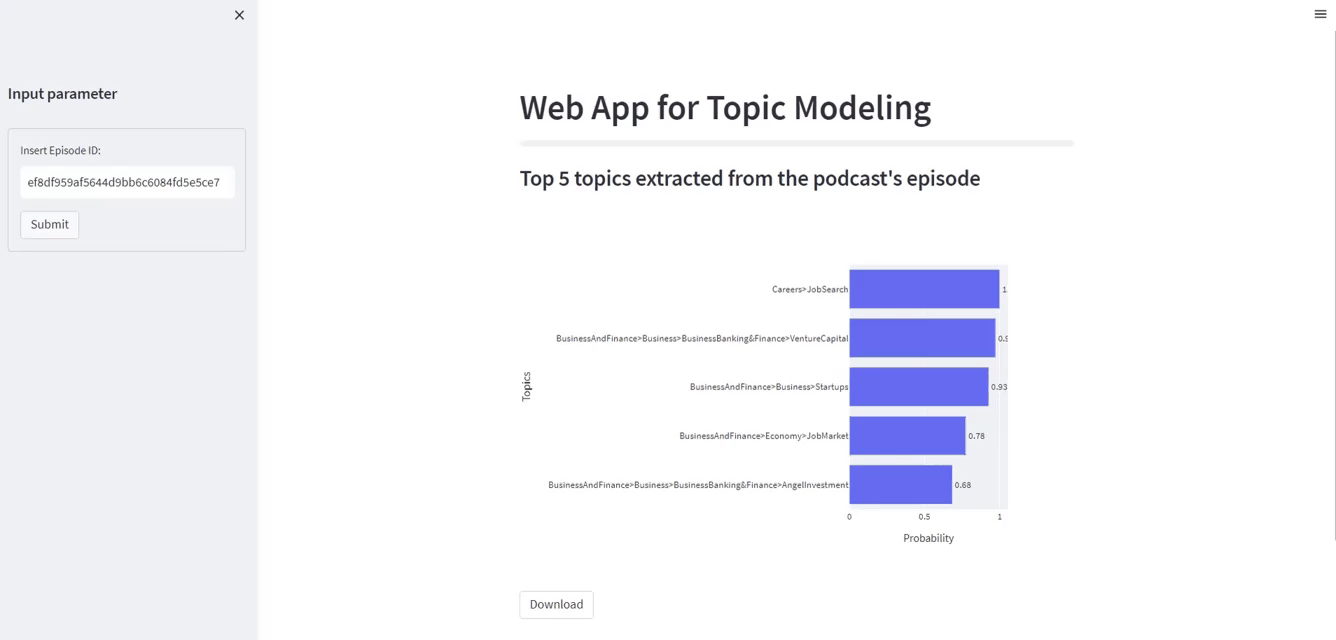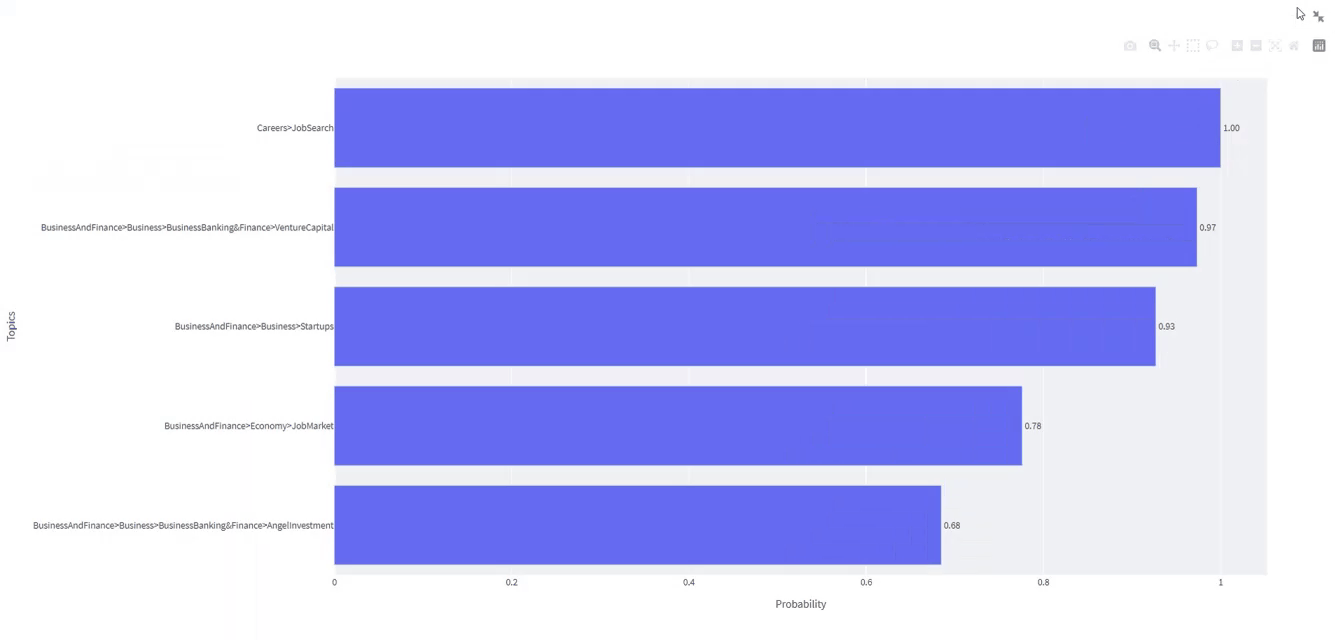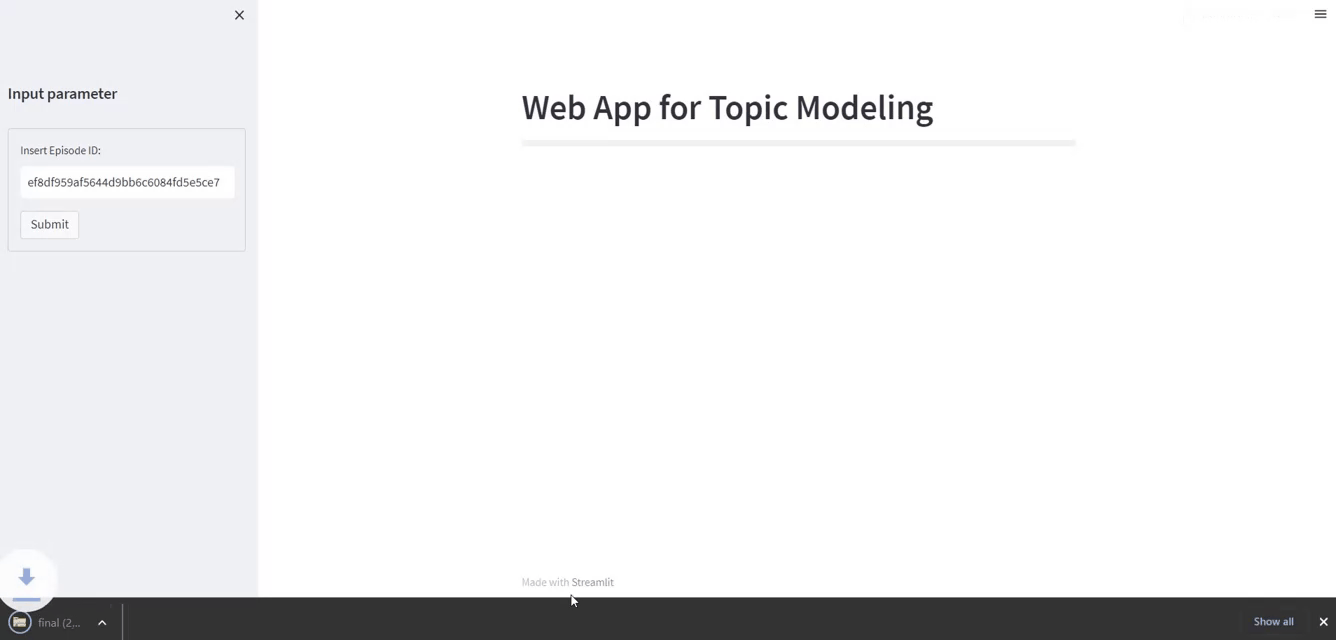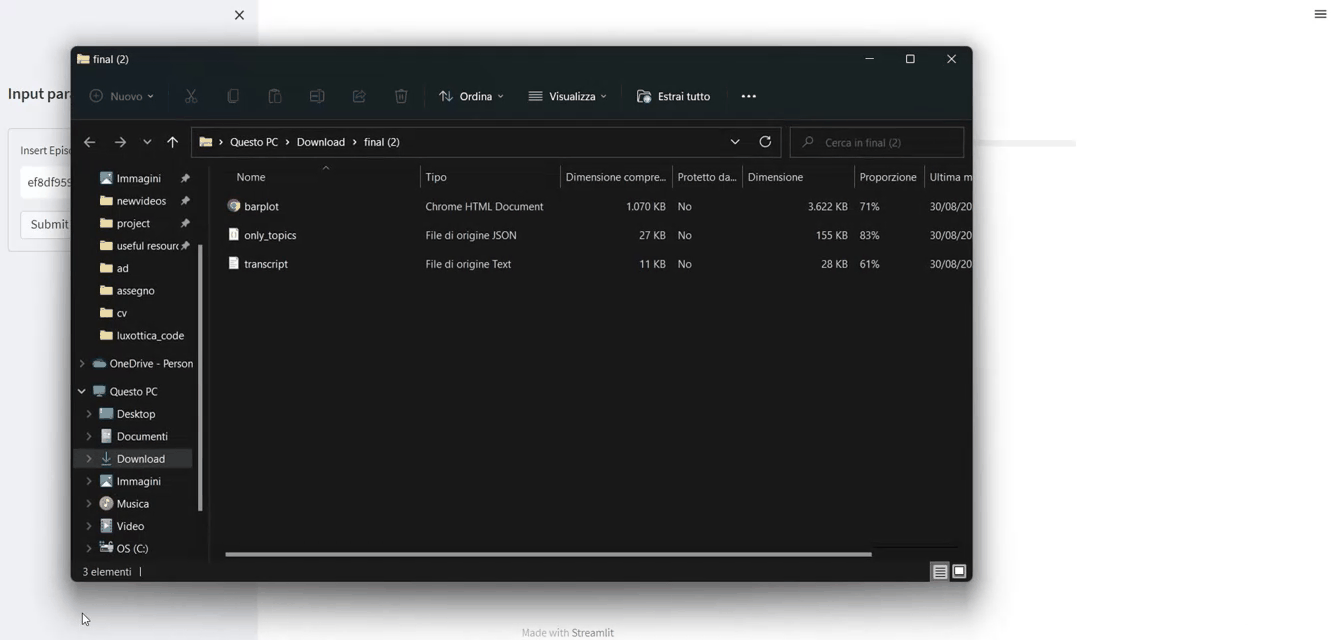
The hyperlink to the App deployed is here
Now, we put all of the features outlined within the earlier steps into the principle block, during which we construct our internet software with Streamlit, a free open-source framework that permits constructing purposes with few traces of code utilizing Python:
- The primary title of the app is displayed utilizing
st.markdown. - A left panel sidebar is created utilizing
st.sidebar. We’d like it to insert the episode id of our podcast. - After urgent the button “Submit”, a bar plot will seem, displaying essentially the most related 5 matters extracted.
- there may be the Obtain button in case you need to obtain the transcription, the matters, and the info visualization
st.markdown("# **Net App for Matter Modeling**")
bar = st.progress(0)
st.sidebar.header("Enter parameter")
with st.sidebar.kind(key="my_form"):
episode_id = st.text_input("Insert Episode ID:")
# 7b23aaaaf1344501bdbe97141d5250ff
submit_button = st.form_submit_button(label="Submit")
if submit_button:
f = open("secrets and techniques.yaml", "rb")
parameters = yaml.load(f, Loader=yaml.FullLoader)
f.shut()
# step 1 - Extract episode's url from pay attention notes
audio_url = retrieve_url_podcast(parameters, episode_id)
# bar.progress(30)
api_key = parameters["api_key"]
headers = {
"authorization": api_key,
"content-type": "software/json",
}
# step 2 - retrieve id of transcription response from AssemblyAI
transcript_id = send_transc_request(headers, audio_url)
# bar.progress(70)
# step 3 - matters
polling_response = obtain_polling_response(headers, transcript_id)
save_files(polling_response)
df = create_df_topics()
import plotly.specific as px
st.subheader("High 5 matters extracted from the podcast's episode")
fig = px.bar(
df.iloc[:5, :].sort_values(
by=["Probability"], ascending=True
),
x="Likelihood",
y="Subjects",
textual content="Likelihood",
)
fig.update_traces(
texttemplate="%{textual content:.2f}", textposition="exterior"
)
fig.write_html("barplot.html")
st.plotly_chart(fig)
save_zip()
with open("remaining.zip", "rb") as zip_download:
btn = st.download_button(
label="Obtain",
knowledge=zip_download,
file_name="remaining.zip",
mime="software/zip",
)
To run the net software, that you must write the next command line on the terminal:
streamlit run topic_app.py
Superb! Now two URL ought to seem, click on one in every of these and the net software is prepared for use!
When you accomplished the code of the net software and also you checked if it really works properly, the following step is to deploy it on the Web to Heroku.
You’re most likely questioning what Heroku is. It’s a cloud platform that permits the event and deployment of internet purposes utilizing totally different coding languages.
1. Create necessities.txt, Procfile, and setup.sh
After, we create a file necessities.txt, that features all of the python packages requested by your script. We will robotically create it utilizing the next command line by utilizing this marvellous python library pipreqs.
It should magically generate a necessities.txt file:
pandas==1.4.3
plotly==5.10.0
PyYAML==6.0
requests==2.28.1
streamlit==1.12.2
Keep away from utilizing the command line pip freeze > necessities like this article recommended. The issue is that it returns extra python packages that would not be required from that particular venture.
Along with necessities.txt, we additionally want Procfile, which specifies the instructions which can be wanted to run the net software.
internet: sh setup.sh && streamlit run topic_app.py
The final requirement is to have a setup.sh file that incorporates the next code:
mkdir -p ~/.streamlit/
echo "
[server]n
port = $PORTn
enableCORS = falsen
headless = truen
n
" > ~/.streamlit/config.toml
2. Connect with Heroku
When you didn’t register but on Heroku’s web site, that you must create a free account to have the ability to exploit its providers. It’s additionally crucial to put in Heroku in your native PC. When you achieved these two necessities, we will start the enjoyable half! Copy the next command line on the terminal:
After urgent the command, a window of Heroku will seem in your browser and also you’ll must put the e-mail and password of your account. If it really works, it is best to have the next consequence:

So, you may return on VS code and write the command to create your internet software on the terminal:
heroku create topic-web-app-heroku
Output:
Creating ⬢ topic-web-app-heroku... carried out
https://topic-web-app-heroku.herokuapp.com/ | https://git.heroku.com/topic-web-app-heroku.git
To deploy the app to Heroku, we want this command line:
It’s used to push the code from the native repository’s most important department to heroku distant. After you push the modifications to your repository with different instructions:
git add -A
git commit -m "App over!"
git push
We’re lastly carried out! Now it is best to see your app that’s lastly deployed!
I hope you appreciated this mini-project! It may be actually enjoyable to create and deploy apps. The primary time generally is a little intimidating, however when you end, you received’t have any regrets! I additionally need to spotlight that it’s higher to deploy your internet software to Heroku if you end up engaged on small initiatives with low reminiscence necessities. Different options will be greater cloud platform frameworks, like AWS Lambda and Google Cloud. The GitHub code is here. Thanks for studying. Have a pleasant day!
Eugenia Anello is at present a analysis fellow on the Division of Data Engineering of the College of Padova, Italy. Her analysis venture is concentrated on Continuous Studying mixed with Anomaly Detection.
Original. Reposted with permission.
[ad_2]
Source link
