

[ad_1]
The fields of Machine Studying (ML) and Synthetic Intelligence (AI) are considerably progressing, primarily because of the utilization of bigger neural community fashions and the coaching of those fashions on more and more huge datasets. This growth has been made attainable via the implementation of information and mannequin parallelism methods, in addition to pipelining strategies, which distribute computational duties throughout a number of units concurrently. These developments permit for the concurrent utilization of many computing units.
Although modifications to mannequin architectures and optimization methods have made computing parallelism attainable, the core coaching paradigm has not considerably altered. Slicing-edge fashions proceed to work collectively as cohesive items, and optimization procedures require parameter, gradient, and activation swapping all through coaching. There are a selection of points with this conventional methodology.
Provisioning and managing the networked units vital for intensive coaching includes a major quantity of engineering and infrastructure. Each time a brand new mannequin launch is launched, the coaching course of incessantly must be restarted, which signifies that a considerable quantity of computational sources used to coach the earlier mannequin are wasted. Coaching monolithic fashions additionally current organizational points as a result of it’s exhausting to find out the affect of modifications made through the coaching course of different than simply getting ready the information.
To beat these points, a workforce of researchers from Google DeepMind has proposed a modular machine studying ML framework. The DIstributed PAths COmposition (DiPaCo) structure and coaching algorithm have been offered in an try to attain this scalable modular Machine Studying paradigm. DiPaCo’s optimization and structure are specifically made to cut back communication overhead and enhance scalability.
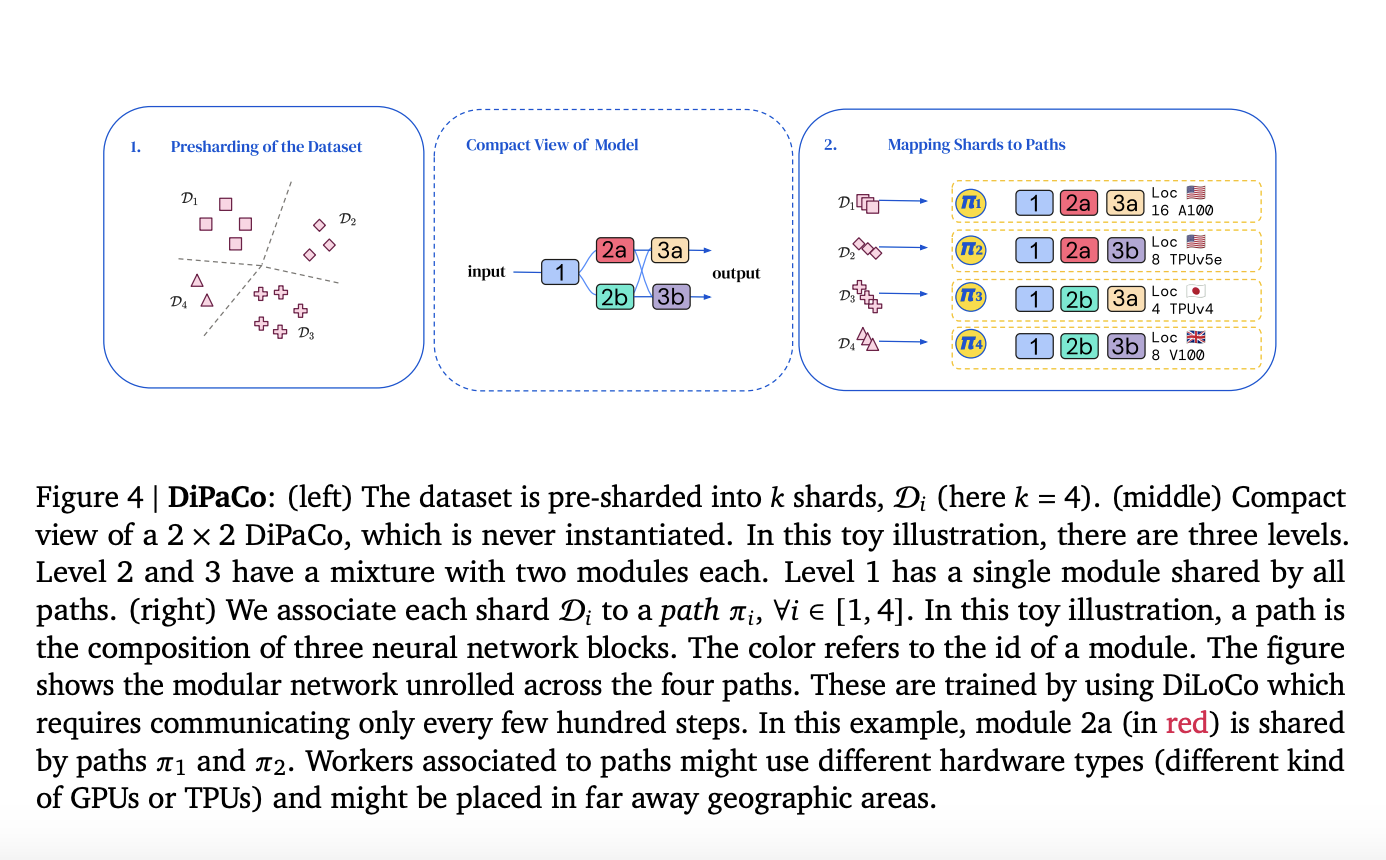
The distribution of computing by paths, the place a path is a sequence of modules forming an input-output operate, is the elemental concept underlying DiPaCo. Compared to the general mannequin, paths are comparatively small, requiring just a few securely related units for testing or coaching. A sparsely energetic DiPaCo structure outcomes from queries being directed to replicas of explicit paths reasonably than replicas of the whole mannequin throughout each coaching and deployment.
An optimization methodology known as DiLoCo has been used, which is impressed by Native-SGD and minimizes communication prices by sustaining module synchronization with much less communication. This optimization technique improves coaching robustness by mitigating employee failures and preemptions.
The effectiveness of DiPaCo has been demonstrated by the assessments on the favored C4 benchmark dataset. DiPaCo achieved higher efficiency than a dense transformer language mannequin with one billion parameters, even with the identical quantity of coaching steps. With solely 256 pathways to select from, every with 150 million parameters, DiPaCo can accomplish larger efficiency in a shorter quantity of wall clock time. This illustrates how DiPaCo can deal with complicated coaching jobs effectively and scalably.
In conclusion, DiPaCo eliminates the requirement for mannequin compression approaches at inference time by decreasing the variety of paths that have to be accomplished for every enter to only one. This simplified inference process lowers computing prices and will increase effectivity. DiPaCo is a prototype for a brand new, much less synchronous, extra modular paradigm of large-scale studying. It reveals how you can acquire higher efficiency with much less coaching time by using modular designs and efficient communication ways.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our newsletter..
Don’t Neglect to hitch our 38k+ ML SubReddit
Tanya Malhotra is a remaining 12 months undergrad from the College of Petroleum & Vitality Research, Dehradun, pursuing BTech in Laptop Science Engineering with a specialization in Synthetic Intelligence and Machine Studying.
She is a Knowledge Science fanatic with good analytical and demanding pondering, together with an ardent curiosity in buying new abilities, main teams, and managing work in an organized method.
[ad_2]
Source link
