


[ad_1]

Picture by Pixabay from Pexels
Visualization is an enormous a part of the info world as people perceive the data simply when it’s offered proper. That’s the reason creating an informative and enticing visualization is anticipated from any knowledge particular person.
A histogram chart is among the most typical but helpful graphs. The histogram is a chart with bars representing the frequency of knowledge divided into sure bins. It’s typically used to visualise numerical knowledge to know the info distribution and determine the pattern.
How can we create a ravishing histogram chart? Let’s learn to do it.
For our dataset instance, we might use the MPG open knowledge from the Seaborn bundle.
import seaborn as sns
mpg = sns.load_dataset('mpg')
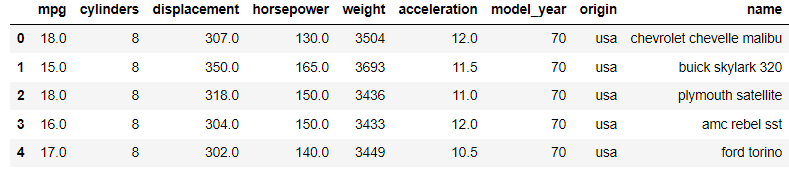
mpg.head()
From our dataset instance, we might shortly develop a easy histogram chart utilizing the Seaborn bundle. To try this, we have to use the histplot perform.
The perform would default take the numerical knowledge variable as an argument, and the output is the histogram of the handed values. Let’s attempt the perform.
# Create a histogram of the "mpg" variable
sns.histplot(knowledge=mpg, x="mpg")
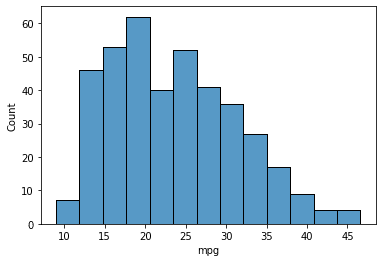
From one line of code, we find yourself with a pleasant histogram visualization. The “mpg” variable distribution was skewed proper as many values fall between 15-25. That is the sort of info we may get with a histogram.
The Seaborn histogram default visualization is sweet, however we would wish to change the histogram graph to make it extra lovely.
On this case, there are numerous customise choices utilizing the Seaborn bundle.
A number of histogram plots based mostly on categorical columns
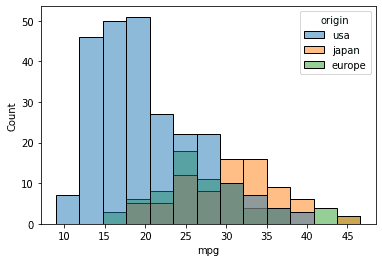
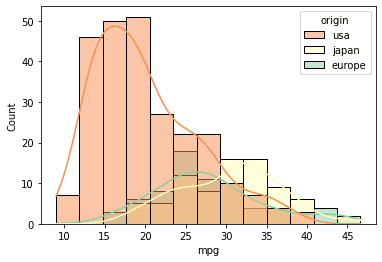
Typically, we wish to examine the variable numerical distribution based mostly on the opposite variable worth. To try this, we will cross the variable title to match within the hue parameter.
sns.histplot(knowledge=mpg, x="mpg", hue="origin")
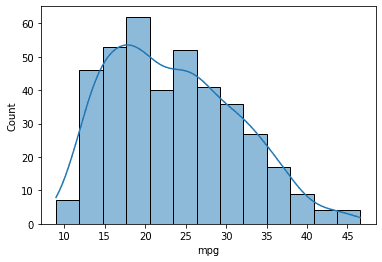
Present Kernel Density Estimate (KDE) curve
Kernel Density Estimate or KDE is a non-parametric approach to estimate the likelihood of the info utilizing density perform. Mainly, KDE smoothes the histogram to indicate the distribution. To point out the KDE curve, we may use the next code.
sns.histplot(knowledge=mpg, x="mpg", kde=True)
Change the bins quantity
Histogram plot is dependent upon the interval quantity for binning the variable values. If we wish to change the bin quantity, it’s potential to do this by passing the bins parameter utilizing the next code.
sns.histplot(knowledge=mpg, x="mpg", bins = 5)
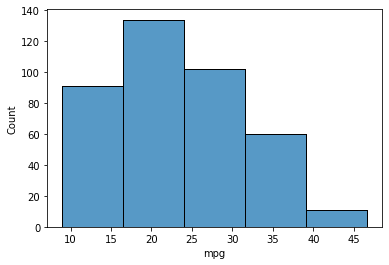
It’s also potential to vary the bin quantity based mostly on the width utilizing the binwidth parameter.
sns.histplot(knowledge=mpg, x="mpg", binwidth=5)
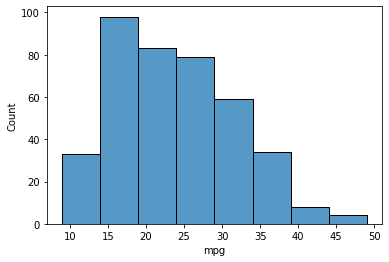
Moreover, it’s potential to restrict the minimal and the utmost bin vary utilizing the binrange parameter.
sns.histplot(knowledge=mpg, x="mpg", binrange=(5, 30))

Change the mixture statistic
By default, Seaborn assumed the histogram was used to rely the values that fall in every bin. Nonetheless, we may change the mixture statistic. A couple of choices can be found in seaborn, together with:
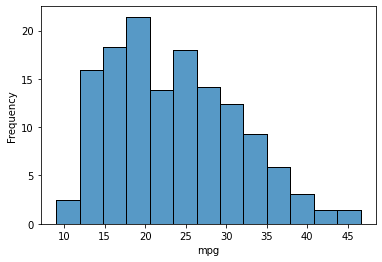
- Frequency
Present the variety of noticed values divided by the bin width.
sns.histplot(knowledge=mpg, x="mpg", stat="frequency")
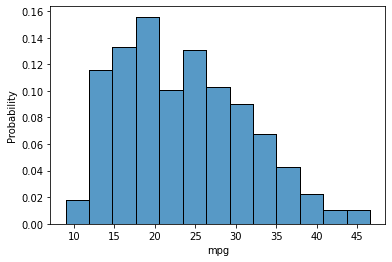
- Chance
Present the normalized values so the bar top sum is 1.
sns.histplot(knowledge=mpg, x="mpg", stat="likelihood")
- Density
Present the normalized values so the whole space of the histogram is 1.
sns.histplot(knowledge=mpg, x="mpg", stat="density")
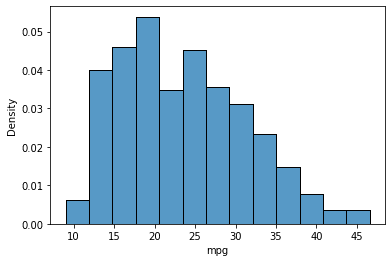
Tweaking histogram aesthetic
It’s potential to vary the colour and transparency of the histogram plot. For a single histogram plot, we may cross the colour string worth to the colour parameter and the clear worth to the alpha parameter.
sns.histplot(knowledge=mpg, x="mpg", shade="purple", alpha = 0.5)
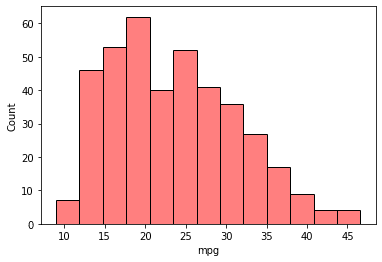
If we’ve got a number of histogram plots, we may change the general shade theme by altering the palette parameter. To know which values to make use of within the palette parameter, we may discover them within the documentation.
sns.histplot(knowledge=mpg, x="mpg", kde = True, palette = "Spectral", hue="origin")
Histogram is a plot to visualise numerical variables and purchase the distribution pattern info. It’s a useful visualization when we have to current what occurs in our knowledge. Utilizing the Seaborn Python bundle, we may simply create a ravishing histogram plot and tweak them as required.
Cornellius Yudha Wijaya is a knowledge science assistant supervisor and knowledge author. Whereas working full-time at Allianz Indonesia, he likes to share Python and Information ideas through social media and writing media.
[ad_2]
Source link
