

[ad_1]
Deep studying and AI have made exceptional progress in recent times, particularly in detection fashions. Regardless of these spectacular developments, the effectiveness of object detection fashions closely depends on large-scale benchmark datasets. Nonetheless, the problem lies within the variation of object classes and scenes. In the true world, there are important variations from present photographs, and novel object lessons might emerge, necessitating the reconstruction of datasets to make sure object detectors’ success. Sadly, this severely impacts their means to generalize in open-world eventualities. In distinction, people, even kids, can rapidly adapt and generalize properly in new environments. Consequently, the dearth of universality in AI stays a notable hole between AI techniques and human intelligence.
The important thing to overcoming this limitation is the event of a common object detector to attain detection capabilities throughout all forms of objects in any given scene. Such a mannequin would possess the exceptional means to operate successfully in unknown conditions with out requiring extra re-training. Such a breakthrough would considerably method the objective of constructing object detection techniques as clever as people.
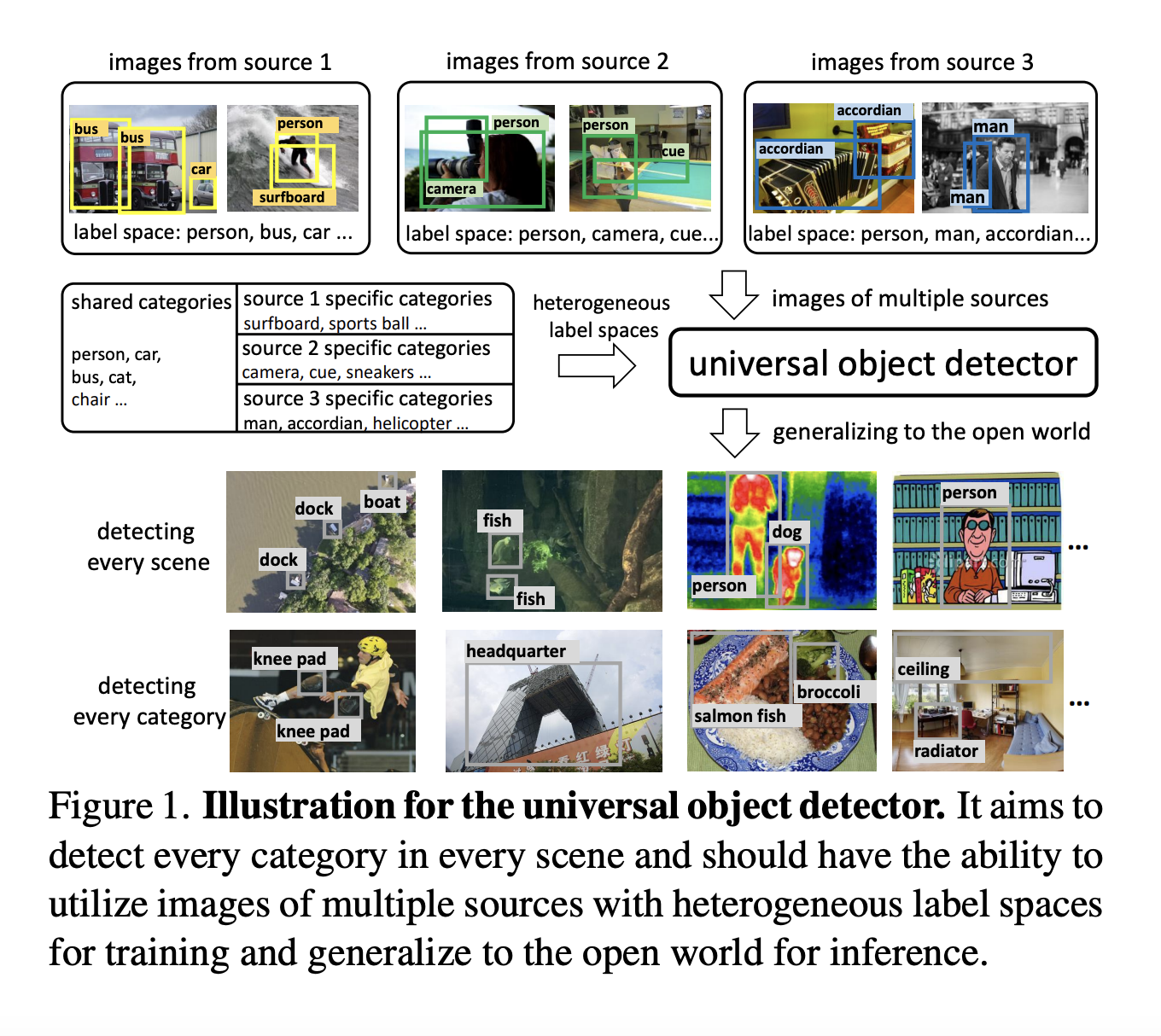
A common object detector should possess two important skills. Firstly, it ought to be educated utilizing photographs from varied sources and numerous label areas. Collaborative coaching on a big scale for classification and localization is important to make sure the detector positive aspects enough info to generalize successfully. The best large-scale studying dataset ought to embody many picture sorts, encompassing as many classes as doable, with high-quality bounding field annotations and intensive class vocabularies. Sadly, reaching such variety is difficult as a result of limitations posed by human annotators. In observe, whereas small vocabulary datasets supply cleaner annotations, bigger ones are noisier and should endure from inconsistencies. Moreover, specialised datasets deal with particular classes. To attain universality, the detector should study from a number of sources with various label areas to accumulate complete and full data.
Secondly, the detector ought to reveal sturdy generalization to the open world. It ought to be able to precisely predicting class tags for novel lessons not seen throughout coaching with none important drop in efficiency. Nonetheless, relying solely on visible info can not obtain this goal, as complete visible studying necessitates human annotations for fully-supervised studying.
To beat these limitations, a novel common object detection mannequin termed “UniDetector” has been proposed.
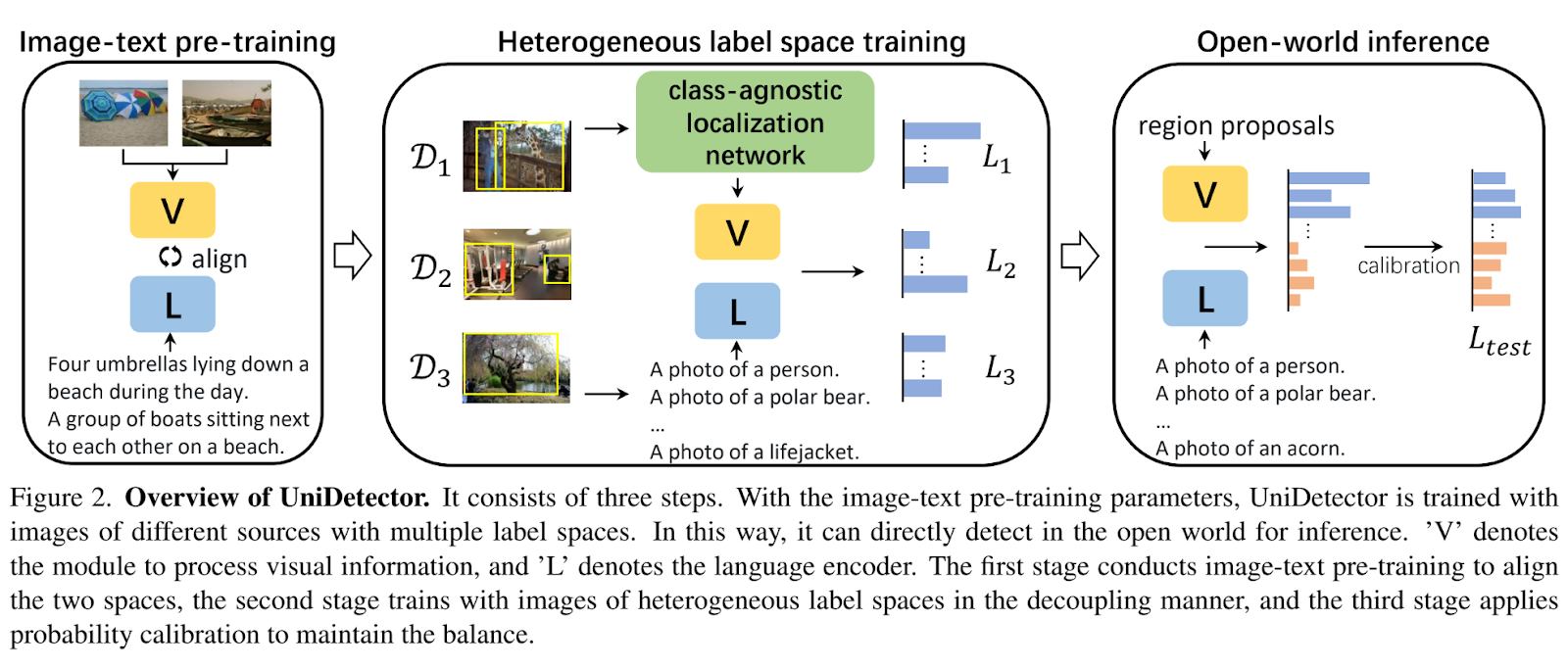
The structure overview is reported within the illustration beneath.
Two corresponding challenges have to be tackled to attain the 2 important skills of a common object detector. The primary problem refers to coaching with multi-source photographs, the place photographs come from totally different sources and are related to numerous label areas. Present detectors are restricted to predicting lessons from just one label area, and the variations in dataset-specific taxonomy and annotation inconsistency amongst datasets make it tough to unify a number of heterogeneous label areas.
The second problem includes novel class discrimination. Impressed by the success of image-text pre-training in current analysis, the authors leverage pre-trained fashions with language embeddings to acknowledge unseen classes. Nonetheless, fully-supervised coaching tends to bias the detector in direction of specializing in classes current throughout coaching. Consequently, the mannequin is perhaps skewed in direction of base lessons at inference time and produce under-confident predictions for novel lessons. Though language embeddings supply the potential to foretell novel lessons, their efficiency nonetheless lags considerably behind that of base classes.
UniDetector has been designed to sort out the abovementioned challenges. Using the language area, the researchers discover varied constructions to coach the detector successfully with heterogeneous label areas. They uncover that using a partitioned construction facilitates function sharing whereas avoiding label conflicts, which is helpful for the detector’s efficiency.
To boost the generalization means of the area proposal stage in direction of novel lessons, the authors decouple the proposal era stage from the RoI (Area of Curiosity) classification stage, choosing separate coaching as an alternative of joint coaching. This method leverages the distinctive traits of every stage, contributing to the general universality of the detector. Moreover, they introduce a class-agnostic localization community (CLN) to attain generalized area proposals.
Moreover, the authors suggest a chance calibration method to de-bias the predictions. They estimate the prior chance of all classes after which regulate the anticipated class distribution primarily based on this prior chance. This calibration considerably improves the efficiency of novel lessons throughout the object detection system. In response to the authors, UniDetector can surpass Dyhead, the state-of-the-art CNN detector, by 6.3% AP (Common Precision).
This was the abstract of UniDetector, a novel AI framework designed for common object detection. If you’re and need to study extra about this work, you’ll find additional info by clicking on the hyperlinks beneath.
Take a look at the Paper and Github. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t neglect to hitch our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
Daniele Lorenzi obtained his M.Sc. in ICT for Web and Multimedia Engineering in 2021 from the College of Padua, Italy. He’s a Ph.D. candidate on the Institute of Info Expertise (ITEC) on the Alpen-Adria-Universität (AAU) Klagenfurt. He’s at the moment working within the Christian Doppler Laboratory ATHENA and his analysis pursuits embody adaptive video streaming, immersive media, machine studying, and QoS/QoE analysis.
[ad_2]
Source link
