

[ad_1]
Defining the Downside Textual content-to-image era has lengthy been a problem in synthetic intelligence. The power to remodel textual descriptions into vivid, life like photographs is a important step towards bridging the hole between pure language understanding and visible content material creation. Researchers have grappled with this downside, striving to develop fashions to perform this feat effectively and successfully.
Deci AI introduces DeciDiffusion 1.0 – A New Strategy To resolve the text-to-image era downside, a analysis workforce launched DeciDiffusion 1.0, a groundbreaking mannequin representing a big leap ahead on this area. DeciDiffusion 1.0 builds upon the foundations of earlier fashions however introduces a number of key improvements that set it aside.
One of many key improvements is the substitution of the standard U-Internet structure with the extra environment friendly U-Internet-NAS. This architectural change reduces the variety of parameters whereas sustaining and even enhancing efficiency. The result’s a mannequin that isn’t solely able to producing high-quality photographs but additionally does so extra effectively when it comes to computation.
The mannequin’s coaching course of can be noteworthy. It undergoes a four-phase coaching process to optimize pattern effectivity and computational velocity. This method is essential for making certain the mannequin can generate photographs with fewer iterations, making it extra sensible for real-world purposes.
DeciDiffusion 1.0 – A Nearer Look Delving deeper into DeciDiffusion 1.0’s expertise, we discover that it leverages a Variational Autoencoder (VAE) and CLIP’s pre-trained Textual content Encoder. This mixture permits the mannequin to successfully perceive textual descriptions and remodel them into visible representations.
One of many mannequin’s key achievements is its capability to provide high-quality photographs. It achieves comparable Frechet Inception Distance (FID) scores to current fashions however does so with fewer iterations. Because of this DeciDiffusion 1.0 is sample-efficient and might generate life like photographs extra rapidly.
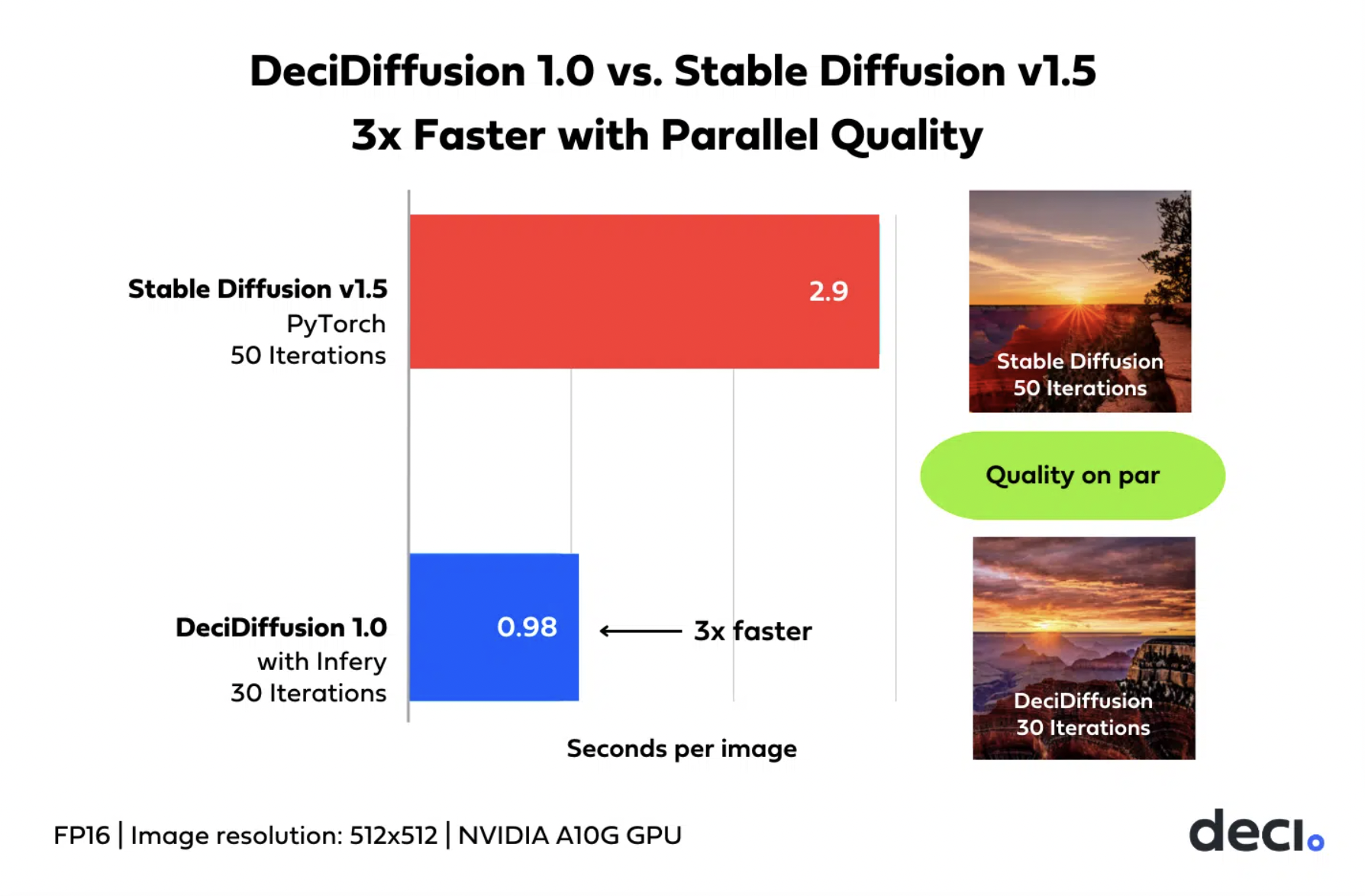
A very fascinating facet of the analysis workforce’s analysis is the consumer research performed to evaluate DeciDiffusion 1.0’s efficiency. Utilizing a set of 10 prompts, the research in contrast DeciDiffusion 1.0 to Steady Diffusion 1.5. Every mannequin was configured to generate photographs with completely different iterations, offering helpful perception into aesthetics and immediate alignment.
The consumer research outcomes reveal that DeciDiffusion 1.0 holds a bonus when it comes to picture aesthetics. In comparison with Steady Diffusion 1.5, DeciDiffusion 1.0, at 30 iterations, constantly produced extra visually interesting photographs. Nonetheless, it’s essential to notice that immediate alignment, the power to generate photographs that match the offered textual descriptions, was on par with Steady Diffusion 1.5 at 50 iterations. This means that DeciDiffusion 1.0 strikes a steadiness between effectivity and high quality.
In conclusion, DeciDiffusion 1.0 is a exceptional innovation in a text-to-image era. It tackles a long-standing downside and presents a promising resolution. By changing the U-Internet structure with U-Internet-NAS and optimizing the coaching course of, the analysis workforce has created a mannequin that isn’t solely able to producing high-quality photographs but additionally does so extra effectively.
The consumer research outcomes underscore the mannequin’s strengths, notably its capability to excel in aesthetics. It is a important step in making text-to-image era extra accessible and sensible for numerous purposes. Whereas challenges stay, comparable to dealing with non-English prompts and addressing potential biases, DeciDiffusion 1.0 represents a milestone in merging pure language understanding and visible content material creation.
DeciDiffusion 1.0 is a testomony to the facility of revolutionary pondering and superior coaching methods within the quickly evolving area of synthetic intelligence. As researchers proceed to push the boundaries of what AI can obtain, we are able to count on additional breakthroughs that can carry us nearer to a world the place textual content seamlessly transforms into fascinating imagery, unlocking new potentialities throughout numerous industries and domains.
Take a look at the Code, Demo, and Deci Blog. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t overlook to affix our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
If you like our work, you will love our newsletter..
Madhur Garg is a consulting intern at MarktechPost. He’s presently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Expertise (IIT), Patna. He shares a powerful ardour for Machine Studying and enjoys exploring the newest developments in applied sciences and their sensible purposes. With a eager curiosity in synthetic intelligence and its various purposes, Madhur is set to contribute to the sphere of Knowledge Science and leverage its potential influence in numerous industries.
[ad_2]
Source link
